I’ve been working on the longer-term implications of generative AI on product teams, and especially since “A Vision for Product Teams” made the rounds, I’ve had many meaningful conversations with leaders and practitioners about the consequences and second-order effects of generative AI. Through these discussions, one thing I’ve learned is that when it comes to product teams, there’s no one-size-fits-all playbook—autonomy only works when it’s matched with clarity of strategy, measurable outcomes, and explicit guardrails.
In practice, that means generative AI doesn’t replace product judgment; it accelerates learning loops. When teams can quickly prototype ideas, summarize research, and simulate user flows, they gain speed. But speed without direction amplifies noise. The teams that benefit most from AI pair autonomy with a crisp product strategy, a clear definition of success, and strong alignment on customer value.
Team autonomy in the AI era means owning problems, not features. Cross-functional squads should be accountable to outcomes, with the freedom to choose tactics—human-centered design, data-informed decisions, and responsible AI practices. Autonomy thrives when teams understand the company narrative, the strategic constraints, and the ethical boundaries that protect customers and the business.
The most underestimated shifts are the second-order effects. As AI reduces the cost of ideation and validation, teams can move faster with smaller surfaces—but the risk of local optimization increases. Without a unifying product strategy, shared data foundations, and platform standards, autonomy fragments the user experience. The solution is not to centralize decisions, but to centralize intent: common objectives, consistent metrics, and reusable capabilities that teams can compose.
Discovery also evolves. Generative AI can help synthesize qualitative feedback at scale, draft experiment variants, and stress-test hypotheses. I encourage teams to treat AI as an assistant for product discovery—use it to explore breadth, then validate depth with customers. Rapid prototyping is more powerful when tied to clear hypotheses, structured experiments, and tight feedback loops.
The role of product management expands from roadmap stewardship to system design. I focus my teams on framing problems, defining outcomes, and setting the rules of engagement: data access policies, model selection criteria, human-in-the-loop checkpoints, and standards for explainability. When we make these guardrails explicit, engineers and designers can move faster with confidence, and leaders can trust the results.
Operationally, I’ve found a few practices to be especially effective: outcome-based roadmaps instead of feature lists; a shared experimentation platform; golden datasets with clear provenance; evaluation rubrics for model quality; and policies for privacy, security, and bias mitigation. These enable autonomy at the edges while maintaining coherence at the core.
Adoption should be staged. Start with internal workflows and low-risk use cases, instrument everything, and expand as confidence grows. Celebrate wins that compound—shorter discovery cycles, better customer insights, and higher-quality decisions—not just raw automation. The goal is augmented teams, not automated teams.
Day to day, I ask teams to make their thinking legible. Treat prompts, hypotheses, and decision logs as living artifacts. When assumptions, constraints, and outcomes are explicit, autonomy scales. And when AI helps us reason faster and see farther, we can reserve human judgment for the choices that truly matter.
My takeaway: generative AI is a force multiplier for autonomous product teams that align on strategy, instrument outcomes, and operate with clear guardrails. Give teams ownership of problems, equip them with responsible AI practices, and hold them accountable to customer and business impact. That’s how we turn speed into sustainable progress.
In the Generative AI era, I keep returning to the enduring playbooks that shape great product teams. INSPIRED remains a cornerstone for how I coach on product discovery, product operating models, and product management leadership. I’ve used its principles to align cross-functional squads, empower product creators, and accelerate product-market fit lessons across both startups and scaled organizations.
The book INSPIRED is available in hardcover, digital, and audio versions, but until now, the audio version was only available in an exclusive arrangement with Amazon, on audible.com. The audio versions of our other books have been available from all major audio book providers. The exclusive contract with Amazon has now expired, and…
Why this matters: when knowledge moves beyond a single platform, more of our teams can absorb it in the flow of work. Distributed PMs, designers, data scientists, and forward deployed engineers can learn on their preferred apps during commutes or deep work breaks. That accessibility compounds learning velocity—especially when we’re iterating weekly on discovery insights, opportunity assessments, and bet selection.
What’s changed in our craft is the tooling: gen ai now augments how we validate assumptions, run product discovery, and prototype. Pairing the timeless practices in INSPIRED with gen ai for product prototyping helps my teams get to evidence faster—turning ambiguous narratives into testable artifacts, instrumented experiments, and real customer signals. It also sharpens our product operating model by making continuous discovery the default behavior across the product team.
Here’s how I operationalize this shift: I anchor a short “learning sprint” around one chapter at a time, then immediately translate insights into a concrete discovery activity (problem framing, assumption mapping, or opportunity sizing). We run a gen ai prototyping spike to visualize flows, draft UX copy, and simulate edge cases, followed by quick customer sessions to validate usefulness and usability. We capture outcomes in a working taxonomy of product-market fit lessons and update our decision logs so learning compounds sprint over sprint.
This is also a practical boost for enablement: new hires, customer support leaders crafting a customer support ai strategy, and forward deployed engineers can now engage with the same source material on their own schedules. When the whole team shares a common vocabulary—shaped by proven practices and accelerated by gen ai—the quality of debate improves, discovery cycles compress, and execution becomes more predictable.
If you’ve been meaning to revisit INSPIRED, this is an ideal moment. With access broadening, pick the format that fits your routine and turn insights into action the same day. Use it to pressure-test your product operating model, refine your discovery cadence, and elevate product management leadership across the organization. The combination of timeless principles and modern gen ai tools is exactly what our product teams need right now.
How do you build an AI-powered assistant that teachers will actually use?
As a VP of Product Management who ships AI features to real users, I’ve learned that the answer starts with deep empathy and ends with disciplined engineering. I recently dug into a compelling case study of K–5 edtech, where a team with more than a decade of experience building adaptive learning tools launched an AI-powered Teacher Assistant to help educators align supplemental lessons with district-mandated core curricula. The result is a practical blueprint for product leaders navigating gen AI in high-stakes environments.
In this episode of Just Now Possible, Teresa Torres talks with Thom van der Doef (Principal Product Designer), Mary Gurley (Director of Learning Design & Product Manager), and Ray Lyons (VP of Product & Engineering) from eSpark. Listening through a product lens, I focused on what translated from vision to value in busy classrooms—and why some early instincts (like a chatbot-first UI) didn’t survive contact with reality.
Listen to this episode on: Spotify | Apple Podcasts
Here’s what stood out to me. Post-COVID shifts in education created new pressures for teachers and administrators, amplifying the gap between top-down mandates and classroom realities. The team’s first instinct—a chatbot interface—failed in testing, and what ultimately worked was a more structured workflow that mapped to how teachers actually plan, select, and assign lessons. That’s a timeless product discovery lesson: meet users where they are, especially when their cognitive load is already maxed.
On the technical side, their first RAG system surfaced all the usual suspects—and all the usual surprises. The team had to learn to wrangle embeddings, debug semantic search vs. keyword search, and tune retrieval to the nuance of curricula, standards, and lesson objectives. As someone who has shipped RAG-backed features, I appreciate how much of the work happens in the unglamorous middle: data quality, ontology decisions, metadata hygiene, and evaluation strategy.
Speaking of evaluation, their background in education shaped a surprisingly rigorous eval process, long before “evals” became a buzzword. They leaned on rubrics, Braintrust, and a human-in-the-loop approach to ensure the assistant’s recommendations were accurate, aligned, and classroom-ready. It’s a reminder that in domains like education and healthcare, model observability and structured evaluation are non-negotiable for product-market fit.
