Your analytics agent can turn a question into a chart. Then a product leader asks which activation definition it used, an analyst gets a different cohort result, or security discovers that the agent queried data the user could not normally access. That is where a promising pilot becomes an enterprise risk.
The way through is not a better chat interface. You need a controlled path from question to decision: approved definitions, bounded tools, task-level evaluations, visible evidence, and permissions that expand only after the agent proves it can handle a specific workflow reliably.
Before you give an agent a task, define its contract. The contract should answer five questions:
What decision is being supported? A request to explain a funnel is different from a request to change the funnel definition or publish a recommendation.
Which definitions are authoritative? Identify the canonical metric, its version, the population, the unit of analysis, the time window, and any approved exclusions.
What may the agent access and do? Specify datasets, fields, tools, credentials, and whether the task is read-only, produces a draft, or can trigger an action.
What evidence must accompany the answer? Require the metric identifier, query or tool calls, filters, lineage, assumptions, and enough result detail for an analyst to reproduce the work.
When must the agent stop? Define the ambiguities, policy conflicts, statistical gaps, and high-consequence actions that require clarification or approval.
Consider a seemingly simple question: Did activation decline for new accounts? The answer depends on the approved activation event or event sequence, cohort entry rule, identity resolution, time zone, date range, and exclusions. If the agent silently supplies one of those details, it has made a product decision while pretending to perform analysis.
The safe behavior is straightforward. The agent should retrieve the approved definition, display the material assumptions, and ask for clarification when the remaining ambiguity could change the result. It should not create a new activation definition in the course of answering the question. Changes to definitions belong in a governed workflow with an owner, review, version history, and rollback path.
This distinction also gives you a better definition of accuracy. An answer fails if it uses the wrong metric, violates an access rule, omits a material assumption, or cannot be reproduced, even when the final number happens to be correct. Trust is a property of the whole execution path, not only the sentence shown to the user.
Move through four levels of autonomy one task at a time
Teams often treat agent maturity as a platform-wide label. That hides risk. The same system may be mature enough to draft a funnel but not mature enough to interpret an under-specified experiment. Assign maturity to each task, dataset, and action instead.
Level
Agent role
Evidence required before moving forward
L0: Conversational interface
Summarizes charts or reports that already exist.
The agent accurately identifies the selected artifact, preserves its filters and caveats, and does not imply that it performed new analysis.
L1: Grounded retrieval
Retrieves definitions and context from the analytics catalog, taxonomy, or metric store before answering.
Canonical definitions are consistently selected, citations and assumptions are visible, and retrieval respects the requesting user’s permissions.
L2: Governed tool use
Reads schemas, generates safe SQL, calls approved tools, and reconciles results against canonical definitions.
Representative tasks pass golden-data and regression evaluations; queries, tool calls, lineage, errors, latency, and cost are observable.
L3: Bounded autonomous workflow
Completes an end-to-end workflow with approval gates, audit logs, feature flags, and rollback controls.
The exact workflow has a stable evaluation history, clear ownership, tested failure handling, and a reversible execution path.
L0 can still be useful. It reduces navigation work and helps a user understand an existing dashboard. The mistake is presenting that convenience as autonomous analytics. L1 improves trust by grounding language in the organization’s own definitions, but retrieval alone does not prove that a newly calculated result is correct.
L2 is the consequential transition. The agent is no longer explaining an approved artifact; it is producing analytical work. Schema awareness, safe SQL, result reconciliation, and complete traces become release requirements rather than optional diagnostics.
L3 should describe a narrow, governed workflow, not a general promise that the agent can handle anything. For example, an agent might autonomously refresh an approved weekly retention analysis while still requiring an analyst to approve a new cohort definition. Broaden the task boundary only after the additional behavior has its own tests and controls.
Build evaluations around the work people actually do
A generic chatbot benchmark will not tell you whether an agent can support your product decisions. Your evaluation unit should be a complete analytics task performed under your definitions, schemas, policies, and edge cases.
In my day-to-day building AI products, I’ve learned a simple truth: a single model can be brilliant, but a coordinated team of specialized agents is what consistently ships outcomes customers trust. That’s the promise of multi-agent systems—multiple AIs with distinct roles collaborating inside robust AI workflows to deliver accuracy, speed, and resilience you can’t get from a lone model.
Think of a multi-agent system as a well-run product trio for machines: a planner decomposes the job, specialists execute focused tasks, a reviewer checks quality, and an orchestrator keeps everyone aligned. This agentic AI approach mirrors how high-performing teams work—divide complex problems, play to strengths, and create tight feedback loops.
When does one AI stop being enough? Whenever tasks require tool use, domain retrieval, multi-step reasoning, or policy adherence under real-world constraints. In those moments, specialized agents shine—one for search using a retrieval-first pipeline, another for reasoning, another for action execution, and a final one for validation. The result is better accuracy with manageable latency and cost.
The core architecture I rely on starts with a planner that breaks a goal into steps, followed by execution agents equipped with tools and grounded context. I pair this with context window management to keep prompts lean and relevant, and I insert a verifier (or critic) to catch logic slips and policy violations before results reach customers. A lightweight orchestrator coordinates handoffs and retries to keep the whole flow resilient.
To make this production-grade, I treat observability as non-negotiable. Agent Analytics helps me see which agents are adding value versus adding latency, where failures cluster, and how prompts drift over time. From there, eval-driven development gives me measurable confidence: I codify representative tasks, run offline and shadow evaluations, and only promote changes that move accuracy and safety in the right direction.
Governance is equally critical. I design privacy-by-design from the start, restrict data movement with strong data governance, and enforce policy constraints inside the workflow rather than after the fact. This includes red-teaming failure modes, rate-limiting tools, and capturing immutable traces for audits and post-incident reviews—habits borrowed from SRE culture that map well to AI systems.
On the practical side, prompt engineering remains foundational, but it’s the system design that converts clever prompts into reliable outcomes. Tool access, retrieval quality, memory strategy, and error handling matter more than wordsmithing alone. I’ve found that small prompt improvements are amplified when the surrounding workflow is sound—and are overwhelmed when it isn’t.
If you’re just starting, begin with a narrow use case and a minimal set of agents—planner, executor, and verifier—then expand. Use continuous discovery with real users to learn where the workflow fails in the wild, and iterate with tight release cycles. Treat every agent like a microservice with clear contracts, test coverage, and metrics, and you’ll unlock compounding gains without losing control.
The payoff is tangible: faster shipping cycles, fewer regressions, and outcomes customers can actually rely on. When stakes are high and ambiguity is real, one AI is often a talented soloist—but a disciplined ensemble of agents is how I deliver dependable, scalable value at product velocity.
Your team can generate a PRD, summarize an interview, and draft acceptance criteria in minutes. Yet the product still may not ship faster. Customer evidence remains scattered, decisions lose their rationale at handoffs, and nobody knows whether an AI-generated recommendation deserves to be trusted.
An AI-native product development workflow fixes that operating system. It connects evidence, decisions, delivery, and evaluation in one traceable learning loop. The goal is not to produce more documents. It is to shorten the path from a customer signal to a reliable product decision, then carry the result back into the next decision.
Change the unit of work from an artifact to a decision
AI-assisted teams use a model inside an existing process. They write the same documents, hold the same handoffs, and make the same decisions, only with faster drafting. That can save time, but it leaves the fundamental bottlenecks untouched.
An AI-native workflow reorganizes the process around decisions. Every meaningful unit of work should carry enough context for the next person or system to understand what is being decided, why it matters, and what evidence would change the decision.
Use a decision packet with five parts:
Decision: State the exact choice in front of the team. Replace broad assignments such as improve onboarding with a decision such as whether to change the first-session setup flow for a defined customer segment.
Evidence: Link the customer examples, research moments, usage data, and business constraints that support the problem. Preserve the original evidence rather than storing only an AI summary.
Assumptions: Separate what the team knows from what it believes. An assumption should be written so that new evidence can confirm or challenge it.
Success condition: Name the customer or business behavior expected to change. For an experiment, define the hypothesis and, where appropriate, the minimum detectable effect before exposure begins.
Decision state: Record the owner, status, unresolved questions, next test, and reason for the latest change.
The model can retrieve evidence, compress it, identify inconsistencies, draft alternatives, and check whether required fields are missing. A person still owns the interpretation, trade-offs, priority, and release decision. This boundary prevents polished language from being mistaken for product judgment.
Apply a simple test to every AI-generated artifact: what decision will this change? If the answer is unclear, the artifact is probably workflow noise. If the answer is clear, attach the artifact to the decision packet instead of allowing it to become another disconnected document.
Build an evidence spine before adding more automation
Most product workflows fragment evidence before a model ever sees it. Support tickets sit in one system, sales notes in another, interviews in folders, and behavioral data in an analytics platform. A prompt cannot recover relationships that the operating system never preserved.
Normalize incoming evidence while preserving its source identifier, relevant customer or segment context, and access permissions.
De-duplicate repeated signals and cluster related evidence without erasing meaningful differences between customers or use cases.
Retrieve a small set of representative examples for the decision being made. Do not dump the entire evidence store into the model context.
Write the approved decision, its assumptions, and its rationale into durable external state.
Return experiment results, release outcomes, and new qualitative feedback to the same evidence system.
Keep three forms of information distinct. The evidence store contains raw and normalized inputs. Working context contains only the material needed for the current task. The decision log contains approved conclusions, rejected alternatives, owners, and changes. Mixing all three creates stale prompts, contradictory instructions, and summaries that can no longer be audited.
A prioritization recommendation, for example, should link back to representative customer records and the relevant analytics view. A summary without those links is compression, not evidence. When somebody challenges the recommendation, the team should be able to inspect the underlying material without asking the model to reconstruct its reasoning from memory.
This is also where data governance belongs. Decide which systems the workflow may retrieve from, which fields require redaction, who can see sensitive records, and how model outputs will be retained before connecting those systems. Privacy-by-design, cybersecurity, and regulatory controls need to sit alongside the workflow, not appear as a review after customer information has already crossed an inappropriate boundary.
Run one closed loop from discovery to shipped learning
The product trio remains important in an AI-native workflow. Product, design, and engineering use automation to reach the evidence faster and explore more alternatives, while keeping explicit human gates around interpretation, feasibility, customer experience, and risk. Clear handoffs between context design, external memory, and orchestration make those responsibilities easier to see.
For each stage, name the AI job, the human gate, and the durable output. That turns a collection of AI tools into an operating workflow.
Stage
AI accelerates
Human gate
Durable output
Intake and triage
Normalize, de-duplicate, cluster, and retrieve representative customer signals.
Verify that a cluster reflects a real customer problem rather than repeated wording or a noisy channel.
An opportunity record linked to original evidence.
Discovery
Draft interview guides, summarize transcripts, extract entities, and tag moments of friction.
Interpret what the customer meant, identify contradictions, and decide which uncertainty deserves another conversation.
An evidence-backed problem narrative with open questions.
Opportunity sizing
Organize evidence against a driver tree and assemble available inputs about potential impact.
Choose the outcome, inspect data quality, expose assumptions, and make the prioritization trade-off.
A ranked opportunity with decision criteria and explicit assumptions.
Test desirability, usability, feasibility, strategic fit, and the cost of being wrong.
A solution hypothesis, acceptance criteria, and a test plan.
Planning and execution
Break an approved bet into sequenced work, surface dependencies, and check artifacts for missing requirements.
Set scope, choose rollout controls, confirm instrumentation, and approve release readiness.
An instrumented release plan connected to feature flags, CI/CD, and observability.
Iteration
Compare expected and actual outcomes, organize qualitative feedback, and surface anomalies for review.
Decide whether to scale, revise, stop, or collect more evidence.
An updated decision record returned to the evidence spine.
Exit criteria keep each stage honest. Discovery is not complete because the transcripts have been summarized. It is complete enough to move forward when the team can name the customer problem, the supporting evidence, and the uncertainty it intends to resolve next. Solution shaping is not complete because a PRD exists. It is complete when the hypothesis, constraints, acceptance criteria, test method, and required telemetry are clear enough for a responsible decision.
Plan measurement before release. If the team will use an A/B test, write the hypothesis and minimum detectable effect before looking at the result. If controlled experimentation is not appropriate, name the expected behavior change and the qualitative evidence that would support or challenge it. Feature flags provide controlled exposure, while observability helps the team understand why behavior changed rather than merely showing that it changed.
Engineer context, evaluations, and decision rights together
Reliability cannot be added as a final quality check. Every AI transformation can lose evidence, introduce unsupported language, or carry stale assumptions into the next stage. The workflow needs controls at the moment each failure can occur.
Give each task a context contract
One large prompt that tries to perform discovery, prioritization, specification, and planning will accumulate irrelevant material and conflicting instructions. Break the workflow into smaller tasks, each with a compact context contract:
Use a sub-agent when a task benefits from an isolated context or a separate review, such as checking a PRD against approved evidence. Do not add one merely to make the system look agentic. Every additional agent creates another handoff whose inputs, outputs, permissions, and failure behavior must be evaluated.
Build an evaluation harness before scaling the workflow
An evaluation should answer a repeatable question: does this workflow produce an acceptable result on representative work? A few impressive demonstrations do not tell you whether a prompt, retrieval change, or model update made the system more dependable.
Start with real task types your team already performs. Preserve representative inputs, the evidence that should be used, the requirements an acceptable output must satisfy, and known failure conditions. Then run those cases whenever you change the prompt, model, retrieval logic, tool permissions, or output schema.
Evaluate at least these dimensions:
Grounding: Can each important claim be traced to approved evidence?
Fidelity: Did the output preserve material differences, uncertainty, and constraints rather than flattening them into a convenient narrative?
Completeness: Are the fields required for the next decision present?
Decision usefulness: Does the output help a named owner make a specific choice?
Data handling: Did the workflow respect access, redaction, and retention rules?
Format and tool behavior: Did the model follow the schema and use only permitted systems or actions?
Documents generated, prompts executed, and summaries produced are activity measures. They can rise while product decisions become less reliable. Use four layers of measurement instead:
Learning flow: Time from a customer signal to an evidence-backed decision, time spent waiting at handoffs, and rework caused by missing context.
