Your team has hit its release dates, the roadmap is moving, and the launch calendar is full. Then someone asks the question that exposes the problem: what changed for the customer or the business? If the answer is a list of shipped features, activity is visible but progress is still uncertain.
Outcome-driven product development closes that gap. It gives a team a measurable problem to solve, enough freedom to change its solution as evidence changes, and a clear point at which exploration should become committed delivery. The result is not less shipping. It is less investment in work that has never earned the right to scale.
Replace the feature request with an outcome contract
A feature describes what the team will produce. An outcome describes the change the team intends to cause. That distinction sounds simple, but it changes planning, discovery, measurement, and accountability.
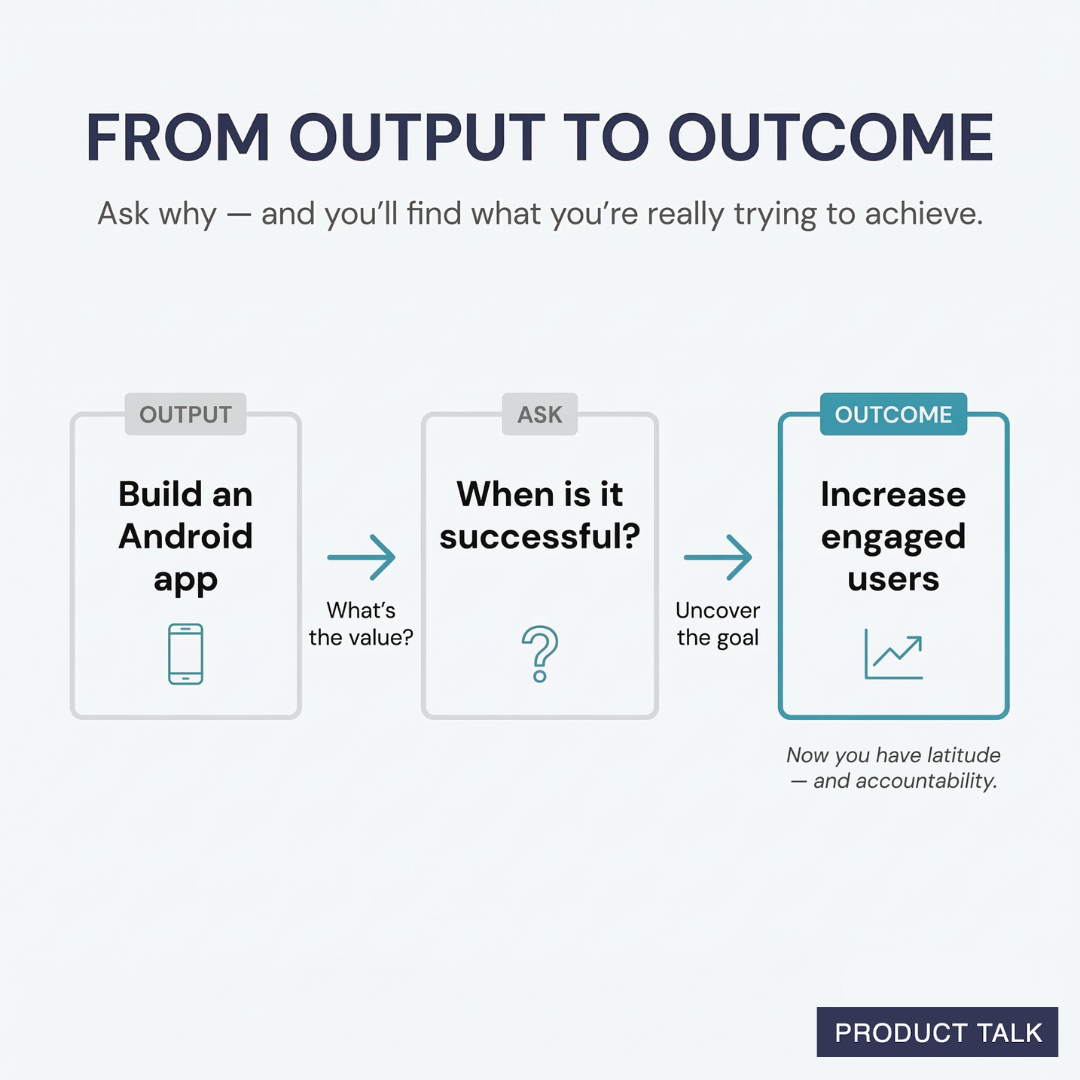
Suppose the roadmap says, “Launch an AI onboarding assistant.” The statement has a deliverable, but it leaves the important questions unanswered. Which customers are struggling? What behavior needs to change? How will the assistant cause that change? What evidence would justify continued investment? What must not get worse?
Rewrite the request as an outcome contract before discussing scope. A useful contract contains:
- Target customer and context: the specific user or account segment experiencing the problem, plus the situation in which it occurs.
- Problem evidence: the interviews, behavioral data, support patterns, or other observations showing that the problem is real.
- Behavioral outcome: the customer action that should become more frequent, successful, or efficient if the problem is solved.