The most energizing signal for me: they’ve learned from thousands of teachers using the product this school year—and they’re already translating that learning into roadmap bets. What’s next for Teacher Assistant: more contextual recommendations using student data. Done well, that shift moves the product from “helpful” to “indispensable,” grounding gen AI in student outcomes rather than generic assistance.
Show notes for context: Guests include Thom van der Doef, Principal Product Designer at eSpark; Mary [last name], Director of Learning Design & Product Manager at eSpark; and Ray Lyons, VP of Product & Engineering at eSpark. Topics covered span the origin story of Teacher Assistant (connecting administrator mandates with teacher needs), why the team abandoned a chatbot interface in favor of a more structured workflow, how retrieval augmented generation (RAG) and embeddings shaped the product architecture, lessons learned from debugging semantic search vs. keyword search, building evals with rubrics, Braintrust, and a human-in-the-loop approach, and what’s next for Teacher Assistant: more contextual recommendations using student data.
If you like to follow along chronologically, the chapter flow is tight and practical: 02:05 Overview of Epar's Adaptive Learning Program; 07:19 Challenges and Insights from COVID-19; 17:06 Developing the Teacher Assistant Feature; 24:55 User Experience and Interface Evolution; 34:29 Chat GPT-5's New Features; 35:16 Balancing Engagement and Efficiency; 35:40 Seasonal Business and Real Traffic; 36:29 Technical Decisions and RAG Implementation; 38:28 Challenges with Embeddings and Metadata; 41:24 Improving Recommendations and Data Enrichment; 55:18 Evaluating the Teaching Assistant; 01:05:51 Future Plans and User Feedback; 01:07:57 Conclusion and Final Thoughts.
Useful links if you want to go deeper: eSpark Learning; Braintrust.dev – evals and observability for LLM applications; AI Evals Maven Course by Hamel Husain and Shreya Shanker.
My product takeaways for anyone building AI in complex, regulated, or mission-driven domains: First, resist the chatbot reflex; many users need structured, high-signal workflows. Second, treat retrieval as a product surface—data modeling, metadata, and domain language matter as much as model choice. Third, invest early in evals with rubric-based scoring and human-in-the-loop reviews to protect trust. Finally, plan for seasonality and “real traffic” patterns; the strongest eval is usage in production with tight feedback loops from your most demanding users.
Gen AI is only as valuable as the outcomes it enables. In classrooms, that means saving teachers time, raising instructional alignment, and ultimately improving student learning. This case study shows that when we combine empathetic product discovery with disciplined RAG architecture and rigorous evals, AI stops being a demo—and starts being a difference-maker.
I’ve been leaning hard into AI as a strategic thought partner, not a shortcut—and this episode captured exactly why. Listening to Teresa Torres and Petra Wille explore how AI sharpens writing, coding, and product decision-making felt like a mirror of what I’m seeing on real teams: when we treat AI as a collaborator, we unlock quality, speed, and clearer thinking without sacrificing our voice or product judgment.
If you want to dive in, listen on Spotify or Apple Podcasts. There’s also a YouTube version here: watch the episode.
Two themes stood out immediately. First, Petra’s voice-first workflow and how she uses AI to mine her own archive for consistency is a brilliant approach to preserving authorial intent while scaling content creation. Second, Teresa’s claim that “Claude Code in the terminal completely changed her workflow—from planning mode for coding projects to using reviewer “sub-agents” when drafting blog posts” maps closely to how I’ve reshaped my own product and engineering cadence.
On Petra’s side, the combination of voice input and bilingual transcription isn’t just a convenience—it’s a cognitive unlock. By capturing high-fidelity thinking in real time and surfacing relevant prior material, AI becomes a continuity engine for product discovery and leadership communications. I’ve applied a similar pattern for product briefings and executive updates: record voice notes, let AI surface connected fragments from prior docs, and then reconcile differences to maintain a single, coherent narrative over time. Tools like WisprFlow make this feel natural rather than mechanical.
Teresa’s setup with Claude Code resonated as well: planning mode, context from local files, and project planning before writing code is exactly how I prefer to work with engineers and forward deployed engineers. Bringing in local context—sometimes via RAG (retrieval-augmented generation) or MCP (Model Context Protocol)—keeps the assistant grounded in the reality of our repositories and docs. In my experience, that pre-work pays off with cleaner interfaces, tighter tests, and faster reviews when we shift from ideation to implementation.
The framing that matters most to me: using AI as an editor and reviewer rather than as a ghostwriter. I still write every word myself, but I rely on structured critique to reduce blind spots. Creating sub-agents (copy editor, skeptic, devil’s advocate) to critique drafts mirrors how strong product teams stress-test PRDs, strategy docs, and UX copy. When I need a deeper critique, I’ll even spin up dedicated Subagents to review assumptions, risk, and edge cases.
One practical takeaway you can apply immediately: pair models for complementary strengths. How ChatGPT and Claude differ in strengths (structure vs. tone) is a pattern I see daily in gen ai for product prototyping. I often draft structured scaffolds or test plans in ChatGPT, then refine tone, clarity, and nuance in Claude. For “vibe coding” experiments in Python or Node.js, I’ll start in planning mode with Claude Code, anchor on tests and interfaces, and only then move into implementation.
The UX implications are profound. The shift toward personal agents as the interface for products accelerates a world where English becomes the interface for everything we do. That means our information architecture must increasingly be legible to agents, not just humans. It also means onboarding, accessibility, and error recovery will be mediated through conversational patterns, not just screens. For product management leadership, this demands new standards for observability, prompt governance, and cross-model evaluation—core ingredients for trustworthy AI strategy.
If you’re mapping this to your roadmap, here’s how I’d operationalize it: treat AI as a strategic thought partner in product discovery; define explicit roles for sub-agents in reviews; codify planning mode as a precondition to writing code; and document model choices (structure vs. tone) so your team knows when to use what. This is how we turn gen ai into durable product-market fit lessons rather than sporadic wins.
Resources and links mentioned or relevant to the workflows discussed: ChatGPT, Claude & Claude Code (Anthropic), WisprFlow, Vibe coding, Python, Node.js, RAG (retrieval-augmented generation), MCP (Model Context Protocol), agents and workflows, and Subagents.
I’d love to hear how you’re deploying AI in your own stack. What’s working in your editor-and-reviewer setup? Which combinations of models are giving you leverage? Drop your thoughts below—let’s compare notes and sharpen our collective practice as product creators.
How do you know if your AI product is actually any good? As someone who ships AI features at scale, I ask myself that question daily. Listening to Hamel Husain unpack the craft of error analysis and evaluation reinforced what I’ve learned in the trenches: reliability isn’t an accident—it’s the result of a disciplined, scientific approach to debugging AI products.
Hamel’s background spans over 25 years across machine learning and data science, including impactful work at Airbnb and GitHub that paved the way for GitHub Copilot. What stood out to me was how methodical his approach is: define the problem crisply, isolate failure modes, measure what matters, and iterate with intention. That’s the same operating rhythm I expect from our teams when we evaluate AI features.
Here are the core themes I took to heart, preserved in the language discussed: “Why debugging AI starts with thinking like a scientist”; “How data leakage undermines models (and how to spot it)”; “Using synthetic data to stress-test failure modes”; “When to rely on code-based assertions vs. LLM-as-judge evals”; “Why your CI/CD set should always include broken cases”; “How to prioritize failure modes without drowning in them.” Each of these mirrors how I build evaluation pipelines and keep them honest over time.