AI quality: Evaluation results by task, unsupported claims found during review, required fields missed, and human corrections before approval.
Customer outcome: The activation, adoption, retention, or other behavior named in the original hypothesis.
Delivery health: Deployment frequency, change failure rate, and the operational signals relevant to the release.
Keep decision rights visible beside those measures. The model may propose a priority, but the accountable product leader approves it. The model may draft a customer interpretation, but the product trio validates it against evidence. The model may prepare a release plan, but engineering owns operational readiness. Feature flags, access controls, and human approval are not signs that the workflow is insufficiently automated. They are what make greater automation responsible.
Log the decision, evidence references, model version, prompt or workflow version, retrieval configuration, evaluation result, and approving owner. Documenting decisions, model versions, and test artifacts makes a nuanced call auditable and gives the team a concrete starting point when quality changes.
Key takeaways: a 30/60/90-day rollout
Do not begin by automating the full product lifecycle. Start with one recurring decision, connect its evidence to its outcome, and prove that the loop can be operated reliably. A practical 30/60/90 sequence expands from the evidence foundation to selected workflows and then into planning and delivery.
Days 1-30: Map the evidence systems used for one recurring product decision. Define the decision packet, access rules, retrieval path, current human gates, and initial evaluation cases. Build the smallest retrieval-first pipeline that can preserve links from a recommendation back to original evidence.
Days 31-60: Pilot continuous discovery and PRD drafting. Keep approval manual, evaluate representative cases, record recurring corrections, and tighten the context contract. Do not expand until the team can identify why an output passed or failed.
Days 61-90: Extend the proven pattern to prioritization and experiment design. Connect approved outputs to planning, CI/CD, feature flags, and observability. Feed release outcomes and customer feedback back into the evidence spine.
By the end of the rollout, you should be able to trace an AI recommendation to customer evidence, reconstruct why a decision changed, detect a quality regression after a workflow update, and compare the expected outcome with what happened after release. If one of those paths is missing, fix it before adding another agent or automating another handoff.
Your next move can be small. Choose one product decision scheduled for this week. Put its evidence, assumptions, success condition, and state into a decision packet. Then follow that packet through discovery, delivery, and the first outcome review. That single trace will reveal where your workflow is genuinely AI-native and where faster drafting is only hiding an old bottleneck.
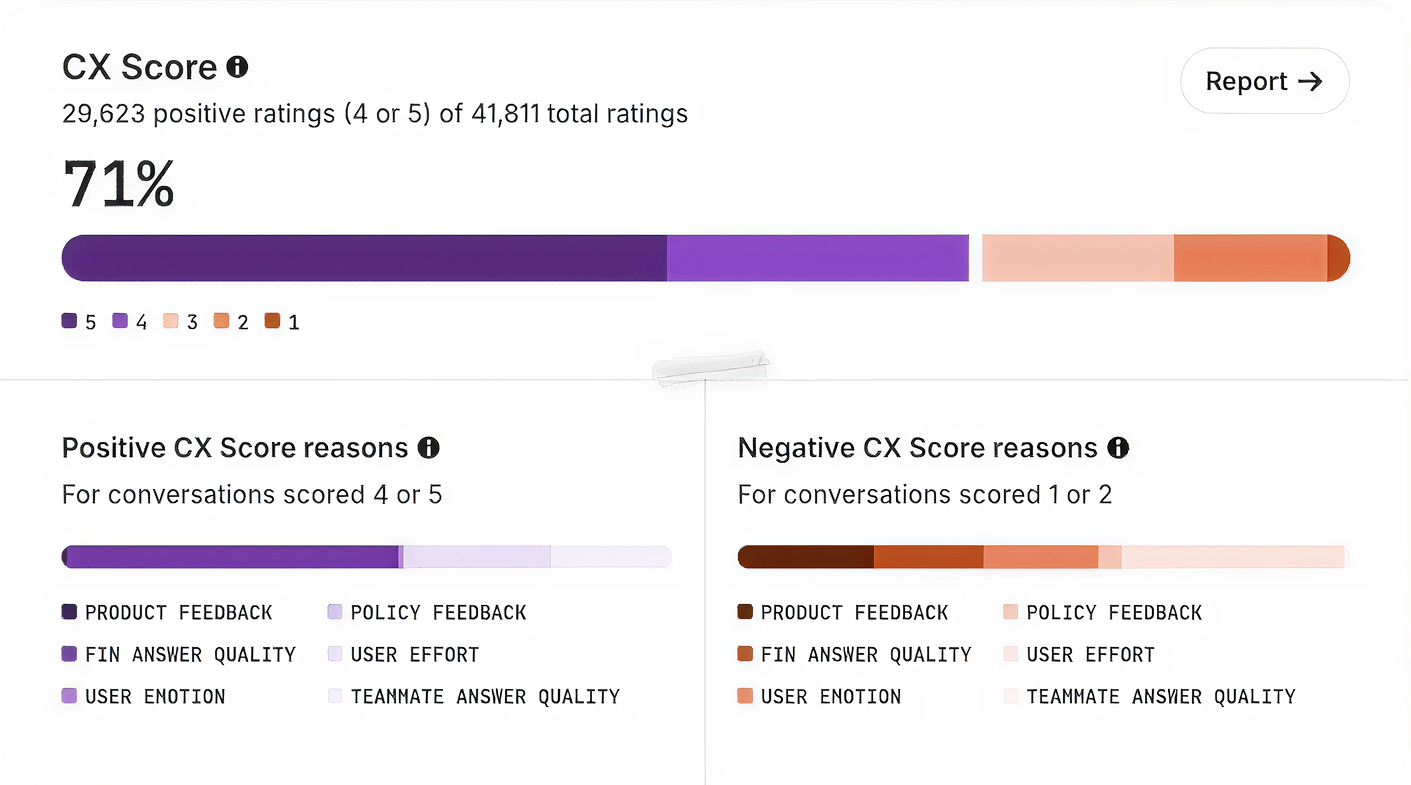
“You don’t have to trust the algorithm; you can see exactly why a conversation earned the score it did.”
We recently shared how we redesigned CX Score to deliver deeper, more actionable insights across every conversation. The most common follow-up from support leaders was simpler and incredibly important: “Can I trust it?” It’s the right question—and it’s the one I use as my own bar for whether a metric is ready for the C‑suite.
CS teams are the subject matter experts on customer experience. They understand the nuance of what customers feel, the context behind every interaction, and the difference between a technically resolved issue and a genuinely satisfied customer. I’ve learned, conversation by conversation, that any metric we ship has to capture that nuance at scale—or it doesn’t deserve to be used.
We built CX Score to give support teams a complete view of how their customers feel across every conversation. It surfaces what’s working, what’s not, and why—so leaders can communicate impact clearly and drive change across support, product, and the wider business.
A CX Score in action: repeated CSV export failures trigger a low score and customer frustration, while the AI agent clarifies next steps and gathers details—turning raw signals into actionable support insights.
Here’s exactly how I approached building a trustworthy metric that support leaders can inspect, explain, and defend.
1) It’s grounded in how support teams define quality. I started with how experienced support professionals actually evaluate conversations—collecting real examples of strong, mixed, and poor interactions across industries, identifying the specific factors that shape overall experience, and writing plain-English rules for each. The result: CX Score applies the same criteria a trained support professional would use, not generic LLM assumptions.
2) It’s aligned with human judgment. We created a dataset of thousands of real customer conversations spanning multiple industries, languages, channels, and agent types. Each was manually reviewed by experienced support professionals—with two reviewers per conversation where possible and disagreement resolution to create stable consensus labels. The result: CX Score is trained and tested to behave like an expert reviewer, not a language model making broad guesses.
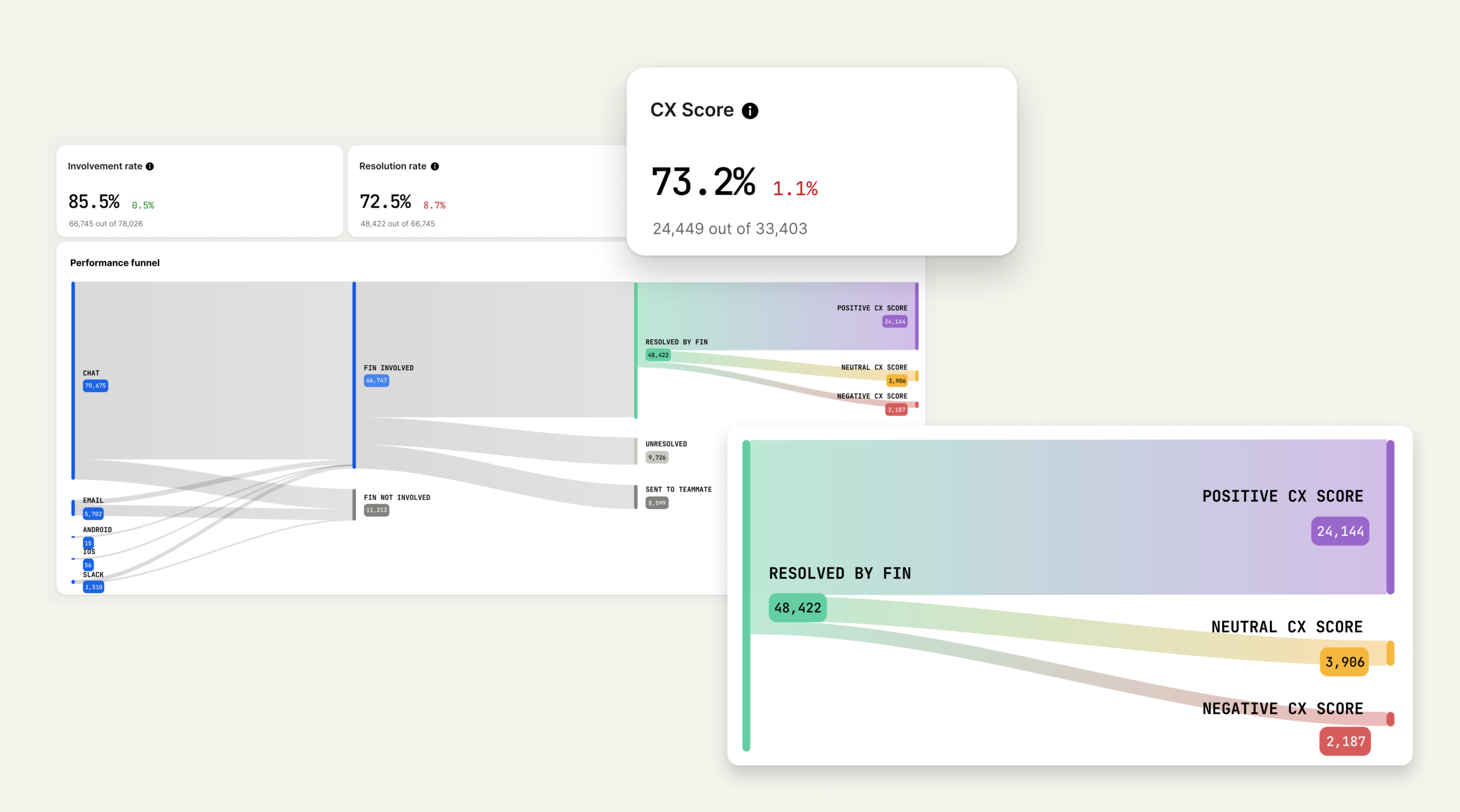
A modern CX analytics view shows how conversations flow from chat, email, and mobile into AI assistance, then to resolutions and sentiment outcomes—turning messy support data into a single, defensible CX Score.
3) It’s engineered by AI specialists. CX Score isn’t a prompt attached to an LLM. It’s a production system built by Intercom’s AI Group: 37 ML scientists and 350 engineers whose full-time focus is AI for customer service. The system includes specialized handling for long transcripts, model configuration tailored for support language and subtle sentiment, prompt engineering designed to default to neutral when evidence is weak, and a multi-stage evaluation pipeline that checks for precision, consistency, and reliability. The result: A metric built by a team that understands LLM behavior in production support environments, where accuracy and consistency matter most.
4) It’s validated statistically, not qualitatively. Trust requires measurement, not vibes. We tested CX Score across standard ML metrics: Precision (when the model flags a negative experience, how often do humans agree?), recall (how many human-identified issues does it catch?), and F1 score (the balance between both). We set an explicit bar: F1 above 0.8, representing high agreement with human judgment. We reran these evaluations through every revision, checking for regressions or biases, and I focused especially on negative experiences, because a false negative hides a real problem. The result: CX Score meets a measurable standard before it ships—not a gut check, a statistical requirement.
5) It was battle-tested with real customers. Lab accuracy isn’t enough. Customer environments are messy: Varied ticket types, mixed languages, unpredictable edge cases. Before release, we ran a multi-phase field test—shadow-scoring conversations with both old and new models, validating sensible behavior across agent type and conversation length, then rolling out to a controlled customer group who confirmed the scores felt right, reasons were clear, and insights were actionable. The result: CX Score shipped because real teams told us it made sense in practice, not because it passed internal tests.
