Package supply chain security is not simply a matter of choosing reputable libraries. The practical challenge is controlling an expanding dependency graph, the code that executes during installation, the resources that installed software can reach, and the automated tools allowed to make those decisions.
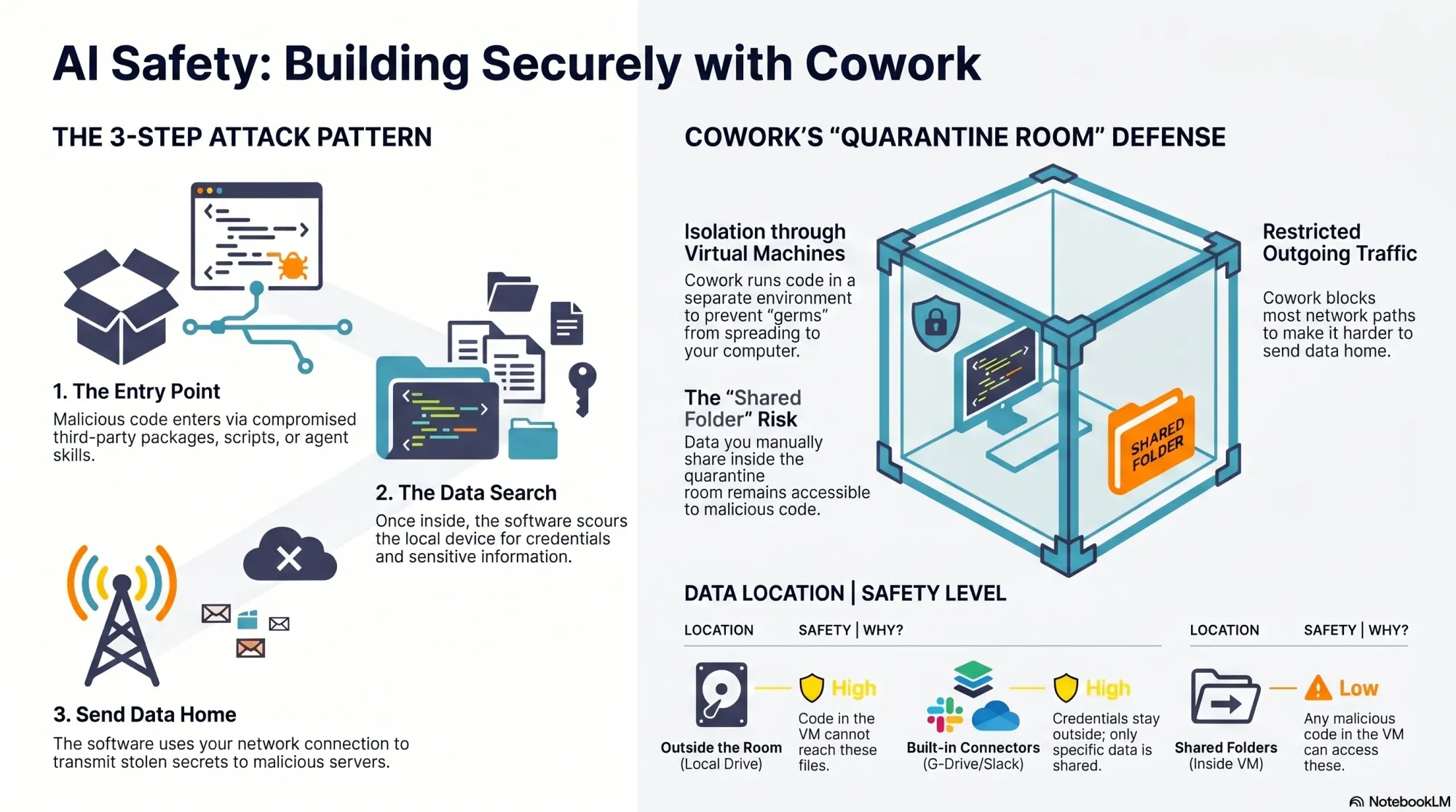
A useful defensive model follows the path an attack must take: enter through a package or dependency, execute in the development environment, discover valuable information, and transmit it elsewhere. Organizing safeguards around that sequence produces a stronger posture than relying on any single scanner, sandbox, or package reputation signal.
Package risk grows through the dependency graph
Developers usually evaluate the packages they select directly. The less visible risk lies in transitive dependencies: packages installed because another dependency requires them. The source article illustrates the scale of this effect by reporting that installing Jest brought in 266 packages. That example is not evidence that those dependencies were malicious; it shows how one deliberate choice can create hundreds of additional trust relationships.