On data leakage, I’ve learned to be ruthless. If your splits aren’t rock-solid, your metrics are fantasy. We harden our pipelines with explicit checks for leakage, treat feature provenance like a first-class citizen, and maintain immutable holdout sets. When I hear teams celebrate sudden metric jumps, my first question is: did leakage just sneak in?
I also appreciated the practical contrasts between code-based assertions and LLM-as-judge evals. My rule of thumb: use code-based assertions for deterministic criteria (formatting, schema, presence/absence of required elements) and LLM-as-judge when the outcome is semantic, subjective, or requires pragmatic grading of quality. In production, I rely on both—code for guardrails, LLM judges for nuance—backed by calibration, adjudication, and spot checks to prevent drift.
Synthetic data is another cornerstone. “Using synthetic data to stress-test failure modes” resonates because real-world logs rarely cover the long tail. We generate targeted scenarios to probe brittleness—adversarial prompts, multilingual edge cases, domain shifts—and keep these in a living eval suite. The goal isn’t just to pass tests; it’s to anticipate what reality will throw at you tomorrow.
The conversation traces a journey from forecasting guest lifetime value at Airbnb to hands-on consulting with startups like Nurture Boss, an AI-native assistant for apartment complexes. That arc mirrors what I’ve seen: use case clarity, grounded datasets, and tight feedback loops beat model hype every time. The example of text message errors was particularly relatable—production messaging demands precise intent, tone, compliance, and context. If you can’t evaluate those consistently, you can’t scale them safely.
Prioritization is where many teams drown. I score failure modes by severity (user harm or business impact), frequency (how often it appears), and confidence (how certain we are in the eval). High-severity issues that repeat—even at moderate frequency—get fast-tracked. Everything lives in a persistent log: what failed, why it failed, how we measured it, what we tried, and the before/after metrics. This log becomes the backbone of continuous improvement, not a graveyard of JIRA tickets.
To avoid overfitting to the eval suite, I rotate holdouts, refresh cohorts, and introduce blind sets from time to time. We regularly audit LLM-as-judge consistency and anchor grading with a handful of human-reviewed exemplars. When metrics move, we validate that we improved real outcomes, not just our test set. If you can’t trust your evals, you can’t trust your roadmap.
Here’s the playbook I use and recommend: define success criteria aligned to user value; construct a minimal, repeatable eval harness; seed it with real-world failures and “always include broken cases” in CI/CD; add code-based assertions for hard constraints; layer LLM-as-judge for quality judgments; generate synthetic edge cases to widen coverage; and report results in language business stakeholders understand. Do this, and you’ll not only ship better AI—you’ll ship with conviction.
If you want to dive deeper into the specific products and methods referenced, explore these: GitHub Copilot, forecasting AirBnB Guest Growth, and NurtureBoss. Each illustrates different angles of error analysis, measurement, and iteration in the wild.
Listen to the full conversation here: Spotify | Apple Podcasts. For further study, I recommend: Hamel’s blog on AI evals and the AI Evals for Engineers and PMs course on Maven.
Building robust AI isn’t about perfection; it’s about disciplined progress. Think like a scientist, treat failure modes as assets, and let your evals guide the roadmap. That’s how you transform anxiety about AI quality into a durable advantage.
I recently tuned into a powerful conversation where Petra Wille sits down with Teresa Torres to unpack a major shift in product learning: moving from purely instructor-led cohort courses to offering on-demand options. As someone leading product management at HighLevel, I’ve wrestled with the same trade-offs—how to scale product discovery skills without compromising depth, community, or outcomes—and this discussion hit home.
What stood out immediately is how Teresa shares why she resisted on-demand for so long, how deliberate practice has always been at the heart of her teaching, and what finally changed her mind. That framing matters. In my experience, deliberate practice is the backbone of real capability building: clear goals, targeted reps, tight feedback loops, and sustained reflection. It’s how we turn continuous discovery from a concept into a craft product teams can reliably execute.
We also dug into the trade-offs between cohort-based vs. on-demand learning. Cohorts bring structure, accountability, and shared language—critical for team-based behavior change. On-demand learning offers flexibility, reach, and just-in-time reinforcement—key for busy product managers, designers, and engineers balancing roadmaps and research. The challenge is not choosing one over the other, but architecting a blended learning system that preserves the rigor of cohorts while using on-demand to extend practice, sustain momentum, and meet learners where they are.
That’s where technology becomes a force multiplier. From AI-powered interview coaches to microlearning formats, we explored how AI can support behavior change and skill building without losing the human element. I’ve seen the same in my teams: when AI provides structured, rubric-based feedback on interviews, assumptions, or opportunity framing, people get expert-quality guidance at scale. Used well, this shortens the feedback cycle and increases the number of high-quality reps—without displacing peer critique or expert coaching.
Microlearning and problem sets deserve special attention. Short, focused practice—think “Duolingo” for product discovery—helps teams internalize patterns like crafting unbiased interview prompts, distinguishing signals from stories, or iterating on interview flow. Combined with spaced repetition, these formats build muscle memory for critical skills, so discovery doesn’t stall the moment the cohort ends. In other words, on-demand isn’t a downgrade; with the right scaffolding, it can be a durability upgrade.
Equally important, why AI should augment—not replace—human connection in discovery. No model can substitute for the trust you build with customers, the judgment you develop through messy real-world conversations, or the creative tension of team debate. My takeaway: use AI to accelerate preparation, evaluation, and deliberate practice; rely on humans for empathy, ethics, sense-making, and decision quality.
If you’ve ever wondered how to balance flexibility, structure, and deliberate practice in product learning—or you’re just curious how AI might reshape how we build skills—this conversation is for you.
Listen to this episode on: Spotify | Apple Podcasts
Explore the resources and links mentioned: Follow Teresa Torres: https://ProductTalk.org; Follow Petra Wille: https://Petra-Wille.com; Product Talk Academy; Continuous Interviewing course by Teresa Torres; Story-Based Customer Interviews On Demand course by Teresa; Customer Recruiting for Continuous Discovery On Demand course by Teresa; Duolingo; Teresa’s Interview Coach; AI as a Strategic Thought Partner with UX Implications podcast episode; Teresa’s socials: X, LinkedIn, Youtube, Product Talk Blog.
I’d love to hear your perspective. How are you blending cohort-based learning, on-demand practice, and AI coaching on your product teams? Drop your thoughts in the comments—let’s compare notes on what’s working.
Continuous customer interviews can overwhelm even seasoned product teams. I see it all the time: we commit to weekly conversations, transcripts pile up, and synthesis slips down the priority stack.
When I interview every week, the data builds quickly. Hours of transcripts accumulate, and if I don’t synthesize as I go, I fall behind. I’ve heard countless teams say, "We need to stop interviewing so we can catch up on what we’ve already learned." That’s a red flag—many teams pause and never restart.
I get why this happens. Interview synthesis is cognitively demanding and time-consuming. That’s why so many teams reach for generative AI to help. I use AI a lot—but I’m also careful about where it helps and where it hurts.
Before I explain how I use AI in practice, I want to ground us in the goal of continuous interviewing, why story-based interviews matter, and what good synthesis looks like. With that foundation, it’s much easier to see how AI can accelerate the right work without undermining our judgment, empathy, or product discovery skills.