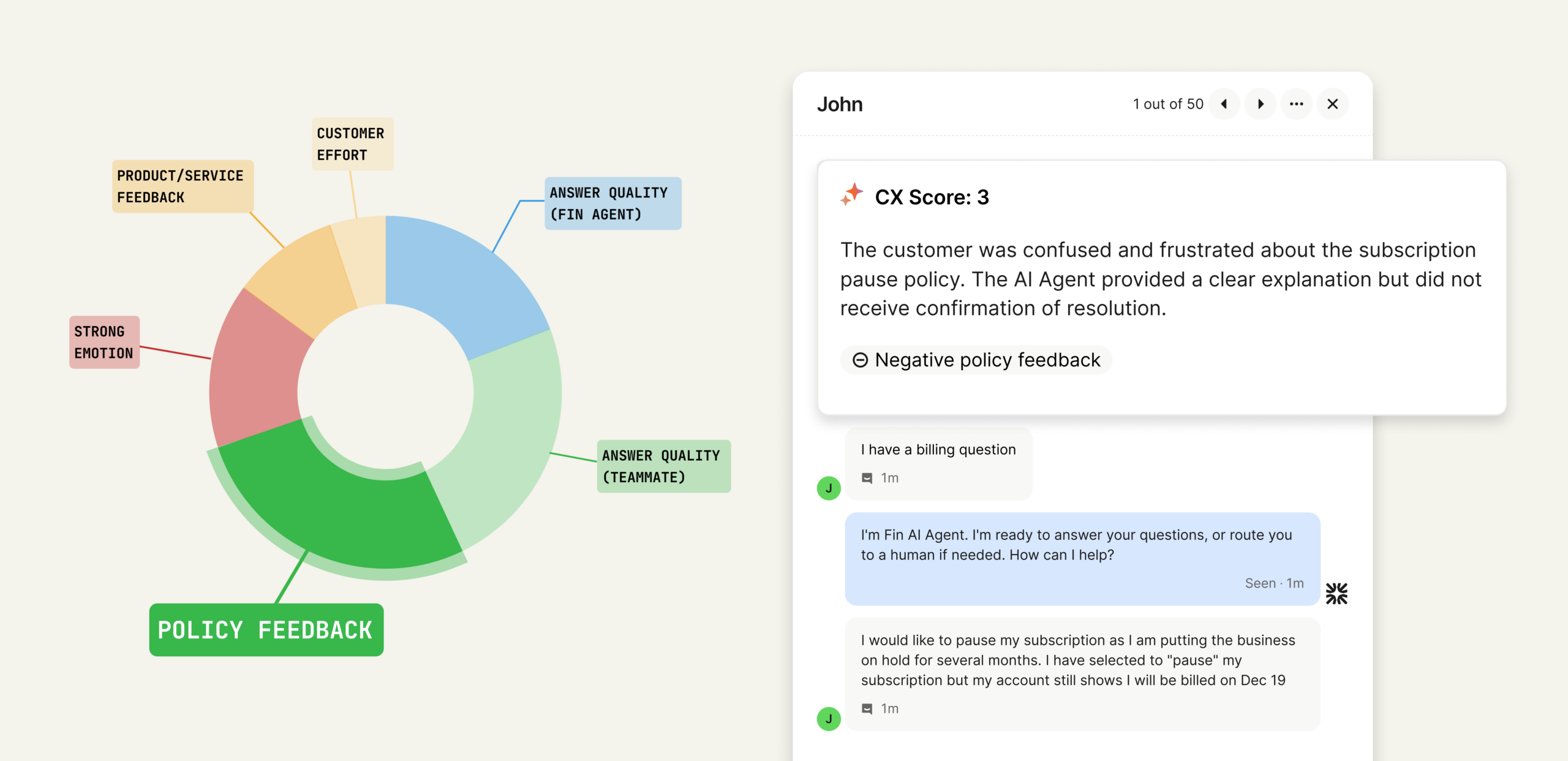
From conversation to clarity: this visual maps the drivers behind a CX Score. Explore how policy feedback, answer quality, and effort combine to produce defendable insights support leaders can act on.
The importance of explainability. One of the most critical choices I made was ensuring CX Score isn’t a black box. Every score comes with clear reasons, concrete excerpts, and a short explanation of what influenced the rating. This turns the metric into something you can inspect, audit, and explain to executives. You don’t have to trust the algorithm. You can see exactly why a conversation earned the score it did.
A metric that evolves with your business. Customer expectations shift. Products change. AI improves. A trustworthy metric can’t be static. CX Score evolves with the same commitments that shaped its redesign: Evaluate the real signals that shape customer experience, keep the logic simple and interpretable, and ensure leaders can make clear decisions from it. It’s built to be a durable source of truth across every conversation.
The takeaway. In a world where products look the same and AI can generate any interaction, customer experience is one of the few differentiators that actually matters. Support leaders have built that expertise conversation by conversation. What they’ve lacked is a measurement system that could validate it at scale—one that’s reliable enough to report to the C-suite, explainable enough to defend in strategy meetings, and rigorous enough to drive real decisions. That’s what CX Score is designed to be: A metric that reflects the reality support leaders see every day, backed by the technical rigor to make it credible everywhere else.
Want to see CX Score in your workspace? Ask your admin to enable it for your team, and start using explainable AI insights to improve customer experience and coach with confidence.
Shipping AI agents is not like shipping a typical feature. The system learns, reasons, and takes action in unpredictable environments, and when it’s customer-facing, the stakes are high. Over the past few years, I’ve refined a practical checklist that helps my teams move quickly without breaking trust. It balances speed with safety, and ambition with accountability—exactly what you need to scale agentic AI in production.
This checklist was forged in real launches—some smooth, some humbling. Early on, I watched an otherwise brilliant agent confidently offer a refund policy we didn’t have. That one incident made it clear: AI agents require a higher bar for guardrails, evals, and observability. Today, I won’t greenlight an AI rollout without these steps being explicit, owned, and testable.
Start with outcomes, not output. I define the job-to-be-done, the target users, and the measurable business impact using outcomes vs output OKRs and driver trees. Success is not “ship an agent,” it’s “reduce first-response time by 40% with no drop in CSAT,” or “increase qualified demo bookings by 20% at a lower cost per acquisition.” Clear outcomes give the agent a purpose and the team a north star.
Prepare the knowledge the agent will use. A retrieval-first pipeline beats raw prompting for most enterprise cases. I inventory sources of truth, set access controls, and enforce data governance from day one. That includes PII handling, redaction, retention policies, and privacy-by-design. If the agent can’t reliably retrieve the right fact at the right time, the rest doesn’t matter.
Choose models and prompts with discipline. I align model selection with context window management, cost, latency, and tool-use requirements. Then I build prompts and tools together, not in isolation, and I keep temperature, stop conditions, and function-calling explicit. Most importantly, I use eval-driven development: golden datasets, task-specific metrics (accuracy, helpfulness, latency, cost), and target thresholds that must be met before widening rollout.
Manage AI risk upfront. I treat jailbreaks, toxicity, and data leakage as product risks, not just security issues. I implement layered defenses—input/output filtering, policy checks, rate limits, and abuse monitoring—and define escalation paths and human-in-the-loop handoffs for ambiguous cases. Every risky capability needs an owner, a playbook, and a test.
Build the pipeline that lets you iterate safely. Prompts, tools, policies, and retrieval configs go through the same CI/CD rigor as code. I use feature flags for progressive delivery, canary cohorts to limit blast radius, and clear rollback procedures. Observability isn’t optional; I track latency, token usage, cost, failure modes, and user outcomes. I also watch DORA metrics and deployment frequency to ensure we’re improving the engine, not just the output.
Constrain autonomy intentionally. Agent behavior design matters as much as model choice. I set step limits, define tool whitelists, separate read vs write permissions, and specify decision checkpoints. When the agent is uncertain or confidence drops below a threshold, it hands off to a human or a deterministic workflow. Guardrails aren’t barriers; they’re bumpers that keep you on the track.
Instrument what users experience, not just what models produce. I track activation, task success, self-serve completion rates, and time-to-value. I pair Agent Analytics with journey analytics so I can see where the agent helps or hurts. I also invest in UX trust cues—transparent explanations, undo paths, and in-app guides—so users feel in control. When the agent changes behavior through learning, the interface should make that understandable.
If you’re shipping a voice AI agent, test in realistic conditions. I set targets for ASR accuracy, barge-in responsiveness, TTS prosody, and end-to-end latency. I predefine safe transfer logic for complex calls and ensure compliance for call recording and data retention. Voice amplifies both the magic and the mistakes; operational excellence is non-negotiable.
Plan the business rollout like a product, not a press release. I align pricing (often consumption SaaS pricing), packaging, and SLAs with actual unit economics—tokens, inference, and retrieval. I equip solutions engineering with playbooks and reference architectures, wire up CRM integration for attribution, and put feedback loops into Intercom or the support stack so we learn from every interaction.
Run operations like an SRE team. I define incident severity for AI-specific failures (e.g., harmful output, runaway cost, degraded retrieval), add alerting, and keep runbooks current. I schedule postmortems that feed directly into eval baselines and backlog priorities. Continuous discovery isn’t a ceremony; it’s the safety net that keeps improvements compounding.
Close the loop on compliance and governance. From day zero, I document data flows, vendor scopes, and audit logs. I verify regulatory compliance and adopt privacy-by-design so I’m not retrofitting later. Transparency, user consent, and opt-outs aren’t just legal checkboxes; they’re trust-building tools that differentiate your product.
The result of this checklist is speed with confidence. It gives my teams a common language to debate trade-offs, a clear path to production, and the guardrails to scale safely. If you’re preparing to deploy an agent, adapt these steps to your stack and your customers. Your future self—and your users—will thank you.
Your AI agent performs beautifully in a controlled demo. Then real users arrive with incomplete instructions, stale records, missing permissions, ambiguous goals, and requests that cross the boundary between drafting something and actually changing the business.
The answer is rarely a longer prompt or a newer model. A reliable agent is a product system: a bounded workflow with trusted context, constrained tools, explicit verification, measurable release gates, and a safe way to stop. Build those pieces together and you can increase autonomy without losing control of quality, cost, or risk.
Start with a reliability contract, not an agent architecture
Before discussing models, memory, orchestration, or frameworks, define the job the agent is accountable for completing. “Answer customer questions” is too vague. “Resolve an eligible billing question using approved account and policy data, record the result, and escalate when authorization or evidence is missing” is a testable contract.
This distinction separates output from outcome. A fluent answer is output. A correctly changed business state is an outcome. The useful metrics therefore sit at the workflow level: resolution rate, time to a verified result, cost per completed task, qualified pipeline influenced, or another measure tied to the user’s job. That outcome-first capability design should happen before anyone selects a model.
Contract field
Decision you must make
Evidence the system must retain
Outcome
What real-world state counts as completed?
The accepted artifact, updated system record, or verified tool result
Scope
Which intents, data, tools, and actions are allowed?
The classified intent, permission decision, and tools invoked
Quality bar
What must be correct, grounded, complete, and timely?
Evaluation results and postcondition checks for the task
Stopping condition
When must the agent ask, refuse, or hand off?
The missing evidence, policy conflict, failed tool call, or risk trigger
Recovery
How can a failed or interrupted run be resumed or reversed?
Run state, committed actions, pending actions, approvals, and rollback path
The stopping condition deserves as much product attention as the happy path. If two trusted records conflict, the reliable behavior may be to expose the conflict. If an API times out after a write, the agent must determine whether the write happened before retrying. If a request would delete data, spend money, alter access, contact a customer, or create a legal commitment, a draft-and-approve flow is safer than silent execution. The downside is not an awkward response; it is an irreversible business action.
A practical autonomy ladder is observe, recommend, prepare, execute a reversible action, and execute a consequential action. Move a workflow upward only when the additional autonomy is necessary for the user outcome and the preceding level has evidence behind it. My rule is simple: earn autonomy one consequential action at a time.
Write the expected handoff as part of the contract. Name who receives it, what context travels with it, what the agent already attempted, and what decision remains. “Escalated to a person” is not a successful fallback if that person has to reconstruct the entire case.
Put a deterministic shell around the probabilistic core
An LLM can interpret ambiguity and propose a plan. It should not also be the unobserved authority for identity, permissions, transaction state, policy enforcement, and whether its own work succeeded. Keep those controls in ordinary application logic wherever possible.
A production workflow usually needs the following control points:
Authenticate the user and validate the request before sending it into the agent loop.
Retrieve only the authorized context needed for this task, with identifiers and provenance attached.
Ask the model for a structured plan that can be inspected, constrained, or rejected.
Validate every proposed tool and argument against policy, permissions, and a typed schema.
Execute scoped actions with timeouts, retry rules, and protection against duplicate writes.
Verify the resulting system state instead of trusting a generated claim that the task succeeded.
Return the result, evidence, unresolved uncertainty, and next state to the user.
That sequence creates a crucial separation between proposing an action, authorizing it, executing it, and verifying it. The LLM can participate in each stage, but it should not collapse all four into one opaque response.
Retrieve evidence for the task, not everything that might be relevant
A retrieval-first pipeline is usually more controllable than placing a large collection of documents in the prompt. Filter by tenant, user permissions, document type, effective date, product area, and workflow state before semantic ranking. Preserve record IDs and timestamps so the answer can be traced back to what the agent actually saw. Lean context also reduces latency, cost, and the chance that irrelevant instructions steer the run.
Embedding similarity is only one retrieval tool. Questions such as “Which decisions changed across these meetings?” depend on time, structure, and purpose, not just semantic proximity. A more capable search layer can combine vector retrieval, lexical search such as BM25, metadata queries, and purpose-built summaries. Route the query to the appropriate retrieval method and give the agent a way to inspect gaps rather than forcing every question through one embedding index.
Retrieved content is still untrusted input. A document can contain stale policy, hostile instructions, or text that resembles a system command. Keep instructions separate from evidence, restrict which tools retrieved text can influence, and apply least-privilege access at the API layer. Privacy-by-design, data governance, structured logs, and tests for prompt injection and data exfiltration belong in the architecture, not in a pre-launch checklist.
Treat every tool as a narrow product interface
A tool description is not merely prompt text. It is an interface contract. Give each tool a single clear responsibility, explicit input types, constrained values, recognizable error states, and a response the workflow can verify. Separate read tools from write tools. Where the underlying system allows it, add dry-run modes, idempotency keys, and an endpoint that checks the final state.
Avoid exposing a broad “run anything” tool when the agent only needs to look up an account, prepare a ticket, or update one approved field. Narrow tools reduce the decision surface, simplify evaluation, and make permission reviews legible. They also let you disable one unsafe capability without taking the entire agent offline.
Persist enough state to answer operational questions after the run: which prompt and model version ran, what was retrieved, which plan was selected, which tools were attempted, what they returned, what was committed, which verification passed, and whether a person approved the action. Do not rely on a natural-language transcript as the only record. Store structured events with a run identifier and propagate that identifier through tool calls.
Model selection comes after these boundaries are clear. Tool-use fidelity, prose quality, latency, multilingual performance, context needs, and cost can point to different choices. Newer is not automatically better: one production team found GPT-4.1 more suitable for its prose workload than newer alternatives. Keep the workflow and evaluation interfaces model-agnostic enough to compare or replace providers without rewriting the product.