This changes the unit of review. The relevant question is not only whether a named package appears legitimate, but whether its complete dependency graph is proportionate to the job. A small utility that introduces unfamiliar native modules, unrelated capabilities, or an unexpectedly broad tree deserves more scrutiny than its simple interface might suggest.
Manifests such as package.json, pyproject.toml, and requirements.txt make dependency installation repeatable. Repeatability alone, however, does not guarantee safety. If version ranges or unresolved transitive dependencies allow later releases to enter automatically, two installations based on the same manifest can produce different risk profiles. Pinning direct and transitive versions converts an evolving external graph into a more deliberate, reviewable input.
Match defenses to the stages of a package attack
The source article says an analysis covering more than 230,000 malicious-code incidents found a recurring pattern: malicious code first needs an entry point, then searches the device for sensitive data, and finally uses a network connection to exfiltrate what it finds. This reported pattern suggests three distinct control points.
Reduce risky entry and automatic execution
A waiting period for newly published packages can reduce exposure to releases that have not yet attracted community scrutiny. The article recommends installing only packages that are at least seven days old. That is a risk filter, not a guarantee: an older malicious package can remain undetected, while a legitimate urgent fix may occasionally justify an exception.
Installation scripts require separate treatment because they may execute before a developer has inspected the installed code. Disabling automatic install hooks by default creates a decision point. A package that depends on a post-install action can still be used, but the script, its purpose, and the capabilities it invokes should be reviewed first.
Constrain access after installation
Pre-install review cannot catch every problem. The next layer limits what package code can inspect or modify if it does execute. Sandboxed folders and isolated development environments can reduce the blast radius, but the source cautions that isolation by itself does not prevent malicious code from entering. Access boundaries therefore complement package controls rather than replace them.
Limit unnecessary network egress
Stolen information has less value to an attacker if malicious code cannot transmit it. Restricting unnecessary outbound connectivity addresses the final stage of the reported pattern. This layer matters because a package may evade provenance review and execute inside an environment despite earlier controls. Entry controls, resource boundaries, and egress restrictions together create independent opportunities to interrupt the attack.
Provenance is a decision process, not a trust badge
No single popularity or identity signal proves that a release is safe. The source proposes evaluating maintainer history, download patterns, repository activity, signed releases, and consistency across registries. Their value comes from comparison: a sudden change in maintainership, an unusual release pattern, or a mismatch between repository and registry information may warrant investigation even when each signal looks plausible in isolation.
Context also matters. Dependency behavior should be compared with the package’s stated purpose. A capability that is normal for a database driver may be difficult to justify in a formatting utility. This purpose-to-capability test helps teams focus limited review time on anomalies rather than treating every dependency as equally suspicious.
These checks work best when they lead to a clear disposition: approve the package and lock the reviewed version, replace it with a narrower dependency, inspect it more deeply, or decline it. Provenance information without a decision rule can become documentation that does not change behavior.
AI coding agents must inherit the same installation policy
AI-assisted development introduces a governance problem as much as a technical one. A coding agent may be able to select and install a package while pursuing a larger task, compressing several human decisions into one automated action. If it can also reach broad areas of the file system and use the network, a malicious dependency may encounter a larger potential blast radius.
The source describes workflows in which Claude searches, creates, and edits files across a broad knowledge system, including notes derived from downloaded PDFs. That breadth provides productivity value, but it also makes one-folder isolation impractical for the reported workflow. The proposed response is disciplined configuration: hooks require the agent to follow the same package-age, install-script, provenance, and dependency rules expected of a human developer.
This principle is more durable than a rule tied to one assistant. Package policy should apply consistently whether an installation is initiated by a developer, an AI agent, a local automation script, or a build process. The initiator may change; the acceptable evidence, permissions, and exceptions should not.
Key takeaways
- Review the full dependency graph, because the packages selected directly represent only part of the installed attack surface.
- Use a waiting period for new releases as one filter, while preserving a documented path for justified exceptions.
- Prevent install scripts from running automatically until their purpose and behavior have been examined.
- Combine provenance checks with a purpose-to-capability test and an explicit approve, investigate, replace, or reject decision.
- Pin direct and transitive versions, then run recurring audits to detect issues discovered after installation.
- Apply the same package rules to coding agents, automation, local development, and build environments.
- Layer installation controls, resource constraints, and network egress limits so that one missed signal does not determine the outcome.
A mature package security posture will increasingly depend on making these controls routine and machine-enforceable. As development becomes more automated, the teams best positioned to move quickly will be those that turn package trust from an informal judgment into a consistent operating policy.