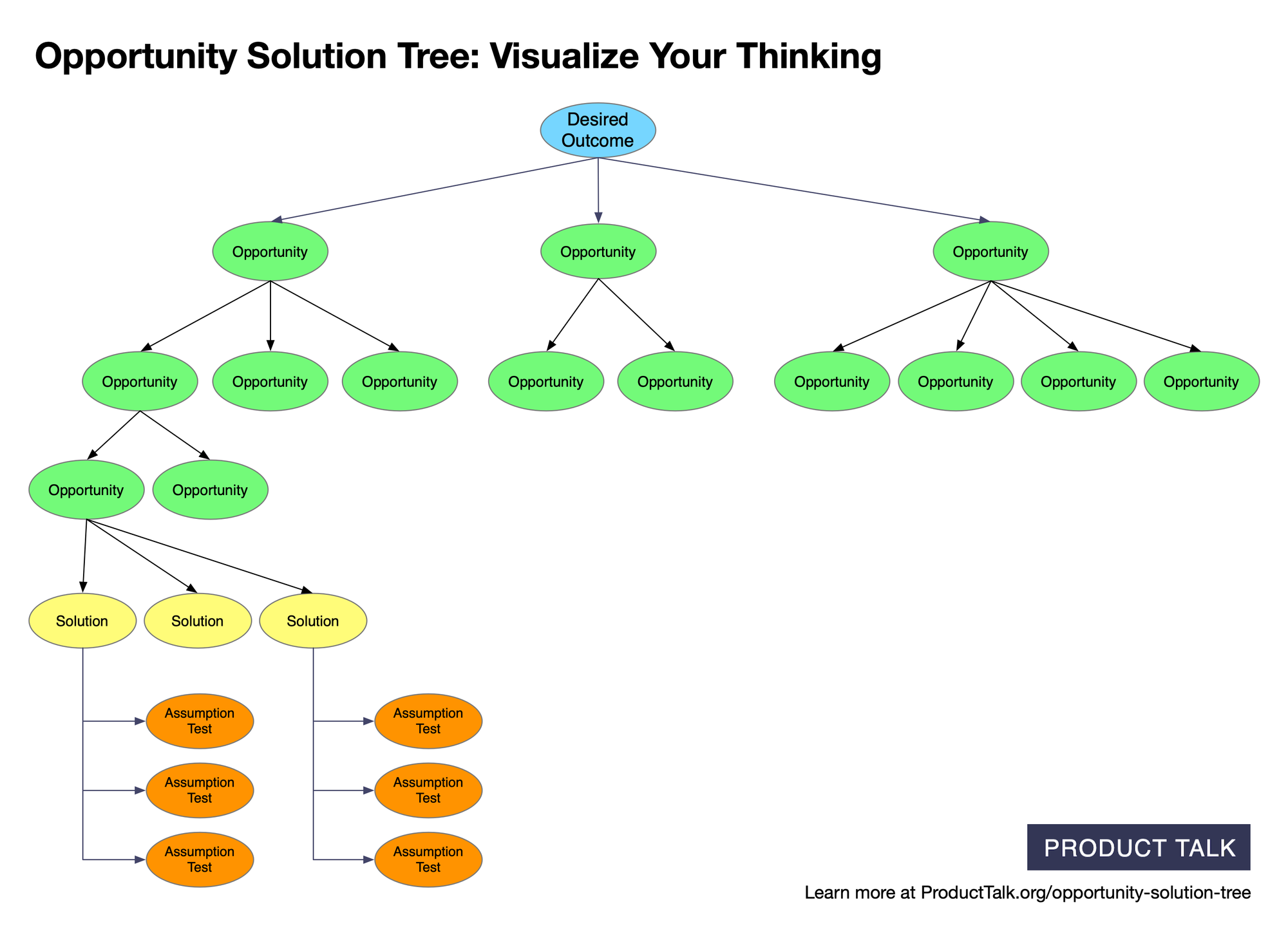
See how customer insights ladder to a desired outcome: opportunities branch into sub-opportunities, leading to solutions and assumption tests—where AI can speed analysis, but humans decide what to pursue.
The goal of continuous interviewing is to develop a deep and rich understanding of who our customers are, what their goals are, the context in which they pursue those goals, and what opportunities (needs, pain points, and desires) arise along the way. I get there by asking for specific stories about past behavior. Goals, context, and opportunities emerge from those stories.
My flow is simple and disciplined: I synthesize each story using an interview snapshot, then I synthesize across stories by mapping the opportunity space in an opportunity solution tree. Habits vary, but in my experience this approach consistently yields actionable insights and keeps the team anchored in real customer context.
There’s a prerequisite almost nobody talks about: you need deep, rich stories. Many teams haven’t invested in interviewing skill. They ask hypothetical questions about the future (e.g., "Would you use this?") or spend precious interview time seeking solution feedback instead of learning about the customer’s world.
A clean, brand-neutral tile with a bold letter P signals a focus on product insights, introducing a deep dive into where AI speeds up customer interview analysis—and where it adds friction, bias, and preventable errors.
Even when teams ask about goals, context, and needs, they often ask in the abstract (e.g., "How do you decide what to watch?") or speculate (e.g., "What do you typically watch?"). That leads to unreliable feedback. When teams do ask for past stories, they often collect shallow narratives because they haven’t honed their craft to probe for detail and meaning.
Here’s the crux: if you aren’t good at collecting a rich story about past behavior, no amount of AI synthesis can help you. AI can’t add missing context. It can’t infer missing goals and motivations. It can’t create actionable opportunities from shallow stories. This is also why humans struggle to synthesize weak interviews. Better interviewing unlocks better synthesis—human or AI.
Once I have strong stories, I synthesize in two steps. First, I synthesize what I learned from each interview. Second, I synthesize what I’m learning across interviews. That separation matters.
For single-interview synthesis, I use interview snapshots. Each snapshot includes quick facts to contextualize the story, a memorable quote, an experience map of key moments, and—most importantly—a list of opportunities expressed in the customer’s own context. This keeps insights actionable and traceable.
When I synthesize across interviews, I review multiple interview snapshots to ask: what are we learning that can help us reach our desired outcome? Key moments give structure to the opportunity space, and the specific unmet needs, pain points, and desires help me see where our product can meaningfully help. With this foundation, I can reason clearly about where AI helps—and where it hurts.
Where do teams go wrong with AI synthesis? The biggest mistake I see is combining the two synthesis steps into one. Teams dump all their transcripts into an AI workspace or NotebookLM and ask the model to “tell us what we learned.” The second error is using low-quality prompts: asking for a summary, themes, or common pain points. Those outputs are easy to read but rarely actionable.
Product Talk’s Customer Interview Snapshot shows a concise way to document research—capturing a quote, quick facts, insights, opportunities, and an experience map—handy when comparing AI and human analysis.
If I learn the three most common pain points across interviews but don’t know who experienced them or in what context, I can’t design effective solutions. The interview snapshot is designed to avoid that trap by preserving opportunities within the customer’s story and context, tied to a real person. That link is critical for validation and iteration.
Summaries, in particular, are problematic. If you condense a 20–30 minute interview into a paragraph or two, you’ll lose the context, nuance, and detail that makes that customer story unique. One study found that large language models "frequently generated summaries that oversimplified or omitted critical details." Another study found that models struggle to "adequately represent the deep meaning" when summarizing text.
Bias is another concern. Pre-training data can shape outputs in ways that distort meaning. The first study found that pre-training data "introduced biases that affected summarization outputs" and that models often "defaulted to generalizations or inaccuracies." Hallucinations also show up in summaries, theme extraction, and even fabricated direct quotes. I’ve seen this first-hand: when I tested ChatGPT on real interviews, a surprising share of “quotes” were inaccurate or invented.