The same discipline applies to multi-agent designs. Parallel agents are useful when tasks are genuinely independent, such as preparing different artifacts from a shared meeting. Specialized agents can also isolate permissions or context. But each added agent introduces another prompt, model call, state transition, failure path, and cost center. A second agent is not meaningful verification when it sees the same evidence, inherits the same assumptions, and merely agrees with the first. Add orchestration only when the separation has a measurable job.
Make workflow evaluations a release gate
A few attractive examples cannot tell you whether an agent is production-ready. Reliability work starts by naming how the workflow can fail, then turning those failure modes into repeatable tests.
Use a failure taxonomy that follows the run from request to outcome:
The agent misunderstood the intent or accepted a task outside its scope.
Retrieval omitted the necessary record, returned stale information, or crossed an access boundary.
The plan skipped a required step or selected an unsafe sequence.
The agent chose the wrong tool or supplied invalid arguments.
A tool failed, timed out, or completed after the agent assumed it had failed.
The response introduced an unsupported claim or concealed uncertainty.
The agent claimed success even though the intended system state was not reached.
The handoff occurred too late or omitted information the recipient needed.
Build a golden dataset from real user intents and known edge cases. Include normal successful work, ambiguous instructions, missing data, conflicting records, insufficient permissions, tool errors, adversarial content, and requests that should be refused or escalated. Each case needs an expected outcome, allowed tools, forbidden actions, required evidence, and an evaluation method. Otherwise the dataset is a collection of prompts, not a product specification.
Grade the system at several layers. Task success checks whether the intended state was reached. Grounding checks whether material claims are supported by authorized evidence. Tool-use evaluation checks selection, argument correctness, sequence, and postconditions. Safety evaluation checks policy and access boundaries. Handoff quality checks whether the receiving person can continue without repeating work. Latency and cost reveal whether the successful path is operationally sustainable.
Use deterministic checks where the answer is objective. An account ID, required field, permission decision, or database state should not need a subjective model judge. Use rubric-based model evaluation or calibrated human review for writing quality, helpfulness, and other dimensions that genuinely require judgment. Regularly compare automated grades with human decisions; an evaluator can drift or share the actor model’s blind spots.
Do not hide a severe failure behind an average score. Segment results by intent, tool, customer type, language, risk class, and workflow version. A high overall pass rate says little if the agent consistently fails the one action that changes access or sends a customer-facing commitment. Set separate go/no-go requirements for critical slices and treat forbidden actions as release blockers.
A disciplined release path looks like this:
Run offline evaluations against the current production version and the candidate change.
Replay representative historical traces with writes disabled and inspect changed decisions.
Shadow real traffic without allowing the candidate to act.
Expose the candidate behind a feature flag to internal or explicitly selected users.
Canary the workflow with a limited production population and a tested rollback path.
Use an online experiment when the question concerns user or business impact, defining the minimum detectable effect before interpreting the result.
Expand only after task success, safety, handoff, latency, and cost remain within their release requirements.
This is eval-driven development in practical terms. Prompt, retrieval, model, tool, and policy changes are versioned product changes. They enter the same comparison pipeline and cannot bypass it because someone considers a prompt edit “just configuration.”
Scale reliability and unit economics as one system
An agent can be accurate and still be unscalable. It can also look inexpensive per model call while becoming costly per resolved task because it retrieves too much, retries weak plans, invokes unnecessary tools, or sends avoidable cases to people.
Measure cost per completed safe task. The numerator should include model inference, retrieval, external APIs, tool execution, retries, verification calls, and required human review. The denominator should include only tasks that reached the intended state without violating the contract. Counting failed or falsely completed runs as successful makes the economics look better precisely when reliability is deteriorating.
Instrument the complete trace so you can attribute both cost and delay to a stage. Useful operating views include task success by intent, tool errors by endpoint, retries by plan type, escalations by reason, latency by stage, cost by model and workflow version, unsupported-claim rate, and verification failures. Pair those measures with user satisfaction and downstream correction signals; a fast completion is not a win if a person has to undo it later.
Cost work should target the mechanism, not apply a blanket downgrade. Shorten irrelevant context. Retrieve smaller evidence sets. Cache stable prompt prefixes where the provider and privacy posture allow it. Route simple classifications away from expensive reasoning models. Reuse deterministic results. Remove redundant verification, but only when evaluations show it adds no protection. In one concrete case, Earmark reported reducing its meeting workflow from about $70 per meeting to under $1 through prompt caching. That is a product-specific result, not a general benchmark, but it shows why context and caching decisions can determine whether an agent remains a demonstration or reaches everyday use.
Define service objectives around the user journey rather than a generic chatbot response. Track whether eligible tasks finish safely, whether consequential actions are verified, how long the user waits for the intended outcome, whether interrupted runs recover, and whether handoffs retain context. Set the actual thresholds from the workflow’s risk, user promise, baseline performance, and economics; there is no responsible universal target for every agent.
Prepare for incidents before increasing exposure. The operating playbook should identify the on-call owner, alert conditions, kill switch, feature flags, tool-specific disablement, prompt and model rollback procedure, trace replay process, customer-impact assessment, and postmortem owner. Test that the team can stop writes while preserving read-only or handoff behavior. An all-or-nothing shutdown is avoidable when capabilities are independently gated.
Data retention is another scaling decision, not merely a legal footnote. Record what must be retained for debugging, audit, recovery, and user value; minimize everything else; define access and deletion behavior; and make the choice visible to enterprise reviewers. An ephemeral architecture can become a commercial advantage when persistent conversation storage is unnecessary: a no-storage design reduced a real enterprise adoption objection. It will not fit every workflow, especially where auditability requires durable records, so make retention a deliberate contract rather than a default.
Use the first 90 days to earn a narrow production footprint
A useful 90-day plan does not promise an autonomous platform by the end of the quarter. It creates one bounded production workflow, evidence that the workflow is valuable, and the controls required to expand it. The sequence below adapts an outcome-led 90-day AI operating model to agent reliability.
Days 0-30: define the contract and make failure observable
Choose a frequent workflow with a recognizable end state and enough value to justify automation.
Write the outcome, eligible intents, tools, data boundaries, prohibited actions, stopping conditions, and handoff owner.
Map every identity, permission, retention, and policy dependency before connecting write tools.
Baseline the current process so improvements in completion, time, cost, and quality have a meaningful comparison.
Assemble real and adversarial evaluation cases with expected outcomes and forbidden behaviors.
Implement structured traces and a read-only or dry-run version of the workflow.
The exit criterion is not a persuasive demo. You should be able to inspect a run and determine, without guessing, whether it completed the job, what evidence it used, what it changed, and why it stopped.
Days 31-60: connect tools behind controls
Implement narrow tool adapters with typed inputs, permission checks, stable errors, timeouts, and duplicate-write protection.
Add retrieval filters, provenance, postcondition checks, and explicit approval points.
Version prompts, models, policies, retrieval settings, and tool schemas as one releasable workflow.
Run offline comparisons and shadow traffic, then review failures by category rather than as isolated bad answers.
Add feature flags, tool-specific disablement, alerts, and a tested rollback path.
Assign a product owner for the outcome and named engineering, risk, security, and operational partners for the controls they own.
Leave this phase only when every serious known failure class has either a preventive control, a detection mechanism, or an explicit human gate. A line in a risk register is not a runtime control.
Days 61-90: canary, learn, and expand selectively
Release to a limited population whose intents and permissions match the evaluated scope.
Monitor safe task completion, false-success signals, handoffs, latency, cost, corrections, and user outcomes by workflow version.
Review traces for both failures and unexpected successes; an agent may reach the right answer through an unsafe path.
Run incident and rollback drills before raising the exposure or enabling a more consequential action.
Compare production behavior with the baseline and the predeclared release requirements.
Expand one dimension at a time: more users, another intent, a new tool, or greater autonomy. Re-run the relevant evaluations after each change.
The exit criterion is operational ownership. Someone owns the workflow’s outcome, someone responds when it degrades, the system can be rolled back, and the roadmap is driven by observed failure and value rather than a list of impressive agent capabilities.
Key takeaways
Define reliability as a completed, verified user outcome inside explicit boundaries.
Keep authorization, policy enforcement, transaction state, and postcondition checks outside the model wherever possible.
Evaluate retrieval, planning, tool use, safety, handoff, and final state – not just the generated response.
Gate changes with offline tests, shadowing, feature flags, canaries, and rollback procedures.
Measure cost per completed safe task and optimize the stage causing the expense.
Increase scope and autonomy separately so production evidence can tell you which change caused a regression.
Start with one workflow this week. Write its reliability contract, collect representative failures, and make a dry run traceable from request to verified outcome. Once that narrow path is measurable and recoverable, you have something worth scaling – and a defensible reason to grant the agent its next action.
Your AI feature can be online, fast, and still be failing. A report renders but omits important records. A workflow returns valid JSON with the wrong meaning. A retry creates a duplicate. A permissions change quietly removes the data needed for a trustworthy answer.
If you own an AI product, an uptime dashboard cannot tell you whether users are receiving the outcome you promised. You need a reliability system that covers data, models, runtime dependencies, output quality, delivery, and recovery. The practical goal is not to eliminate every failure. It is to detect meaningful failures early, contain their impact, and recover without making the situation worse.
Define reliability at the user-outcome boundary
Traditional service reliability often starts with a relatively clean question: did the request succeed? AI products make that question insufficient. A request can return a success status while the user receives an incomplete, structurally invalid, stale, unauthorized, or semantically poor result.
Start by writing a reliability contract for one important user journey. State what must be true when that journey succeeds. A useful contract usually covers these dimensions:
Reliability dimension
Question to answer
Evidence to capture
Completion
Did the workflow reach a terminal outcome?
Completed, rejected, timed out, cancelled, or still pending
Structural validity
Does the output satisfy the interface expected downstream?
Schema-validation result, schema version, and rejection reason
Data integrity
Was the required data accessible, current, and complete enough for the task?
Data-source status, permission result, retrieval result, and freshness signal
Semantic quality
Is the answer useful and acceptable for this use case?
Evaluation result by task, customer segment, language, or workflow
Latency
Did the outcome arrive while it was still useful?
End-to-end latency and latency for each pipeline stage
Delivery integrity
Was the result applied once, without duplication or corruption?
Idempotency key, write status, attempt count, and final state
Privacy and risk
Did processing respect the product’s data-handling rules?
Policy checks, PII-scanning result, access decision, and exception path
This contract prevents an easy but damaging mistake: counting technically completed requests as successful user outcomes. If a report is truncated yet parseable, the transport succeeded and the product failed. If a model response is excellent but based on data the user can no longer access, the answer should not be delivered as a success.
Turn the contract into service-level indicators that the system can measure. Then set service-level objectives around the indicators that matter to the user. The difference between the objective and actual performance becomes the error budget available for change and experimentation.
Do not hide behind a global average. Break reliability down by model, prompt version, schema version, dataset, workflow, customer segment, and dependency. AI failures are often concentrated. A healthy aggregate can conceal a severe regression for one language, one integration, or one high-value workflow.
Your error budget should also drive decisions. When budget consumption accelerates, narrow the rollout, pause the risky change, or redirect capacity toward the failure path. When the budget is healthy, you have evidence that the product can absorb controlled experimentation. That is more useful than declaring reliability important while allowing roadmap pressure to settle every tradeoff.
Instrument the full path from request to delivered outcome
A useful AI trace does not stop at the model call. It follows the user request through authentication, permission checks, data retrieval, context assembly, model execution, output validation, business rules, persistence, and delivery. Give the journey one correlation identifier so an engineer can move from a failed user outcome to the responsible stage without reconstructing the request from unrelated logs.
Build visibility at three levels:
Structured events: Record the request identifier, workflow, customer segment, model, prompt version, schema version, dependency, attempt number, latency, result class, and failure code. Use controlled fields rather than free-form error messages for the dimensions you expect to aggregate.
Distributed traces: Create a span for each meaningful stage. A trace should show whether time was spent waiting in a queue, retrieving data, calling a provider, validating output, or committing a side effect.
Keep raw customer data, prompts, and model responses out of routine telemetry unless there is a defined and approved need to retain them. Structured metadata is usually enough for operational diagnosis. When content must be inspected, apply access controls, retention rules, redaction, and PII scanning as part of the observability design. Logging sensitive data first and deciding how to govern it later creates a second reliability problem: the monitoring system becomes a source of risk.
Design failure codes around actions, not organizational boundaries. Invalid model output, missing source permission, provider throttling, exhausted token budget, duplicate delivery, and policy rejection tell the responder what kind of path failed. A generic model error or integration error forces the on-call person to rediscover information the system already had.
Alerts should represent conditions that require intervention. Error-budget burn, broad validation failures, growing queue age, or a dependency circuit remaining open may justify an immediate response. A slow-moving change in evaluation performance may belong in a product review instead. If every anomaly pages someone, the monitoring system trains the organization to ignore it.
The same dashboard should work for product and engineering. An SRE needs the failing dependency and trace. A product leader needs the affected workflow, segment, volume, and user consequence. Connecting both views prevents a team from fixing the loudest technical symptom while a quieter failure causes more product damage.
Harden each boundary instead of trusting the happy path
Most AI workflows combine components with different failure behavior: internal services, databases, queues, retrieval systems, model providers, and third-party data sources. Reliability comes from controlling the boundary around each component. The following sequence gives you a practical hardening checklist.
Bound every external call. Set explicit timeouts using observed latency distributions, including p95 behavior, as an input. A missing timeout allows one slow dependency to consume workers and delay unrelated requests. Treat timeout as a classified outcome rather than an unhandled exception.
Retry only failures likely to be temporary. Provider throttling and transient network failures may recover. Invalid input, permission denial, and schema rejection usually will not. Use delayed retries with exponential backoff and jitter so concurrent failures do not return as another synchronized burst. Cap attempts and record the final reason.
Put a circuit breaker around unstable dependencies. When failure crosses the condition you have defined, stop sending traffic long enough to prevent resource exhaustion and cascading latency. Make the open, probing, and closed states visible. The product should communicate a controlled unavailable or delayed state rather than pretending work completed.