AI can speed up interview analysis, but this visual shows where it falters: weak prompts, shallow or inaccurate summaries, lost nuance, bias, and missing tone and body language. Use it to check your synthesis process.
There’s also a context gap. Synthesizing an interview well often requires business, product, and customer context to correctly interpret what was said. Unless we provide that context deliberately, the AI doesn’t have what it needs. Finally, most AI synthesis works off text only, missing tone of voice and body language—both of which can materially change meaning.
Despite those risks, I don’t avoid AI—far from it. I use it deliberately in three ways that consistently add value without eroding empathy or skill.
First, AI as a notetaker. AI transcription is excellent and essentially free. I often add structured metadata—date, participant, role, company, topics—so my transcripts are easy to search. Tools like Granola can organize notes, but I always verify those notes against the transcript to avoid subtle misreads.
AI can accelerate customer interview analysis, but this slide highlights the trade‑offs: diminished empathy, weaker pattern recognition, eroding synthesis skills, loss of quality feedback loops, and insights that are harder to act on.
Second, AI as a fresh perspective. In my product trio, each of us synthesizes the interview separately before we discuss. I then add AI as an additional perspective by running the same material through carefully configured Claude and ChatGPT spaces that have the right research context and synthesis instructions. Because I’ve already done my own synthesis, I can evaluate the model’s output, borrow useful frames, and catch anything I might have missed—without outsourcing my judgment.
Here’s the workflow I rely on for using AI as a fresh perspective: I set up a dedicated, persistent space (a Project or equivalent) for synthesis. I define the right context up front—ideal customer profile, current outcome, target opportunity, research questions, and short instructions on how to do each step. I keep single-interview synthesis and cross-interview synthesis separate, using new conversations to prevent context rot. I treat AI as another teammate—not the source of truth. And when AI surfaces opportunities I didn’t capture, I go back to the source to verify.
In practice, Claude (via Projects or Claude Code) is excellent for collaborative synthesis and handling long transcripts. ChatGPT (via CustomGPTs or Projects) offers a complementary perspective, and I’ll often run the same material through both. Granola helps with note organization, provided I review its outputs before using them. One caution: many “interview analysis” tools skip single-interview synthesis and jump straight to patterning—don’t let that happen. Do step one before step two.
A minimalist visual explains three practical roles for AI in customer interview analysis—note-taker, fresh perspective, and synthesis teacher—set in clean typography with Product Talk branding and teal accents.
Third, AI as a customer synthesis teacher. Synthesis is a skill. AI can suggest alternative opportunity framings, propose interpretations of the same passage, and flag when an “opportunity” is really a solution in disguise. I’ve had strong results using AI as a thought partner and coach, especially when I’m deliberate about what good looks like and I verify everything against source material.
There’s an important human dimension to all of this. When I do the deep work of synthesis, I develop empathy for customers. Creating an interview snapshot forces me to ask: What happened? What did we really hear? How can we help? That cognitive effort is what unlocks both empathy and pattern recognition. If I outsource that work to AI, I lose both the learning and the mental connections that fuel better decisions.
There’s another risk: skill atrophy. If I let AI do the synthesis, my ability to synthesize degrades—and that makes me worse at evaluating AI’s output. Two recent studies (see here and here) found that experts are much better than novices at catching the subtle mistakes LLMs tend to make. So if we don’t keep our edge, we not only lose skill—we also get less value from AI.
Clean, modern title card for a post exploring where AI helps and hurts in customer interview analysis. The prompt-centered design in teal and navy, paired with a Product Talk tag, teases insights on faster, smarter interview synthesis.
A final benefit of doing the work yourself: when I revisit transcripts, I see my own interviewing gaps. I spot missed follow-ups, leading questions, or places I misread what was said. Synthesis becomes a feedback loop that improves my interviewing craft. If I outsource synthesis, I sever that loop.
Can AI help humans do better synthesis, faster? The research is encouraging. Those same two studies found that AI can raise the performance of novices. But they also show that experts working with AI perform best. In my experience, the sweet spot is expert human synthesis aided by AI—fast enough to keep pace, rigorous enough to build empathy and insight.
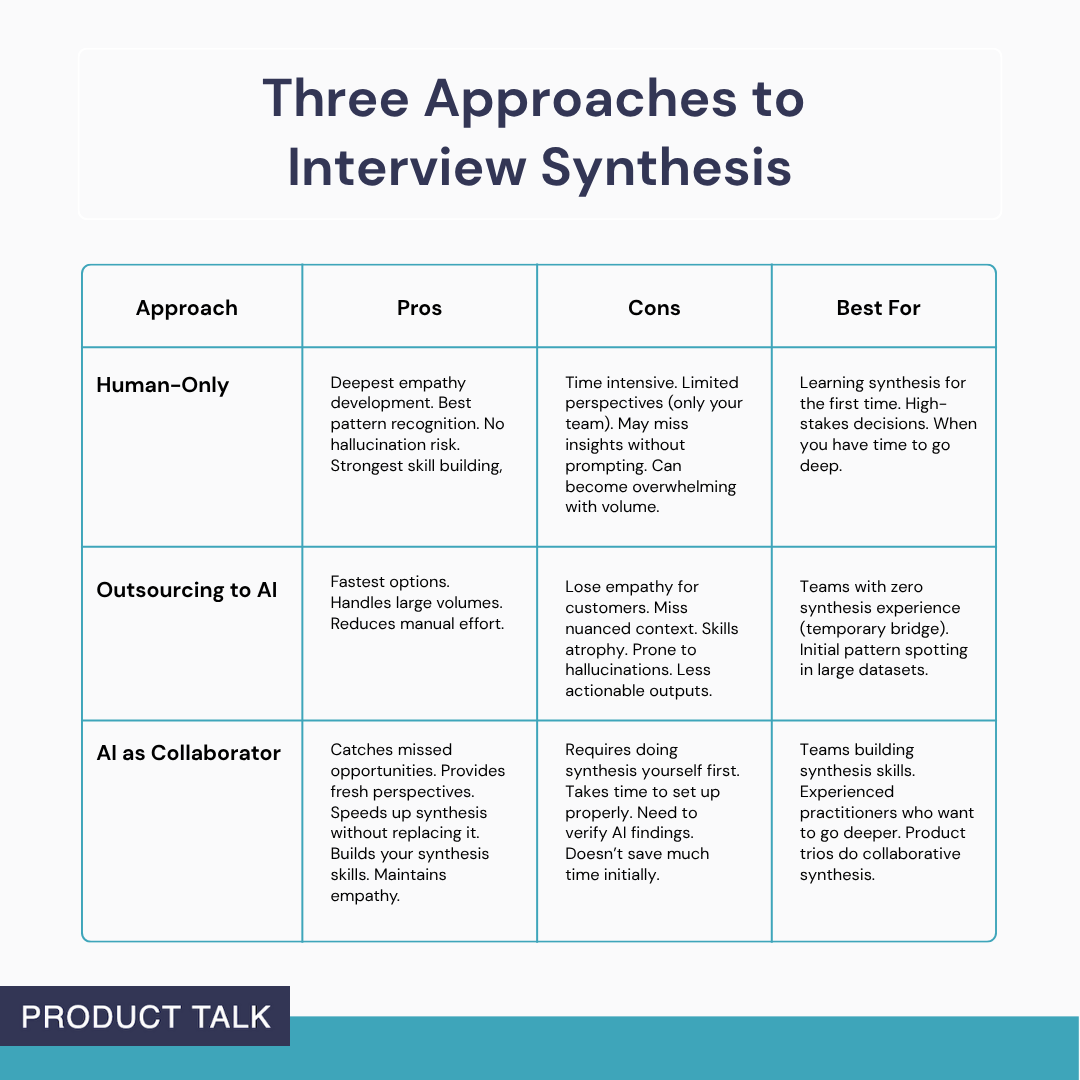
Practically, there are three approaches to interview synthesis. Human-only is the deepest path to empathy and pattern recognition, with no hallucination risk and maximum skill-building—but it’s time-intensive and can be overwhelming at scale. Outsourcing to AI is the fastest and handles volume well, but you risk losing context and empathy, your skills can atrophy, and outputs are often less actionable. AI as collaborator sits in the middle: it catches missed opportunities, adds fresh perspectives, speeds up work without replacing it, and strengthens your synthesis muscles—provided you do your own synthesis first and verify AI’s contributions.
My recommendation is simple. Start with human-only synthesis until you can recognize what good looks like. Then bring in AI as a collaborator once you can evaluate the quality of its output. Only outsource to AI if you’re genuinely blocked and need a temporary bridge—and if you do, plan to build your synthesis muscle alongside it.
So what does AI as a collaborator look like day to day? It looks like tight loops: rigorous single-interview synthesis by each member of the product trio, a second pass with AI configured to your outcome, ICP, and target opportunities, careful verification back to the transcript, and only then cross-interview synthesis that maps the opportunity space. That cadence preserves empathy, sharpens judgment, and gives you the speed benefits of AI without sacrificing what makes product discovery work.
Bottom line: use AI to accelerate clarity, not to replace the human judgment that drives product management leadership. When we protect empathy, preserve context, and practice disciplined synthesis, generative AI becomes a powerful amplifier for product discovery—not a shortcut that dulls our edge.
I’ve been deep in the work of building practical, agentic capabilities into AI products, so this story about Alyx immediately resonated with me. It’s a rare, clear-eyed look at what it actually takes to ship a useful AI agent inside an AI platform—while using that same platform to build, test, and continuously improve the agent.
What does it really take to build an AI agent inside an AI platform—especially when you’re using that same platform to build the agent?
Listening to SallyAnn DeLucia (Director of Product at Arize) and Jack Zhou (Staff Engineer at Arize) unpack Alyx—the AI agent that helps teams debug, optimize, and evaluate AI applications—I recognized playbooks I trust: start scrappy, dogfood relentlessly, build intuition with real users, and systematize improvement with thoughtful evals.
Their early phase looked exactly like the messy reality many of us try to hide: Jupyter notebooks, hacked-together web apps, and weekly dogfooding sessions with their customer success team. That’s where patterns emerged, confidence was built, and the highest-leverage skills for the agent were prioritized. It’s a reminder that “vibe checks” matter at first—but you must quickly graduate to measurable, repeatable learning loops.
In my experience, the foundation of GenAI product quality is threefold: tracing, observability, and evals. They reached the same conclusion—defining traces across tool calls and sessions, creating observability into model behavior, and layering evals to compare both micro-decisions and system-level outcomes. That discipline converts hunches into evidence and makes agent behavior improvable, not mysterious.
What stood out was how cross-functional, boundary-spanning teams made the difference. Customer success engineers surfaced repeatable workflows. Product framed early skills. Engineering wrapped prototype tools into something coherent. Using their own platform to build Alyx accelerated intuition and de-risked launch. That’s the product loop I aim to cultivate: close to customers, close to data, and fast to learn.
As Alyx matures, the next step is moving from “on rails” workflows to more autonomous, agentic planning loops. That evolution requires stronger tool design, richer feedback signals, and evals that reflect end-to-end user value. It’s exactly the shift I expect across GenAI: from scripted assistants to adaptive systems that reason, plan, and act with guardrails.
Listen to this episode on: Spotify | Apple Podcasts
Guests:
SallyAnn DeLucia, Director of Product, Arize
Jack Zhou, Staff Engineer, Arize
In this episode, we cover:
What tracing, observability, and evals really mean in GenAI applications
How Arize used its own platform to build Alyx, its AI agent
The role of customer success engineers in surfacing repeatable workflows
Why early prototyping looked like messy notebooks and hacked-together local apps
How dogfooding shaped Alyx’s evolution and built confidence for launch
Why evals start messy, and how Arize layered evals across tool calls, sessions, and system-level decisions
The importance of cross-functional, boundary-spanning teams in building AI products
What’s next for Alyx: moving from “on rails” workflows to more autonomous, agentic planning loops
My takeaways for product teams building GenAI agents are simple and hard: design tools with observability in mind; operationalize evals early even if they’re imperfect; embed customer-facing engineers in the loop to capture real workflows; and keep the first skills narrow, high-impact, and testable. If your team can move from demos to disciplined measurement quickly, you’ll accelerate product-market fit.
Resources & Links
Arize AI — Sign up for a free account and try Alex
Arize Blog — Lessons learned from building AI products
Maven AI Evals Course — The course Teresa took to learn about evals (Get 35% off with Teresa’s affiliate link)
Cursor — The AI-powered code editor used by the Arize engineering team
DataDog — For understanding application traces
OpenAI GPT Models — GPT-3.5, GPT-4, and newer models used in early and current versions of Alex
Jupyter Notebooks — A tool for combining code, data, and notes, used in Arise’s prototyping
Axial Coding Method by Hamel Husain — A framework for analyzing data and designing evals
Chapters
00:00 Introduction to Sally Ann and Jack
01:08 Overview of Arize.ai and Its Core Components
01:44 Deep Dive into Tracing, Observability, and Evals
03:56 Introduction to Alyx: Arize's AI Agent
04:15 The Genesis and Evolution of Alyx
08:51 Challenges and Solutions in Building Alyx
24:33 Prototyping and Early Development of Alyx
26:22 Exploring the Power of Coding Notebooks
26:51 Early Experiments with Alyx
27:59 Challenges with Real Data
29:20 Internal Testing and Dogfooding
31:55 The Importance of Evals
35:16 Developing Custom Evals
43:09 Future Plans for Alyx
47:59 How to Get Started with Alyx
Full Transcript
Podcast transcripts are only available to paid subscribers.
If you’re building in GenAI right now, this conversation offers a pragmatic blueprint. Start with high-signal workflows, turn qualitative insights into quantitative evals, and use tracing plus observability to make agents debuggable. That’s how scrappy prototypes become reliable systems. And if you want a tangible example, “47:59 How to Get Started with Alyx” is a helpful on-ramp.
What if my next teammate wasn’t a human hire but an AI coworker—one that can answer support tickets, process invoices, or draft emails—and my non-technical colleagues could teach it how to do those tasks themselves? That is the practical promise behind Neople’s “digital coworkers,” and it’s a shift I’ve been anticipating across customer support and operations: AI that blends the reliability of automation with the empathy and flexibility of modern agents.
Listen to this episode on: Spotify | Apple Podcasts
In exploring how Neople builds and deploys these agents, I appreciated the clarity from Seyna Diop (Chief Product Officer), Job Nijenhuis (CTO & Co-founder), and Christos C. (Lead Design Engineer). They walked through the evolution from simple response suggestions to fully autonomous customer service agents, the architecture powering their conversational workflow builder, and the evaluation loops that include customers as part of the quality process. As a product leader, this resonates deeply with how I approach product discovery, product management leadership, and go-to-market enablement for gen AI in customer support.