Make side effects idempotent. Derive the idempotency key from the logical operation, destination, and relevant payload version. Persist the result of the operation so retries can return or reconcile the prior outcome. Do not depend on local wall-clock time alone to distinguish writes; clock skew can turn retry protection into duplicate or missing work.
Apply backpressure before the queue becomes the outage. Bound concurrency for each constrained dependency. When demand exceeds safe processing capacity, queue, defer, or reject according to the user promise. Preserve enough state to resume safely. Unbounded retries feeding an unbounded queue convert a temporary provider problem into a long recovery.
Validate contracts before committing effects. Validate generated JSON against the expected schema, including required fields, types, allowed values, and relevant bounds. Keep parsing separate from business validation: syntactically valid output can still violate a product rule. Reject or quarantine invalid results before they reach reporting, billing, messaging, or another irreversible operation.
Detect incomplete generation explicitly. Budget context and expected output together. When the provider exposes completion metadata, use it to distinguish a completed response from one stopped by a limit. Do not pass partial structured output downstream merely because a parser can repair it. Reduce unnecessary context, split an oversized task, or return a controlled failure.
Treat permissions as changing runtime state. Check access near the point of retrieval, classify authorization failures separately, and monitor permission-related drops by integration. Do not repeatedly retry a denial. If upstream access changes silently, the product should expose which data is unavailable rather than producing an apparently complete result from a partial dataset.
Put risky behavior behind feature flags. Separate deployment from release. A flag should let you disable a model, prompt, retrieval path, or downstream action without waiting for another deployment. Test the rollback or disable path before relying on it during an incident.
These controls need an explicit order of operations. Validate permissions before retrieving sensitive data. Validate generated output before executing a side effect. Persist idempotency state before acknowledging completion. Apply retry policy after classifying the failure. Ordering is what prevents individually sensible mechanisms from undermining one another.
Be careful with graceful degradation. It is useful when the degraded state remains honest and valuable, such as delaying a non-urgent report or identifying an unavailable data source. It is dangerous when the system silently substitutes stale, incomplete, or lower-quality information and presents it as equivalent. The user must be able to distinguish degraded output from normal output.
Make model and prompt releases earn production traffic
A prompt edit can change output structure. A model change can improve one task while weakening another. A retrieval change can alter both answer quality and latency. Treat these modifications as production changes even when no application code changed.
An eval-driven release path should work like this:
Version the complete behavior. Record the model, prompt, schema, retrieval configuration, tool definitions, policy rules, and relevant application release. Without this bundle, a failed response cannot be reproduced with confidence.
Build evaluations around the product contract. Cover representative tasks, important customer segments, difficult inputs, and failure cases discovered in production. Include structural checks alongside semantic checks. A quality score cannot compensate for output that breaks its interface.
Establish a baseline. Compare the candidate with the current production behavior on the same evaluation set. Review the distribution by meaningful slice rather than relying only on one average score.
Gate promotion in CI/CD. Require the agreed evaluation baselines to hold or improve before the candidate can progress. Make exceptions explicit, owned, and reversible. A hidden manual bypass is not a release policy.
Release through a canary. Send a limited, observable portion of eligible traffic to the candidate. Keep the current version available. Watch evaluation signals, validation failures, p95 latency, dependency behavior, and error-budget consumption by version.
Expand in stages or roll back. Increase exposure only while the user-facing indicators remain within the agreed conditions. If a signal degrades, use the feature flag or version control to stop exposure quickly while preserving diagnostic evidence.
The release gate needs product judgment. Not every evaluation failure carries the same consequence. A formatting defect in an internal draft is different from an unsupported claim in a customer-facing recommendation or an unauthorized action by an agent. Define which failures block release, which require human review, and which can be monitored after release.
Do not force a choice between delivery speed and reliability without evidence. Track deployment frequency alongside change failure rate. Frequent, small, reversible releases can improve both learning speed and recovery. Large bundled changes make it harder to identify the cause of regression and increase the amount of behavior a rollback must undo.
Before approving an AI release, a product leader should be able to answer five questions:
Which user promise can this change affect?
Which evaluation and production indicators represent that promise?
Which segments could regress even if the aggregate improves?
What condition stops or reverses the rollout?
Who has the authority and the mechanism to act when that condition appears?
If those answers are missing, the release is relying on optimism rather than a control system.
Run reliability as a product operating system
Technical safeguards decay unless ownership and operating routines keep them current. Models change, integrations evolve, permissions move, and traffic develops new burst patterns. Reliability therefore belongs in roadmap and incident decisions, not in a one-time infrastructure project.
Prepare a lightweight runbook for each critical journey. It should identify the owner, user-visible failure states, primary indicators, relevant dashboards, recent release controls, dependency status, safe disable path, and rules for replaying work. A responder should not have to infer whether replay can duplicate a message, report, charge, or external action.
During an incident, establish the user impact before chasing every technical symptom. Identify the affected workflow and segment, stop further harm, preserve evidence, and use the safest available rollback or containment control. Communicate whether results are delayed, incomplete, unavailable, or at risk of duplication. Those states require different user actions.
Afterward, use a blameless review to find the conditions that allowed the failure to reach users. The strongest follow-up actions are testable and automatable: a new schema check, an evaluation case, a permission metric, a retry limit, a canary gate, a better idempotency key, or a rehearsed rollback. An instruction to be more careful is not a control.
Prioritize the reliability backlog by user consequence and error-budget impact. A noisy internal exception with no lost outcome may matter less than a silent data omission affecting a small but important workflow. This keeps observability from becoming a competition to reduce whichever counter is easiest to move.
Privacy-by-design and AI risk management belong in the same operating system. Add PII scanning, access validation, and policy checks to the pipeline and release gates. Assign owners for exceptions. Revisit the controls as the product gains new data sources or actions. Risk is a continuing product constraint, not a review performed after the architecture is settled.
Key takeaways
Define success at the delivered user outcome, not at the HTTP response or completed model call.
Measure completion, structural validity, data integrity, semantic quality, latency, delivery integrity, and privacy where each applies.
Trace the whole pipeline and segment reliability by model, prompt, schema, workflow, dataset, and customer group.
Use timeouts, selective retries, circuit breakers, idempotency, backpressure, validation, and feature flags as coordinated controls.
Gate model and prompt changes with evaluations, then use canaries and staged releases to limit exposure.
Let SLOs, error-budget consumption, and user consequence determine when reliability work outranks feature work.
Choose your highest-consequence AI journey and write its reliability contract. Trace it end to end, attach an SLO to the user outcome, and replay the known failure modes against the controls you already have. If the system cannot tell you whether its output was valid, complete, permitted, and delivered once, that is the first reliability gap to close.
Your AI agent may look convincing in a demonstration and still disappear from daily work. If people try it once but return to spreadsheets, dashboards, tickets, and manual handoffs, you do not have an awareness problem. You have a workflow design problem.
Real adoption begins when a specific user can delegate a meaningful part of a recurring job, understand the agent’s limits, and see that the resulting decision or action is better. Product leaders create those conditions by narrowing the workflow, defining the agent’s authority, measuring the complete decision loop, and expanding autonomy only after the evidence supports it.
Choose a workflow, not a place to add AI
Starting with “Where can I deploy an agent?” pushes the team toward a feature. Start with “Which recurring decision or action is unnecessarily difficult?” That question keeps the work tied to customer or business value.
A good first workflow is frequent enough to generate feedback, narrow enough to evaluate, and bounded enough that a mistake can be caught before it causes material harm. It also has an identifiable beginning and end. “Help people be more productive” is not a workflow. “Use approved customer evidence to prepare the next-best-action options for a campaign review” is much closer.
Evaluate candidate workflows against six practical criteria:
Trigger: The user can recognize the moment when the agent should enter the workflow.
Frequency: The job repeats often enough for the user to form a habit and for the team to learn from actual use.
Grounding: The agent can retrieve the approved data, policies, history, or customer evidence required to do the job.
Completion: The team can observe whether the task reached a useful end state, rather than merely whether the model returned text.
Decision boundary: Everyone can state what the agent may decide, what requires approval, and what it must never do.
Recoverability: An incorrect recommendation or action can be rejected, corrected, or reversed without disproportionate damage.
Mark each candidate high, medium, or low on those criteria. Do not hide a weak decision boundary behind an attractive use case. A repetitive workflow with clear evidence and a review point is usually a better adoption bet than an ambitious end-to-end process with unclear ownership.
This is also why natural-language access alone is not an agent strategy. It can lower the barrier between a user’s question and an analytical answer, which may improve activation. Adoption becomes more valuable when the answer connects to a defined next action and the eventual impact of that action can be observed.
Write the selected workflow in one sentence before approving a roadmap:
When [user] encounters [trigger], the agent uses [approved context] to [recommend, prepare, or execute an action]; [person or policy] controls [decision boundary], and success is measured by [workflow or customer outcome].
Agent workflow template
If the team cannot complete that sentence without vague language, discovery is not finished.
Write an adoption contract before writing the roadmap
An agent changes who performs work, which information informs it, and where accountability sits. That is an operating-model decision disguised as a product feature. A one-page adoption contract makes the change explicit before implementation creates momentum around the wrong behavior.
The contract should answer seven questions:
Who is the intended user? Name the role and the situation, not a broad department.
What job is being delegated? Separate information retrieval, analysis, recommendation, preparation, and execution. They carry different risks.
What outcome should improve? Connect the workflow to an existing customer or business outcome, not to the amount of AI content produced.
Which information is authorized? Identify the systems of record, retrieval scope, freshness requirements, and data that must remain unavailable.
Where does human judgment remain mandatory? Put approval at the consequential decision, not at an arbitrary screen in the interface.
How should uncertainty and failure appear? Define when the agent should cite evidence, ask for missing context, abstain, escalate, or report that a tool failed.
What earns expansion? Specify the quality, adoption, outcome, and risk signals required before the agent receives more users, tools, or autonomy.
This contract prevents a common measurement error: treating interaction volume as value. Conversations, generated documents, and tool calls are outputs. They can help diagnose behavior, but they do not show that the workflow improved. Activation, successful completion, repeat use at the next relevant trigger, and retention are stronger adoption signals. They still need to connect to a journey outcome such as a better decision, a completed customer task, or a validated change.
Use outcomes versus output OKRs to keep the distinction visible. An output key result might promise to launch an agent or add integrations. An outcome key result should describe the behavior or customer result that the workflow is intended to change. The delivery milestone belongs in the plan; it should not masquerade as proof of adoption.
The contract also makes prioritization easier. A request for another model, data connector, or agent tool must improve a named part of the workflow. If it cannot be tied to grounding quality, task completion, user control, or the target outcome, it is probably infrastructure enthusiasm rather than a product requirement.
Earn autonomy through observable stages
Do not jump from a chat interface to autonomous execution because the happy-path demo worked. Autonomy should advance in stages, with a different role for the user and a different standard of evidence at each stage.
Capability stage
What the agent does
Human responsibility
Evidence needed to advance
Explain
Retrieves and synthesizes approved information
Checks the evidence and interprets it
Grounding, completeness, and answer-quality evals
Recommend
Produces alternatives or ranks possible next actions
Makes the decision and records important overrides
Relevance, reasoning, boundary, and decision-support evals
Prepare
Creates a draft action, configuration, or artifact without committing it
Edits and approves before execution
Task-specific correctness, policy, format, and exception evals
Act
Executes a bounded action through approved tools
Supervises exceptions and reviews consequential cases
Reliable task completion, tool behavior, auditability, and recovery controls
The stages are not a maturity contest. Some workflows should remain in recommendation or preparation mode because the consequences of an incorrect action outweigh the benefit of removing approval. Human-in-the-loop design is useful when the person has evidence, authority, and enough context to intervene. A mandatory click from someone who cannot evaluate the result adds friction without adding control.
Before releasing each stage, create an evaluation set that represents the actual workflow. Include normal cases, ambiguous requests, missing or stale context, policy boundaries, conflicting evidence, and tool failures. For every case, record the expected behavior, unacceptable behavior, scoring rubric, and evidence the evaluator should inspect.
Do not collapse evaluation into a single pass rate. An answer can be fluent and wrong, properly grounded but irrelevant, or correct while attempting an unauthorized action. Score the dimensions that matter independently: retrieval and grounding, task correctness, tool selection, instruction adherence, policy compliance, escalation behavior, and completion quality.
Treat prompts and evaluation datasets as versioned product assets. When the model, prompt, retrieval logic, tool definition, or policy changes, rerun the relevant evaluation set and preserve the result with the release. Otherwise, a team can improve one visible behavior while silently degrading another.
A retrieval-first design is especially important when the workflow depends on institutional knowledge. The agent should use authorized context before relying on general model knowledge, expose enough evidence for the user to inspect, and ask for clarification or abstain when required context is unavailable. That behavior may look less magical in a demonstration, but it is much easier to trust in repeated work.
Measure the entire agent loop, not the chat surface
A traditional feature funnel can tell you who opened an agent and who returned. It cannot explain whether the agent retrieved the right context, selected the right tool, required extensive correction, or produced an action that affected the intended outcome. Agent Analytics must reconstruct the path from intent to result.
Instrument the workflow as a connected event chain:
Intent and eligibility: Which workflow was triggered, and was the user and situation within scope?
Context: Which approved knowledge or data was retrieved, and was essential context unavailable?
Reasoning path: Which plan or action sequence did the system select?
Tool behavior: Which tools were called, which arguments were passed, and where did errors or retries occur?
Human intervention: Did the user accept, edit, reject, override, or abandon the result?
Completion: Did the workflow reach its defined end state?
Outcome: Did the customer or business indicator named in the adoption contract move in the intended direction?
Apply privacy-by-design to that event model. Logging every raw prompt, retrieved record, or tool payload by default can create unnecessary exposure. Decide which fields are required for product learning, who may access them, how sensitive data is handled, and how long the information is retained. Data governance belongs in the instrumentation design, not in a review after launch.
Review four layers together:
Quality: Evaluation results by task and failure dimension.
Behavior: Activation, successful completion, repeat use, abandonment, edits, and overrides.
Outcome: The customer or business result attached to the workflow.
Risk and reliability: Boundary violations, unsupported claims, tool failures, escalations, and consequential incidents.
Each layer corrects a possible misreading. High usage with weak quality can mean users are compensating for the system. Strong offline quality with little repeat use can mean the workflow is not important or the interaction arrives at the wrong moment. Completion without an outcome can mean the agent is accelerating work that should not have been done. Outcome movement without traceability makes it difficult to know whether the agent deserves credit or whether the result will persist.
Use qualitative evidence to explain those patterns. Review corrections and overrides, collect feedback at the point of use, and connect support signals to roadmap decisions. A generic satisfaction question is less useful than asking what evidence was missing, which step the user repeated manually, or why the recommendation could not be acted on.
When comparing user-facing variants, define the primary outcome and minimum detectable effect before running an A/B test. This prevents the team from declaring success based on an incidental movement in a convenient metric. A/B testing is appropriate only where traffic, exposure, and risk make controlled experimentation meaningful; rare or consequential actions need direct evaluation, review, and guardrails instead.
Make agent adoption an operating change
A launch campaign can create trials. It cannot resolve unclear ownership, weak evaluation, missing context, or a workflow that asks users to supervise the agent without giving them useful control. Sustainable adoption requires a product operating model around the capability.
Give a product trio responsibility for the complete workflow and pair it with the people who can close the distance between a prototype and production use:
Product management owns the user problem, target outcome, decision boundary, adoption contract, and expansion decision.
Design owns how intent, evidence, uncertainty, approval, correction, and escalation appear in the experience.
Engineering owns retrieval, tool permissions, system behavior, observability, release controls, and recovery paths.
A forward deployed engineer or equivalent customer-facing technical partner helps expose the real context, integrations, and exceptions hidden by a clean prototype.
Data and risk owners define acceptable model behavior, privacy constraints, access rules, and the evidence required for governance.
The leadership cadence should follow the learning loop. Discovery identifies a high-value workflow and pressure-tests it with user evidence. Pre-release review examines evaluations and failure modes. A narrow rollout tests the workflow with explicit human checkpoints. Operating reviews examine quality, behavior, outcomes, and incidents together. Expansion adds a capability, population, tool, or level of autonomy only when the prior boundary is performing as intended.
This model should influence AI hiring as well. A strong AI product candidate should be able to turn a broad ambition into a bounded workflow, define an evaluation rubric, separate model quality from product outcomes, place human judgment at the right decision, and explain what evidence would justify more autonomy. Prompt fluency without those skills is not product leadership.
Key takeaways
Start with one recurring, bounded workflow whose completion and outcome can be observed.
Write an adoption contract covering the user, trigger, delegated job, approved context, decision boundary, failure behavior, and expansion criteria.
Progress from explanation to recommendation, preparation, and bounded action only as evaluation and production evidence improve.
Version prompts, retrieval logic, tool definitions, and evaluation datasets with releases.
Instrument intent, context, tool calls, human intervention, completion, and downstream outcomes as one decision loop.
Scale when quality, repeat use, workflow outcomes, and risk controls agree – not when a demonstration attracts attention.
Your next move does not need to be a company-wide agent mandate. Put three candidate workflows through the six selection criteria. Choose the one with the clearest trigger, evidence, completion point, and decision boundary. Then write its adoption contract and evaluation set before funding a broad build. If the narrow workflow earns repeat use and improves its named outcome, you will have evidence for the next capability – and a repeatable method for every agent that follows.
You have AI pilots that demo well, enthusiastic teams asking for broader rollout, and executives expecting the investment to show up in operating results. Yet the closer you get to production, the longer the list of unresolved questions becomes: Who owns the workflow? How will quality be measured? What happens when the model is wrong? Can the economics survive real usage?
The next move is not to launch more pilots. It is to install a system that can repeatedly turn a validated use case into a governed, measurable, and improving production workflow. That system is what separates AI experimentation from mature deployment.
A successful pilot is not evidence of production readiness
AI adoption is already common enough that adoption itself tells you very little. Among more than 2,400 global customer service professionals, 82% of senior leaders invested in AI in 2025, 87% planned to invest in 2026, and only 10% described their deployment as mature. The sample is specific to customer service, so those figures are better used as a directional benchmark than as a universal maturity rate. The underlying execution problem applies much more broadly: buying or piloting AI is easier than making it dependable inside a core workflow.
A pilot is designed to answer a narrow learning question. Can the model classify this request, draft this response, summarize this record, or choose the next action under controlled conditions? Production has to answer a harder question: can the entire workflow create enough value, across ordinary and difficult cases, while remaining safe, observable, supportable, and economically sensible?
I use a simple test. If the team can describe the model but cannot describe the operating workflow around it, the work is still a prototype. A production case should make each of these elements explicit:
Outcome: The customer or business result that should improve, plus the current baseline.
Workflow boundary: Where AI enters, which decisions it may make, which systems it may use, and where its authority ends.
Quality standard: The evaluation cases, acceptance criteria, and failure categories that determine whether a release is good enough.
Safe failure path: What the system does when information is missing, a tool fails, a policy is triggered, or the requested action exceeds its authority.
Accountability: A named product owner for the outcome and a named operational owner for production performance.
Economics: The value created and the full cost of inference, retrieval, tools, review, support, and incident handling.
Learning mechanism: How production failures and user corrections return to the evaluation set and release process.
These are not finishing tasks to schedule after the model works. They are part of the product. Deferring them creates a predictable trap: the pilot looks increasingly impressive while the distance to a responsible launch quietly grows.
Do not confuse automation coverage with maturity, either. A system can handle many requests and still be immature if nobody can explain why it made a decision, detect a quality regression, contain a failure, or calculate the result. Conversely, a narrowly scoped workflow can be mature when its boundaries, controls, outcomes, and ownership are clear.
Promote each workflow through explicit maturity gates
Maturity should be earned workflow by workflow. An organization does not become mature because it has a central AI team, an approved model vendor, or a large portfolio. It becomes mature when important workflows can move through a repeatable sequence of decisions without relying on heroics.
Stage
Decision to make
Evidence required to advance
Reason to hold
Discover
Is this a valuable and appropriate problem for AI?
A defined user problem, current baseline, workflow map, risk classification, and initial build-versus-buy view
The use case is driven by model novelty, has no meaningful outcome, or depends on inaccessible data
Prove
Can the proposed workflow improve on the current process?
Representative evaluation cases, a working prototype, documented failure modes, and a controlled comparison with the baseline
Success appears only in curated demos, or the team cannot reproduce the result across realistic cases
Operate
Can the workflow run safely and reliably in production?
Monitoring, escalation, access controls, auditability, incident procedures, release controls, rollback, and an accountable operator
Failures cannot be detected or contained, or production responsibility is still ambiguous
Scale
Should usage, autonomy, channels, or organizational reach expand?
Sustained outcome improvement, acceptable quality and risk, validated economics, user adoption, and reusable operating components
Volume is growing faster than quality, cost, support capacity, or governance can be understood
The purpose of a gate is not to create a committee. It is to prevent enthusiasm, executive attention, or sunk cost from substituting for evidence. The domain team should be able to prepare the evidence as part of normal product development. Specialist review should become more demanding only as the possible consequence of failure increases.
Give every workflow a short deployment contract. Keep it in the same system where the team manages releases and evaluations, not in a presentation that disappears after approval. The contract should include:
The intended user, job to be done, business outcome, and current baseline.
The inputs the workflow accepts and the outputs or actions it may produce.
The actions that are prohibited, require confirmation, or must be routed to a person.
The data sources, retrieval rules, system permissions, retention rules, and privacy constraints.
The evaluation set, quality dimensions, acceptance criteria, and known limitations.
The failure taxonomy, escalation path, incident owner, and customer recovery procedure.
The prompt, model, retrieval, tool, and policy versions included in the release.
The production metrics, cost measures, rollout control, and rollback conditions.
The product owner, operational owner, and risk approvers.
The acceptance criteria will differ by workflow. A drafting assistant, an internal search experience, and an agent authorized to modify a customer account should not face the same bar. Base the bar on consequence, reversibility, detectability, and recovery. If an error can create an irreversible change, expose sensitive data, make a material commitment, or deny someone an important service, require an appropriate human authorization step rather than relying on average model performance.
The deployment contract also makes scope changes visible. Adding a new tool, data source, channel, language, model, or autonomous action is not merely more traffic. It changes the system’s failure surface. Update the contract, extend the evaluation set, and pass the relevant gate again.
Build three feedback loops before increasing autonomy
A mature deployment learns at three levels: whether the workflow creates value, whether its decisions meet the required standard, and whether the production system remains reliable. If any loop is missing, the team can collect impressive activity metrics while the actual product deteriorates.
Connect model behavior to a business outcome
Start with the baseline process, not an AI metric. If the workflow is intended to resolve a support request, qualify an opportunity, complete an onboarding step, or assist an employee, measure how that outcome happens without the new system. Otherwise, you will know that the AI generated output but not whether it improved anything.
Use a metric stack that separates outcomes from diagnostics:
Business outcome: The customer, revenue, cost, risk, or productivity result the investment is meant to change.
Workflow outcome: Completion, resolution, successful handoff, correction, rework, abandonment, or another measure of whether the task reached its intended end.
Quality and safety: Correctness, grounding, policy compliance, appropriate escalation, harmful failure, and user correction.
Economics: Cost per successful outcome, including model usage, infrastructure, external tools, human review, support, and remediation.
The layers diagnose different problems. A prompt change may improve an offline score without changing task completion. More automation may reduce handling work while increasing corrections. A cheaper model may lower inference cost but create enough rework to raise the cost per successful outcome. Do not compress those effects into one AI score.
When traffic and product conditions support an experiment, compare the AI workflow with the current experience. Define the decision metric and minimum detectable effect before running an A/B test. For lower-volume or higher-risk workflows, use controlled rollout evidence, expert review, and structured case analysis rather than pretending a small sample provides statistical certainty.
Turn evaluations into release criteria
An evaluation set is not a collection of attractive examples. It should represent ordinary work, difficult edge cases, policy boundaries, known failures, and the situations in which the system should refuse or escalate. Build it before optimizing the prompt so the team cannot unconsciously redefine success around whatever the prototype already does well.
For each case, record the expected behavior and why it is expected. Some outputs can be checked against a deterministic answer. Others need a rubric that distinguishes task completion, factual support, instruction following, tone, policy compliance, and escalation quality. Where reviewers can reasonably disagree, capture that disagreement instead of forcing false precision into a single label.
Use offline and online evaluation for different jobs. Offline evaluation protects releases by testing candidate changes against a stable set. Online evaluation reveals distribution shifts, new user behavior, integration failures, and outcomes that cannot be recreated fully before launch. Neither is sufficient on its own.
Version the entire behavior-producing system: model, prompt, retrieval configuration, knowledge snapshot, tools, policies, and routing logic. A model comparison is not meaningful if the surrounding system changed silently. For every proposed release, make the decision policy explicit: ship, hold, narrow the scope, expand gradually, or roll back. This is the practical core of eval-driven development with target metrics and a decision policy defined before launch.
Operate the workflow as a production service
AI introduces variable outputs, but it still depends on familiar production systems: identity, permissions, data pipelines, APIs, queues, search, external tools, and user interfaces. A model can appear to be wrong when retrieval returned stale information or a downstream tool rejected an action. Monitoring only the final text hides the failure that engineers need to fix.
Trace the workflow end to end. Subject to your privacy and retention rules, capture the release version, retrieval and tool events, policy decisions, response, escalation, user correction, and eventual workflow outcome. Monitor distributions and failure categories, not just averages. An acceptable overall score can conceal a serious regression for a particular intent, customer segment, channel, or action.
When the workflow depends on changing or private knowledge, connect it to governed retrieval instead of expecting the base model to contain the right answer. Use safe integration points for tools, least-privilege access, and explicit authorization for consequential actions. CI/CD, feature flags, canary releases, observability, audit trails, privacy controls, red teaming, and human review form a practical control plane for releasing changes without exposing the entire population at once.
Every material production failure should produce more than an incident ticket. Classify the failure, add or update the corresponding evaluation case, correct the prompt, retrieval, policy, tool, or interface responsible, and retest the workflow before restoring scope. That turns operational pain into a permanent improvement in the release system.
Use 30-60-90 days to build the scaling system
A useful 30-60-90-day sequence starts with two lighthouse use cases. The goal is not to force every use case into production within a quarter. It is to prove that your organization can move valuable workflows through the same gates, shared controls, and learning loops.
Days 0-30: narrow the portfolio and establish accountability
Inventory active pilots and classify each as discovery, proof, operation, or scale. Do not let a polished demo assign its own stage.
Select two lighthouse workflows using customer impact, feasibility, strategic relevance, and risk. Choose workflows meaningful enough to matter but bounded enough to operate responsibly.
Record the current process and baseline before the AI changes user or employee behavior.
Name the product owner, operational owner, and required risk decision-makers for each workflow.
Complete the first version of each deployment contract, including the autonomy boundary and safe failure path.
Make the build-versus-buy decision at the workflow level. Include data access, integration, auditability, evaluation portability, operating cost, and switching constraints.
Pause pilots that have no accountable owner, no measurable outcome, or no plausible route through the operating gate.
This first phase is where leadership earns focus. A broad AI mandate often creates a queue of unrelated prototypes, each with its own vendor, data assumptions, and definition of success. Choosing lighthouse workflows gives the platform and governance work a real customer instead of turning them into abstract architecture programs.
Days 31-60: install evaluation, controls, and workflow operations
Build the offline evaluation set from representative work, edge cases, policy boundaries, and failures already found during discovery.
Define acceptance criteria and the release decision policy before further prompt or model optimization.
Integrate the necessary retrieval and tools through governed access points. Keep permissions narrower than the user’s full access where the workflow does not need it.
Add observability across retrieval, reasoning inputs, tool execution, output, escalation, and business outcome.
Prepare feature flags, a controlled rollout, rollback, incident procedures, and a customer recovery path.
Run the workflow with appropriate human oversight. Record corrections and escalations as structured evidence, not informal feedback in chat.
Train the people who will supervise, support, and improve the workflow. Update operating procedures before transferring real responsibility to AI.
Training cannot be limited to prompt tips. Operators need to know what the system may do, how its failure modes appear, when to intervene, how to report a new failure, and who can change production behavior. Product and engineering teams need the same vocabulary for evaluation, incidents, and risk.