Moved from “LLMs will solve everything” to finding the right balance between code, agents, and guardrails
Designed evals that run in production to detect hallucinations before an email ever reaches a customer
Helped non-technical users build automations conversationally — and taught them decomposition along the way
Turned customers’ feedback loops into eval pipelines that improve product quality over time
From a customer support AI strategy standpoint, these choices are decisive. I’ve seen teams struggle when they lead with model horsepower rather than a layered system of retrieval, business logic, and guardrails. The Neople approach aligns with what I’ve practiced: set clear task boundaries, ground responses in trustworthy knowledge, and instrument every step so evals reflect real-world behaviors—not just lab benchmarks.
I also love the emphasis on conversational building for non-technical users. Teaching decomposition implicitly—by guiding users to break down tasks into steps—accelerates adoption and reduces support burden. It’s a practical onramp to gen ai for product prototyping: let users design flows in natural language, then progressively reveal structure, data dependencies, and edge cases as they iterate.
Scaling these agents “where you work” requires deep integrations and visibility. We discussed how the team makes agents feel native in existing tools, maintains “Visibility and Transparency in Neople Responses,” and keeps humans in the loop for sensitive workflows. That transparency is non-negotiable: if an AI is going to act on behalf of my team, I want traceable reasoning, source citations, and reversible actions.
Quality, of course, is where most agent initiatives rise or fall. Running evals in production, detecting hallucinations before messages reach customers, and converting feedback loops into continuous improvement pipelines—this is exactly how you earn trust at scale. It mirrors how I deploy forward deployed engineers with customers: ship intentional constraints, watch real usage, and feed structured signals back into the system to compound quality.
The roadmap beyond support is equally compelling. Once agents demonstrate reliability in high-volume, high-variance environments like customer support, adjacent functions—sales ops, finance ops, and onboarding—become reachable. That’s a credible path to product-market fit lessons: start where the pain is sharp and measurable, prove value with operational KPIs, then expand horizontally with guardrails intact.
For those who want to go deeper, the conversation spans the origin story and real-world applications, through “Integrations and Scaling: Making Neople Work Everywhere,” into techniques for “Ensuring Quality in Customer Knowledge Bases,” “Customer Feedback and Error Analysis,” and the “Technical Details of Knowledge Retrieval.” It also touches “Embedding Strategies and Document Types,” “Automation and Actions in Customer Support,” and “Expanding Beyond Customer Support.” It’s a comprehensive, pragmatic tour of what it takes to make AI coworkers production-ready.
Neople.io – Learn more about Neople’s AI coworkers
The Joy Lab – Neople’s community and podcast about AI and work
If you’re piloting agents today, my recommendations are straightforward: choose a single, high-impact use case; define guardrails and “safe failure” modes; stand up production evals that mirror customer outcomes; and make transparency a default. With that foundation, AI coworkers can become dependable teammates—ones your non-technical colleagues can actually work with, trust, and improve.
Product-market fit in the GenAI era is elusive because both the technology surface area and user expectations change weekly. That’s why Braintrust caught my eye: they set a relentless quality bar, delayed go-to-market on purpose, and used real-world evaluation pain to shape an end-to-end platform for building AI apps. In my work leading product management teams, I recognize this pattern as the difference between shipping demos and shipping durable value.
Context matters. Ankur Goyal’s journey runs through MemSQL (now SingleStore), Impira, and Figma. Working with high-bar users at MemSQL forged a bias toward precision, performance, and reliability—traits that translate directly to AI infrastructure where flaky evals and brittle prompts can quietly erode trust. When you build for exacting users early, the feedback loop is unforgiving—and that’s a gift.
The throughline is quality. Great software often comes from a place of “paranoia”—the productive kind that compels us to fail proofs, harden edge cases, and verify outcomes under load. In AI product development, that paranoia shows up as rigorous evals, clear data contracts, reproducibility, and measured rollouts. It’s not glamorous, but it’s how you earn compounding trust with builders and operators.
Recruiting is strategy. The trick to recruiting well is selecting for taste, curiosity, and ownership—people who elevate the craft and sweat the engineering details. In AI-heavy products, I’ve had the most success with forward deployed engineers who live with users long enough to discover the non-obvious constraints that should drive the roadmap. Taste plus proximity beats velocity without context.
Impulse control creates leverage. Braintrust delayed go-to-market, which is counterintuitive when the market is hot. But in a new category, premature scaling yields fake signals. The better move is to tighten the loop: instrument the “prompt playground,” pressure-test evals, validate the inner loop of building AI apps, and only then broaden access. When the core interaction is right, growth compounds; when it’s off, every feature feels like a workaround.
Figma-era frustrations with evals became the opportunity. Anyone who has tried to standardize AI evaluations across prompts, models, and datasets knows how quickly the surface area explodes. Converting that frustration into Braintrust’s product thesis—reliable, end-to-end workflows for AI app development—speaks to a classic product discovery principle: go deep on a painful, persistent job-to-be-done before you go broad.
How to recognize a real market opportunity: look for high-frequency workflows with measurable outcomes, teams who already duct-tape solutions, and buyers who have the budget and urgency to pull the product in. When you see repeatable pull from discerning users—and you can demonstrate quality with transparent evals—you’re approaching true PMF rather than narrative fit.
Inside the first six months, the right posture is deliberate focus. For a platform like Braintrust, that means obsessing over the developer inner loop: data in, prompt iteration, eval rigor, versioning, approvals, and productionization. The “prompt playground” must evolve from experimentation to governance, so teams can move from clever demos to reliable deployments with confidence.
AI continues to reshape the platform’s future. As model ecosystems shift (OpenAI and beyond) and the data plane sprawls (Databricks, Snowflake), developers want a unified surface to build, evaluate, and ship. Integrations with familiar tools like Airtable, Coda, Zapier, and Figma lower adoption friction by meeting teams where they already work, while enterprise-grade controls unlock buyers at the scale of Goldman Sachs.
The cultural choices matter as much as the code. Make big bets with extreme clarity, or don’t make them at all. Stay mission-driven when novelty tempts distraction. Write down the customer promise and keep it tight. Hiring mistakes—especially around quality, curiosity, and ownership—compound quickly in AI product teams, so reset the bar early and protect it.
What PMF really looks like here: customers self-discover core value, usage deepens without hand-holding, and cross-functional teams (engineering, data science, and operations) align around shared definitions of quality. Support volume becomes more about how-to than break-fix. Roadmap prioritization becomes easier because the next best feature reveals itself in the workflow data.
My playbook takeaways for product management leadership in GenAI: prioritize eval rigor before growth, use forward deployed engineers for product discovery, specialize the prompt playground into a governed inner loop, and delay go-to-market until high-bar users pull you in. These are the same principles I apply to gen ai for product prototyping and customer support ai strategy—because durable PMF in AI still comes down to quality, focus, and earned trust.
Referenced:
• Airtable: https://www.airtable.com/
• Adam Prout: https://www.linkedin.com/in/adam-prout-0b347630/
• Braintrust: https://braintrust.dev
• Brian Helmig: https://www.linkedin.com/in/bryanhelmig/
• Coda: https://coda.io/
• Databricks: https://www.databricks.com/
• David Kossnick: https://www.linkedin.com/in/davidkossnick/
I’ve spent the last few years watching AI reshape product roadmaps, developer workflows, and customer expectations. One idea now feels undeniable: the web must evolve to serve a new primary user—AIs. That shift changes how we think about search, reliability, governance, monetization, and ultimately, how we design products that scale with trust.