Days 61-90: expand evidence, not enthusiasm
Increase scope only for workflows that meet their operating gate. Expansion may mean more traffic, another intent, a new channel, or greater autonomy; evaluate each change explicitly.
Compare the production outcome and cost with the original baseline. Include corrections, review, support, and remediation in the economics.
Turn repeated needs into shared components such as model access, retrieval, identity, evaluation infrastructure, observability, policy enforcement, and audit logging.
Move validated production failures into the evaluation suite and confirm that the release process catches them.
Review job responsibilities, incentives, staffing assumptions, and training needs created by the redesigned workflow.
Hold a portfolio decision for every remaining pilot: advance, narrow, combine, pause, buy, or stop.
Organizational change is part of this phase. As AI altered customer service work, 45% of teams updated job descriptions and 40% increased AI training. That is a useful warning against treating adoption as an in-app onboarding problem. If AI takes responsibility for part of a workflow, someone must take responsibility for supervising it, handling exceptions, and improving the system.
Assign decision rights clearly. The domain product team should own the user problem, outcome, workflow design, evaluation cases, and adoption. A platform function should own shared access, retrieval, observability, release infrastructure, and policy enforcement. Risk specialists should define control requirements and review higher-consequence uses. The operational owner should manage quality, escalations, and incidents after launch. Executive leadership should decide portfolio priority, capacity, and which bets no longer deserve investment.
This structure avoids two common extremes. A fully centralized AI team becomes a delivery bottleneck and loses domain context. Fully independent teams duplicate infrastructure and apply inconsistent controls. Centralize reusable capabilities and non-negotiable policies; keep workflow outcomes and day-to-day learning with empowered domain teams.
Expect pressure to spread successful patterns. In customer service organizations, 52% planned to scale AI into areas such as customer success, marketing, and sales. Reuse the platform, governance, evaluation methods, and operating vocabulary. Do not copy a support workflow into another function and assume its value, risks, permissions, or quality bar remain valid.
FAQ: decisions that determine whether AI scales
Should AI be owned centrally or by product teams?
Use a federated model. Centralize capabilities that become safer, cheaper, or more consistent when shared: approved model access, identity, data controls, retrieval services, evaluation tooling, observability, auditability, incident standards, and risk policies. Embed workflow ownership in the domain team that understands the user, process, and business outcome. A central group can set the paved road, but it should not become the permanent product team for every AI use case.
When is an AI workflow ready for more autonomy?
Increase autonomy when the workflow has demonstrated acceptable behavior for the exact action and population being added, failures are detectable, consequences are containable, rollback works, and an operational owner can handle exceptions. Do not remove human review merely because the average quality score improved. Judge autonomy by the worst credible consequence, the reversibility of the action, and the system’s ability to recognize when it should stop.
Autonomy is not binary. The system can retrieve information, recommend an action, draft the result, ask for confirmation, execute within a limited permission, or execute and trigger retrospective review. Choose the narrowest level that captures the value. Expand only when evidence supports the next level.
When should a pilot be stopped rather than scaled?
Stop or reframe a pilot when it has no accountable workflow owner, cannot beat a meaningful baseline, works only on curated inputs, requires unacceptable access, has no safe failure path, or creates more review and remediation than the outcome justifies. Also stop when the supposed AI problem is actually a broken policy, missing data, or poorly designed process that should be fixed directly.
A failed autonomy concept can still reveal a useful assistive product. If execution is too risky, narrow the workflow to retrieval, recommendation, drafting, or exception detection. That is a product decision, not a face-saving exercise. The right scope is the one that creates measurable value under an operating model you can defend.
At your next AI portfolio review, ask each owner to bring a baseline, deployment contract, evaluation evidence, and a clear gate decision. Fund shared infrastructure where the lighthouse workflows expose a recurring need. Expand only after the operating evidence catches up with the demo. That is how you turn a collection of pilots into an AI capability that can carry real responsibility.
Trust is the currency of any high-stakes AI product, and nowhere is that more true than in healthcare. I recently dug into how Healio built an AI assistant for physicians—an audience that can’t afford to be wrong—and it’s a masterclass in balancing accuracy, transparency, and speed without compromising credibility.
Healio, a 125-year-old medical publishing company, set out to create Healio AI to help clinicians prepare for patient care. From the outset, their guiding principle was simple: physicians won’t trust you until you prove it. That lens shaped every decision—from discovery and prototyping to architecture, evaluation, and ongoing validation.
Discovery started with a survey of 300 healthcare professionals to understand real-world needs at the point of care. The headline insight: physicians primarily want AI for preparation, not bedside use. Even more surprising, the top ask wasn’t purely diagnostic support; it was help with patient communication and empathy—translating complex information into clear, accessible conversation.
Momentum mattered. After beginning with Figma mockups to validate workflows, the team built a working prototype in a single weekend using Cursor. That velocity wasn’t about cutting corners; it was about proving value quickly, reducing ambiguity, and iterating with concrete feedback from physicians.
Under the hood, the system employs RAG and hybrid search—combining lexical search, vector search, and semantic search across multiple trusted sources like PubMed. As any PM who has integrated biomedical literature knows, "just use PubMed" isn’t simple—there are five different ways to access the same data, each with trade-offs. The team made pragmatic choices to balance freshness, coverage, latency, and cost while preserving trust in source quality.
Designing for trust extended all the way to the citation UX. The team leaned into citations that physicians actually trust: subscripts, hover states, and progressive disclosure. This gave clinicians verifiable threads back to source material without overwhelming the core interaction, aligning with how experts want to audit evidence under time pressure.
Evaluation wasn’t left to chance. They stood up eight LLM judges for evals: safety, medical accuracy, faithfulness, relevancy, completeness, reasoning, clarity, and overall quality. Just as importantly, they treated those signals as directional, not definitive. In a high-stakes domain, physician feedback trumps LLM-as-judge feedback—so they complemented automated evals with direct reviews from practicing clinicians to calibrate quality and reduce hallucinations.
On the safety front, the team implemented HIPAA compliance and input guardrails for masking personal health information. That choice reflects strong data governance and privacy-by-design thinking: protect PHI by default, constrain prompts to safe boundaries, and make compliance a first-class citizen in the product architecture.
They also addressed monetization without compromising experience. Serving contextual ads while the LLM processes queries is a practical approach that preserves physician workflow efficiency and creates a clear, non-intrusive revenue model.
Critically, the work didn’t stop at launch. The Healio Innovation Partners provide ongoing discovery and validation, ensuring the system evolves with physician needs and the medical evidence base. This is the operating cadence you want for any AI product that sits at the intersection of safety, accuracy, and fast-changing knowledge.
My takeaways for building AI in high-stakes domains: prioritize retrieval-first pipelines over model cleverness; couple RAG with hybrid search across vetted sources; design citations that earn trust at a glance; use eval-driven development, but let domain-expert feedback be the ultimate judge; and embed regulatory compliance into your product strategy from day one. If trust is your North Star, this is a playbook worth emulating.
Your tender inbox contains a deadline, a stack of attachments, and a chain of decisions that still lives in people’s heads. The tempting response is to buy a model that can read PDFs. That solves only the most visible part of the problem.
A useful tendering product must determine which documents matter, extract requirements with evidence, match those requirements to a catalog, retrieve approved pricing, draft an offer, identify uncertainty, and route exceptions before anything reaches the customer. If you lead AI or product strategy for a manufacturer or supplier, your first goal should not be an autonomous bidder. It should be the smallest tender category in which every decision can be observed, evaluated, and improved.
Pick a bounded quote, not the entire tendering department
Construction tendering is too broad for a credible first release. Product categories have different terminology, selection rules, catalogs, pricing structures, and exception patterns. A system that works for one bounded category has not automatically learned how to quote every building product.
One effective wedge started with radiator requests for a single design partner before expanding to other building products. That constraint made the catalog, expected outputs, and expert reviewers knowable. It also created a place to learn the real workflow rather than designing from an idealized process diagram.
Choose your wedge using operational criteria, not enthusiasm for the model:
The request appears often enough for reviewers to recognize recurring patterns.
The relevant catalog is bounded and maintained by a clear owner.
A domain expert can explain why a product is suitable, unsuitable, or uncertain.
The correct price can be traced to an approved system or document.
Historical tenders and reviewer corrections are available for evaluation.
An error can be caught during review before it becomes a customer-facing commitment.
A design partner is especially valuable because the work is not fully documented. In one implementation, the product team spent a week observing the process on-site. That kind of observation exposes the browser tabs, informal checks, catalog shortcuts, and exception handling that an interview alone can miss.
Follow one tender from the incoming email to the final offer. At every handoff, record five things: the input, the decision, the evidence used, the person or system responsible, and the condition that triggers an exception. If you cannot state those five things, you do not yet have a well-defined agent task.
Keep three layers of information separate from the beginning:
Stated requirements: what the tender explicitly asks for, with the originating file, page, section, or table cell.
Interpretations: conclusions the system or reviewer draws when terminology is ambiguous, incomplete, or inconsistent.
Commercial decisions: the selected product, approved price, assumptions, exclusions, and offer language.
This separation matters because a polished offer can hide a weak inference. A reviewer needs to see where the tender ends and the system’s judgment begins.
Define the first outcome as a review-ready tender case: organized source documents, structured requirements, proposed product matches, price provenance, unresolved issues, and a draft offer. That is a more useful product boundary than “understands construction PDFs.” It gives the reviewer something concrete to accept, correct, or reject.
Turn the workflow into a decision graph with specialist agents
A chatbot is the wrong mental model. Tendering is a decision graph in which an early classification or extraction error can contaminate every downstream step. Real packages can range from a short request to more than 1,800 pages describing an entire building. The system therefore needs to plan work, retain state, reconcile evidence, and know when coverage is incomplete.
Use agents only where a task requires interpretation, planning, or exception handling. Keep exact operations – file handling, arithmetic, catalog queries, identifiers, template validation, and access control – in deterministic code or approved systems.
Stage
Preferred control
Required output
Intake
Rules plus a classifier
A tender case containing the email, attachments, document types, and routing status
Requirement extraction
Parser tools plus a specialist agent
Structured requirements with source locations, missing fields, and ambiguities
Product matching
Catalog retrieval plus a reasoning agent
Candidate products, requirement coverage, incompatibilities, and rationale
Pricing
Approved database, CPQ, or pricing service
Exact product-price records with source and validity information
Offer generation
Controlled template plus a drafting agent
A draft that distinguishes confirmed facts, assumptions, and exclusions
Quality review
Rules plus a separate review agent
A pass or block decision with issue codes and supporting evidence
Human approval
Domain and commercial policy
An approval, correction, rejection, or escalation that becomes evaluation data
Each agent should have an explicit contract. Specify its permitted inputs, tools, output schema, evidence requirements, completion test, and escalation behavior. “Find the right product” is not a contract. “Return catalog candidates that meet the extracted requirements, identify uncovered requirements, cite the catalog evidence, and abstain when no candidate qualifies” is much closer to one.
For large document sets, require the workflow to maintain a task plan. It should inventory files, identify relevant sections, process bounded units of work, track completed and pending units, reconcile repeated or conflicting requirements, and run a final coverage check. A generated answer is not proof that the package was fully processed.
The review agent deserves its own role. Asking the drafting agent to “check your work” keeps creation and approval inside the same reasoning path. A separate reviewer can inspect the draft against the extracted requirements, catalog evidence, price records, and policy rules. It should return defects and a gate decision rather than silently rewriting the offer. Silent rewriting makes it harder to identify which upstream component failed.
This pattern has practical value because a dedicated review agent can catch errors before human review, much like a separate code review step. Independence comes from the reviewer’s task and evidence contract; adding more agent personas without distinct responsibilities only creates orchestration overhead.
The interface is part of the architecture. During discovery, a dedicated web workbench can be more useful than hiding the workflow behind a legacy integration. Put the source document, extracted requirement, proposed match, price evidence, and review issue within the same review path. That gives the product team control over feedback capture and makes the reason for each correction visible. One tendering product used its own web application to iterate toward greater automation rather than beginning as a backend-only integration.
You can still read from and write to existing systems at defined boundaries. The distinction is between integration and dependence: integrate with systems of record for catalogs, prices, customers, and approved quotes, but do not let an inflexible legacy screen determine how reviewers inspect an emerging AI workflow.
Evaluate every decision before judging the complete quote
An end-to-end result tells you whether a tender case failed. It rarely tells you why. If the final product is wrong, the defect may have come from document routing, requirement extraction, catalog retrieval, product reasoning, pricing, drafting, or review. A single overall accuracy score collapses those failure modes into an unactionable number.
Pricing: exact agreement with the approved source, correct product-price association, formula validation, and rejection of unavailable or invalid records.
Offer generation: required-field completeness, consistency with selected products and prices, correct treatment of assumptions, and unsupported statements.
Review: detection of known defects, false blocks on valid cases, issue classification, and evidence quality.
Slice failures by characteristics that change the work: document length, file type, layout, product category, presence of tables, and conflicting or revised requirements. An aggregate score can improve while performance deteriorates on the long or unusual tenders that consume most reviewer attention.
Use end-to-end measures for the product outcome: review time, correction volume, correction severity, exception rate, percentage of cases that reach the defined completion state, and whether the workflow finishes before its operational deadline. Keep commercial outcomes separate from model correctness. Quote acceptance or win rate can be affected by price, availability, competition, customer relationships, and sales execution; it should not be treated as a clean extraction or matching metric.
Observability must connect those layers. For each tender case, retain the task plan, agent inputs and outputs, tool calls, retrieved catalog or price records, prompt and model versions, gate decisions, latency, failures, and human corrections. Complex agent chains can exceed what generic monitoring exposes, which is why custom tracing and Agent Analytics became necessary in a production tendering workflow.
Capture reviewer feedback as structured data, not only as an edited final document. Store the original output, corrected value, responsible stage, reason code, evidence used, and final disposition. Useful reason codes include missing requirement, incorrect extraction, unsupported product match, pricing issue, unresolved conflict, invalid assumption, and drafting defect.
Do not feed every edit directly back into the system and call it self-learning. A reviewer may change wording for preference, apply customer-specific knowledge, or correct an upstream error in the final draft. Validate the correction, assign it to the right component, and add it to the corresponding evaluation set. That turns human review into controlled learning rather than an untraceable feedback loop.
Release changes through two gates. First, the modified agent must pass its own evaluation set. Second, the complete workflow must pass the end-to-end set because an improvement in one component can change the assumptions of another. The trace should show exactly which version produced every customer-facing artifact.
Earn autonomy one commercial boundary at a time
“Straight-through processing” is incomplete unless you define where the straight-through path ends. Automatically extracting requirements is not the same risk as automatically selecting a product, committing a price, writing to the CPQ, or sending an offer to a customer.
Use an autonomy ladder with an explicit boundary at each stage:
Shadow: the system processes live-shaped cases, but its outputs do not affect the operational tender.
Assist: it organizes documents and extracts requirements while a person performs matching, pricing, and drafting.
Draft: it proposes products and produces an offer, but a human must review and approve every case.
Gated processing: it completes predefined internal actions for in-scope cases and sends all exceptions to a reviewer.
External dispatch: it sends an offer without case-by-case approval only when commercial policy explicitly permits that action and every required gate passes.
Eligibility for a higher-autonomy path should be machine-checkable. At minimum, confirm that the product category is in scope, every required document was processed, required fields are present, source evidence is attached, conflicts and revisions are resolved, the product match satisfies its evidence rules, the price comes from an approved valid source, the review agent reports no blocking defect, and the full trace is retained.
A wrong product or price can create margin, delivery, contractual, and customer-trust exposure. If an offer may create a binding commitment, keep human approval until the appropriate commercial and legal owners have defined the policy for automatic dispatch. The safe alternative is to automate preparation while preserving approval at the commitment boundary.
Operational controls matter after launch. Give reviewers a visible exception queue, make the reason for every block legible, preserve manual processing when the AI path is unavailable, and provide a way to suspend autonomous actions without disabling access to already processed cases. Assign owners for catalog quality, pricing validity, tender policy, model behavior, and production reliability; otherwise each exception will bounce between teams.
Expansion should follow evidence and customer pull. A request to replace an existing CPQ system is a meaningful product-market signal, but it is also a change in product scope. CPQ replacement introduces responsibilities for quote versions, approval policy, catalog administration, pricing governance, integrations, and records. Treat that request as a roadmap decision, not as proof that the original agent workflow already covers those capabilities.
Key takeaways
Start with one product category, one known workflow, and reviewers who can explain the correct decision.
Optimize first for a review-ready tender case, not an impressive answer from a general chatbot.
Use deterministic systems for exact operations and specialist agents for interpretation, planning, and exceptions.
Require structured outputs, source evidence, explicit completion tests, and an abstain-or-escalate path from every agent.
Evaluate each stage separately, then use end-to-end metrics to measure the operational outcome.
Increase autonomy only when observable eligibility gates protect the next commercial boundary.
At your next roadmap review, put one representative tender on the screen and draw the decision path from email to offer. Name the owner, evidence, pass condition, and exception path for every node. Wherever those are missing, the next task is workflow discovery, not another agent. Once the graph is explicit, you can automate one bounded decision, measure it, and earn the right to automate the next.
Your AI feature has passed the demo. Customers want it, leadership wants a date, and the team believes the remaining risks can be handled before launch. The problem is that nobody can state what evidence would make the feature safe enough to release – or who can stop it when that evidence is missing.
This is where AI ethics has to become product governance. You need a repeatable way to classify risk, set release conditions, assign decision rights, test safeguards, and respond when production behavior differs from the demo. The goal is not to eliminate uncertainty. It is to make uncertainty visible and govern the consequences.
Start with a release contract, not a list of principles
For each AI capability, write a short release contract before implementation begins. It should answer:
What decision or task is the product helping with? Describe the user outcome, not the model output. Generating a response is an output; helping a support agent resolve a request accurately is an outcome.
What must the system never do? Name unacceptable behavior such as exposing restricted data, presenting unsupported claims as facts, acting without required confirmation, or concealing that AI influenced an outcome.
Who can be affected? Include people represented in the data, people discussed in generated content, employees asked to rely on the output, and anyone subject to a downstream decision.
How consequential is a wrong result? Separate an inconvenient suggestion from an output that can affect access, money, employment, safety, privacy, or another difficult-to-reverse outcome.
What evidence is required to ship? Tie every material risk to an evaluation, control, review, or operational test. Avoid release criteria such as reasonable quality or adequate safeguards; two reviewers can interpret those phrases differently.
What will stop or reverse the feature? Define the conditions for disabling an action, reverting a version, narrowing availability, or returning the workflow to human handling.
Treat these conditions as part of the acceptance criteria. If a trust condition fails, the feature has not passed release readiness even when its primary quality metric looks strong. That keeps ethical constraints from becoming optional work negotiated away at the end of the schedule.
Classify the use case by consequence, autonomy, and reversibility
A model does not have one fixed risk level. The same underlying model can draft a headline, recommend an account action, or execute that action. Governance should therefore follow the use case rather than the model name.
A practical classification starts with three questions:
Consequence: What happens if the output is wrong, biased, misleading, or disclosed to the wrong person?
Autonomy: Does the system inform a person, recommend a decision, or take the action itself?
Reversibility: Can the affected person notice the result, challenge it, and restore the prior state without disproportionate effort?
Use those answers to choose a product path. A reviewable drafting aid may rely on disclosure, editing controls, standard evaluations, and ordinary monitoring. A consequential recommendation needs stronger evidence, an accountable human reviewer, and a clear appeal or correction path. An autonomous, hard-to-reverse action should not launch until the team can justify the autonomy, constrain permissions, require confirmation where appropriate, and demonstrate a reliable override.
Do not confuse a human in the workflow with meaningful human oversight. A person who lacks context, time, authority, or a usable way to reject the output is functioning as a rubber stamp. For higher-risk actions, the reviewer needs the evidence behind the recommendation, a clear indication of uncertainty or limitations, and the authority to choose a non-AI path.
Record the classification in an AI risk register. Each entry should contain the risk scenario, affected parties, possible impact, warning signals, preventive control, detection method, response, owner, required evidence, residual risk, and the person authorized to accept that residual risk. A model defect belongs in the backlog; a plausible future failure belongs in the risk register; a failure already affecting users belongs in incident management. Keeping those states distinct prevents serious risks from disappearing into a generic bug queue.
Likelihood will often be uncertain before production. Do not turn that uncertainty into a convenient low-risk label. Record what is unknown, how the team will test it, and which production signal will cause a review. For a consequential or difficult-to-reverse feature, I would also separate the person implementing the control from the person accepting the remaining risk.
Turn governance into four evidence-based release gates
A governance meeting should inspect evidence, not collect reassuring opinions. Four gates cover the path from data collection to production response. The depth of each gate should match the use-case classification.
Data gate: prove that the inputs are governed
Trust problems often begin before a prompt reaches the model. The data gate should make the full path of customer and organizational data inspectable.
Document what data is collected, where it came from, why it is needed, and which product purpose it serves.
Identify the applicable basis for processing and make consent flows explicit where consent is used. Legal requirements depend on the product, data, and jurisdiction, so product teams should validate this with qualified privacy and legal partners rather than infer an answer from a generic checklist.
Remove fields that are not needed for the stated outcome. Data minimization reduces both privacy exposure and the number of inputs that can produce unexpected behavior.
Map data lineage across ingestion, retrieval, model calls, logs, analytics, support tools, and vendors. A deletion promise is not credible if the team cannot locate every copy.
Apply role-based access to raw inputs, retrieved context, generated outputs, and operational logs. Access to the application should not automatically imply access to all AI interaction data.
Set retention and deletion rules, then test that they work across the full data path rather than only in the primary database.
The gate passes when the team can trace an input, explain its permitted use, name who can access it, and show how it is removed. A policy document without an enforceable data path is not sufficient evidence.
Model gate: test the failures that matter to the use case
Map every important risk in the register to an evaluation. If a risk has no test, state which manual review or production control provides the evidence instead.
Define the passing condition before reviewing final results. Moving a threshold after seeing a disappointing result turns a gate into a negotiation.
Test normal requests, ambiguous requests, edge cases, adversarial prompts, and realistic multi-step interactions. A polished set of happy-path prompts will not expose operational failure modes.
Compare performance across the user groups and contexts relevant to the product. Aggregate quality can conceal a meaningful gap affecting a smaller group.
Red-team prompts, retrieved context, tool use, and permission boundaries. For an agentic workflow, the safety of the text is only one part of the problem; the allowed action is another.
Keep the evaluation set and results tied to the model, prompt, retrieval configuration, tools, and policy version that produced them. Otherwise, a passing report can outlive the system it evaluated.
When an LLM must answer from known organizational information, a retrieval-first pipeline can ground the response in authoritative material. It does not remove the need for evaluation. Test missing documents, conflicting documents, stale content, access-restricted content, and questions the knowledge base cannot answer. The safe behavior may be to abstain, ask for clarification, or route the task to a person.
Experience gate: help users exercise judgment and control
Disclosure is useful only when it changes what a person can understand or do. Place it near the AI-assisted decision, in plain language, and explain the limitation that matters in that moment. A broad statement hidden in terms and conditions does not help a user assess a specific output.
Make it clear when AI generated, transformed, recommended, or acted on information.
Let users inspect, edit, reject, or correct an output before a consequential action where that control is meaningful.
Separate generated content from verified facts in the interface. Do not use confident UX writing to imply certainty the system cannot support.
Explain what data the feature needs and what changes when the user turns it off.
Provide a non-AI or human-assisted path when the AI path is unsuitable for the task.
Test whether users understand the system’s role. A control that exists but cannot be found or understood is not an effective safeguard.
Match the amount of friction to the consequence. Requiring confirmation for every low-impact suggestion can train users to click through automatically. For a high-impact or hard-to-reverse action, the extra pause may be the safeguard that preserves meaningful control.
Operations gate: demonstrate that failure can be contained
Pre-launch evaluations cannot cover every production context. The operations gate determines whether the team can detect, contain, and learn from behavior that escaped testing.
Monitor model behavior and customer impact. Technical availability can look healthy while unsupported outputs, harmful actions, or repeated user corrections are increasing.
Assign an owner and response for each alert. An unowned dashboard is visibility without control.
Create a kill switch or permission cutoff for risky actions, plus a rollback path for model, prompt, retrieval, and tool changes.
Test the rollback under realistic access and dependency conditions. A safeguard that nobody has exercised may fail during the incident it was meant to contain.
Prepare an incident playbook covering triage, containment, evidence preservation, affected-user assessment, communication, recovery, and the decision to restore service.
Keep a human override for high-risk actions and verify that the operator can use it without depending on the failing AI path.
This gate passes when the team can answer three questions without improvising: How will the failure be detected? Who can stop it? What evidence is required before it is turned back on?
Assign decision rights across the product lifecycle
Governance slows teams when everyone can raise concerns but nobody knows who decides. Put decision rights beside the risk register and release gates.
Product: owns the intended outcome, use-case classification, release contract, customer trade-offs, and completeness of the risk register.
Engineering and data: produce evidence for system behavior, data lineage, access controls, evaluations, technical constraints, and remediation.
Design and research: verify disclosure, comprehension, correction, appeal, and user control in the actual workflow.
Security and privacy: examine access, abuse paths, data handling, vendor exposure, and response controls.
Legal and compliance: interpret applicable obligations and identify where a product decision creates legal exposure. Product leaders should bring these partners in while choices are still reversible.
SRE and operations: own observability, alerting, rollback mechanics, incident readiness, and production recovery with the product team.
Executive risk owner: accepts material residual risk when the decision exceeds the product team’s authority and ensures that the required mitigation has resources.
The review itself should be a decision forum, not a status meeting. Send the release contract, risk register, failed and passed evaluations, unresolved questions, and requested decision in advance. End with one of four outcomes: approved, approved with explicit conditions, returned for more evidence, or rejected. Record the rationale and the event that will trigger another review.
Apply the same discipline to purchased models and AI services. A vendor can operate part of the stack, but it cannot absorb your accountability to customers. Due diligence should cover model provenance, data use and retention, access, evaluation evidence, incident history, change notification, and subcontracted dependencies. Contracts should carry operational commitments such as service levels, deletion obligations, audit rights, and incident responsibilities into the vendor relationship.
If a vendor cannot answer a material question, record the item as unknown. Do not silently translate missing evidence into low risk. Decide whether a compensating control – limited data, narrower permissions, independent evaluation, or a manual workflow – makes the unknown acceptable. If not, change the design or supplier.
Treat launch approval as a monitored, reversible decision
Approval should attach to a defined system configuration and use case, not to the feature name forever. A model change, system-prompt change, new retrieval corpus, broader user group, expanded data access, new tool permission, or shift from recommendation to autonomous action can invalidate earlier evidence. Put those change triggers in the original approval.
Launch with the smallest exposure that can produce useful operational evidence. Watch model-quality signals alongside user corrections, overrides, complaints, unexpected actions, access violations, and downstream customer impact. Set an owner and response for each signal before rollout. Waiting for a broad satisfaction metric to move can leave a concentrated harm hidden inside an apparently successful launch.
Customer trust also depends on what you reveal outside the internal review. A customer-facing trust center can publish the AI system’s role, material limitations, relevant data practices, available controls, change history, and a path for reporting problems. Model facts, limitations, and change logs make responsible operation visible. Candor about a boundary is more useful than a vague claim that the system is responsible or safe.
Key takeaways
Govern the use case, not the model in isolation. Consequence, autonomy, and reversibility determine the controls you need.
Pair every success metric with an unacceptable outcome and observable release condition.
Use one living risk register to connect risk scenarios, evidence, owners, safeguards, residual risk, and review triggers.
Require evidence across data, model behavior, user experience, and production operations before release.
Treat human oversight as a designed capability. The reviewer needs context, time, authority, and a usable alternative.
Carry governance into vendor selection, contracts, monitoring, incident response, and material system changes.
Take one AI item from your current roadmap and write its release contract before the next planning or governance meeting. Name the intended decision, unacceptable outcomes, affected people, required evidence, stop conditions, and accountable risk owner. Any blank you cannot fill is not paperwork still to complete. It is product work you have found before customers find it for you.