Parag Agrawal is the co-founder and CEO of Parallel, a startup building search infrastructure for the web’s second user: AIs. Before launching Parallel, Parag spent over a decade at Twitter, where he served as CTO and later CEO during a period of intense transformation, as well as public scrutiny.
I was particularly struck by how crisply this frames the next frontier for product leaders: build systems that machines can consume at massive scale without sacrificing accuracy, provenance, or trust. In particular, I was drawn to the emphasis on “deep research,” where Parallel is tackling “deep research” challenges by prioritizing accuracy over speed, and the design choices that make their APIs uniquely agent-friendly. As someone who has shipped AI features into production, that trade-off resonates—speed gets demos; accuracy earns renewals.
Here’s how I’m synthesizing the most actionable takeaways for product, engineering, and go-to-market leaders. First, design for AI as the primary customer. That means structuring content and APIs so agents can reliably reason, verify, and self-correct. Agent-friendly interfaces need deterministic schemas, explicit provenance, stable latency envelopes, and predictable failure modes. If an agent can’t trust your contract, it won’t chain your service into complex workflows, and you’ll lose the compounding effects that make AI platforms defensible.
Second, bring a systems mindset to accuracy. “Accuracy over speed” isn’t a slogan—it’s an architecture choice. In my experience, that shows up as retrieval strategies tuned for recall and precision trade-offs, multi-pass verification, and human-in-the-loop escalation paths for high-risk queries. For deep research use cases, you need to make the cost of being wrong explicit in your design and your SLAs.
Third, expect your ICP to evolve as AI matures. Early adopters may be research-heavy teams and product creators building agentic workflows. Over time, as reliability improves, your ideal customer shifts toward operational teams that demand measurable outcomes—support deflection, conversion lift, cycle-time reduction. I map these stages explicitly in the roadmap and keep pricing, packaging, and onboarding aligned to each phase.
Fourth, consider business models that keep the web open for AI while aligning incentives. If AIs are the web’s second user, publishers need fair value exchange for structured access, provenance, and usage. In practice, that could look like tiered access, usage-based pricing, attribution requirements, or revenue-sharing tied to agent-driven outcomes. The key is ensuring that openness and sustainability are not at odds.
Fifth, build engineering teams that are both pragmatic and research-aware. On my teams, I look for a balance between high-potential builders who move fast with ambiguous specs and experienced hands who can productionize novel systems. Forward deployed engineers can be a force multiplier here—embedding with customers to surface edge cases, close the verification loop, and turn qualitative insights into productized patterns.
Sixth, recognize how the software engineer’s role is evolving in an AI-assisted world. Engineers are increasingly orchestrators—composing models, retrieval layers, tools, and policies—rather than only writing business logic. That requires better observability for prompts and agents, reproducibility for experiments, and contracts that make emergent behavior inspectable and testable. This is where “uniquely agent-friendly” APIs show their value—clear contracts enable safe autonomy.
Seventh, treat launch timing as a function of trust, not just velocity. Founders often ask when to ship. My rule: launch when you can document bounds, prove repeatability on critical paths, and explain failure semantics. In AI, your narrative is your control surface—fundraising frameworks and customer conversations both benefit when you can quantify reliability, not just showcase capability.
Finally, the long-term vision matters. If agents are finally becoming useful in production, the platforms that win will combine: machine-readable content at scale, accuracy-first retrieval and verification, agent-safe API design, and sustainable economics for an open web. That’s the blueprint I’m applying to my own product strategy: build for agents, measure for trust, and align incentives so the ecosystem compounds rather than fragments.
To product leaders navigating this shift: revisit your ICP, rewrite your API contracts for agents, and make “accuracy over speed” a first-class requirement. To engineering leaders: invest in evaluation harnesses, data quality pipelines, and forward deployed engineers who can turn messy customer workflows into reusable system capabilities. The AI era rewards teams that pair ambition with discipline—and that’s where the next wave of durable advantage will be built.
Education is often labeled a “bad market”—fragmented buyers, long sales cycles, and entrenched systems that resist change. Yet that framing misses a powerful truth: when you build directly for the people who care most—teachers, students, and families—you can unlock extraordinary adoption and defensibility. That’s the core product lesson I drew from the ClassDojo story and one I return to often as a product leader.
ClassDojo is a multi-product education platform used in 95% of U.S. schools and over 180 countries globally to connect teachers, students, and families. The scale is impressive, but the path there is what matters: start with the consumer, design for delight, and let community power distribution. In a space where enterprise selling is slow and political, that decision to serve families first wasn’t just contrarian—it was strategically correct.
Why build for families, not schools? Because enterprise education is broken. District procurement often prioritizes compliance and consensus over usability and joy. By focusing on the “end customer” experience—teachers in classrooms, students eager to learn, parents seeking connection—ClassDojo built pull instead of push. The platform earned trust the hard way: one classroom at a time, one interaction at a time.
The origin story included false starts. A group-making tool didn’t land, and early skepticism about the education market was warranted. But meeting co-founder Liam Don at a hackathon and getting into Imagine K12 provided momentum and mentorship. This is where the founder mindset showed up clearly: relentless resourcefulness. Instead of forcing a PMF narrative, they iterated until they found a communication platform that teachers loved and families valued.
One inflection point I found especially instructive was the conversation with Reid Hoffman that changed everything. The takeaway wasn’t about advice for advice’s sake; it was about reframing distribution. If you want to reach more families, you need to build the network and community that carry your product forward. That means designing every surface for shareability, trust, and repeat use—so your users become your go-to-market.
ClassDojo grew entirely by word-of-mouth. That doesn’t happen by accident. It happens when the product is genuinely delightful, solving a real problem with minimal friction. As a product manager, I think about “designed virality” not as gimmicks, but as a byproduct of exceptional UX: faster onboarding, clear moments of value, and emotional resonance that makes people want to invite others.
The team waited seven years to launch the first monetization feature. That restraint isn’t common, and it’s not always advisable—but in this case, it compounded trust and created a broader surface area for durable revenue later. The principle is timeless: earn the right to monetize by compounding value. When you do, paid experiences can feel like natural extensions rather than distractions.
Market selection decisions were equally thoughtful. Start focused; go broad when the network is strong enough to support new products. The explosive expansion into the tutoring industry is a great example of a logical adjacency: serve an existing community with a new solution that aligns to core jobs-to-be-done. That’s not opportunism—it’s strategy built on distribution strength.
Creating safe online spaces for kids is non-negotiable. Beyond compliance, safety is a product and brand promise. You earn parent and teacher loyalty when you treat trust as a first-class feature—clear controls, default safeguards, and purposeful content environments. In education, this is a core differentiator.
Harnessing AI in education adds a new dimension. The opportunity isn’t to replace teachers; it’s to augment them and personalize learning at scale while preserving safety and transparency. For teams building in this space, the bar is higher: align AI features to measurable learning outcomes, ensure explainability, and keep humans in the loop. That’s how you turn “gen ai” from a buzzword into durable product value.
What’s the enduring playbook I take from ClassDojo? Build for consumers in a system that undervalues them. Pursue word-of-mouth with product excellence, not marketing spend. Sequence monetization after trust. Expand into adjacencies when your community is ready. And above all, practice relentless resourcefulness—keep learning, keep iterating, and keep showing up for the people you serve.