- Business connection: the reason that behavior matters to activation, conversion, retention, revenue, cost, or another strategic result.
- Baseline, target, and measurement window: the current state, the intended direction or threshold, and the period over which the change will be assessed.
- Guardrails: the customer, operational, financial, ethical, or reliability measures that must not deteriorate while the primary metric improves.
- Decision point: the evidence that will trigger scaling, iteration, another experiment, or stopping the work.
The rewritten AI onboarding bet might be: “For new workspace administrators who struggle to complete setup, increase the share who reach their first useful workflow during onboarding, without increasing support demand or incorrect automations.” The assistant is now one possible solution, not the definition of success.
That wording gives the team room to discover that a checklist, better defaults, a guided setup flow, clearer copy, or a narrower AI capability solves the problem more effectively. It also prevents a common failure mode: launching the requested feature and retroactively selecting whichever metric happened to move.
Use three tests before accepting an outcome:
- If the proposed feature disappeared, would the stated customer and business result still matter?
- Can the team observe the target behavior with enough precision to distinguish exposure, use, and successful completion?
- Does the team have permission to change the solution while preserving the outcome and agreed constraints?
If any answer is no, you probably have a feature commitment decorated with outcome language. Fix that before the roadmap item absorbs a delivery team.
Use an evidence gate between learning and earning
Outcome-driven teams still build. The important choice is what they are building for at each moment.
In build-to-learn mode, the objective is to reduce uncertainty cheaply. The team is trying to understand the problem, test whether a solution is desirable and usable, and expose delivery or business risks before making a large commitment. Customer interviews, lightweight prototypes, assumption mapping, an opportunity solution tree, and narrowly scoped experiments belong here.
In build-to-earn mode, the objective changes to dependable value capture. The team has enough evidence to invest in production quality, integration, operational readiness, adoption, and scale. Acceptance criteria, sprint planning, release discipline, observability, and post-launch measurement become central.
These are modes of investment, not separate departments. A product trio can move between them as confidence changes. The practical goal is to learn only until the evidence supports conviction, then move decisively into value capture while keeping discovery alive.
Make every learning activity answer a decision
Discovery becomes theater when teams collect feedback without specifying what the feedback will change. Give each experiment a compact brief:
- Hypothesis: what the team currently believes about the customer, problem, solution, or expected behavior.
- Riskiest assumption: the belief most likely to invalidate the bet if it is wrong.
- Method: the cheapest credible way to test that assumption.
- Evidence: the observable result that would strengthen or weaken confidence.
- Timebox: the boundary that prevents exploration from continuing without a decision.
- Next action: scale, revise, run a different test, or stop.
Match the method to the question. Interviews can reveal whether a problem exists and how customers describe it, but they do not prove that a shipped solution will change behavior. A prototype can expose comprehension and usability problems, but it does not establish durable adoption. An A/B test can quantify incremental impact when exposure, instrumentation, and analysis are suitable, but it cannot rescue a weak problem definition.
An opportunity solution tree helps keep those questions connected. Start with the outcome, map the customer opportunities that could influence it, attach possible solutions to those opportunities, and place experiments under the assumptions they test. This makes it easier to notice when a favored solution has become detached from the original problem.
Define the evidence gate before enthusiasm takes over
There is no universal discovery duration or confidence score. The appropriate threshold depends on the cost, reversibility, operational risk, and strategic importance of the decision. A narrow, reversible change should not face the same gate as a platform migration or a customer-facing AI system with meaningful risk.
The team is usually ready to enter build-to-earn mode when it can answer yes to these questions:
- Is the target problem supported by evidence from the intended customer segment?
- Does the proposed solution reliably address that problem in the contexts tested so far?
- Has the team observed a credible leading signal connected to the desired behavior?
- Can the outcome, baseline, primary measure, and guardrails be instrumented?
- Are delivery, operational, and business risks understood well enough to make a commitment?
- Is the expected value sufficient to justify production investment and opportunity cost?
Do not wait for certainty; product decisions never get it. But do not confuse executive sponsorship, customer enthusiasm, a polished prototype, or engineering progress with evidence that the bet will produce the intended result. If the gate is not met, fund the next learning step rather than pretending the full solution is ready to scale.
The transition does not have to happen all at once. A team can productionize a narrow use case while continuing to test adjacent opportunities. What matters is that learning work and scaling work are identified honestly, funded deliberately, and judged by different standards.
Run discovery and delivery as one product system
An outcome will not survive if strategy, discovery, delivery, and stakeholder management operate as separate handoffs. It needs an operating model in which the same people retain context from the problem through the impact review.
Organize the work around an empowered product trio: product management, design, and engineering jointly own the outcome and the evidence behind the solution. That does not erase specialist responsibilities. It removes the pattern in which product writes requirements, design decorates them, and engineering discovers the hard constraints after the decision has already been presented as final.
Discovery and delivery should run as coordinated tracks. While validated work moves through implementation, release, and adoption, the trio continues testing the assumptions behind upcoming bets and watching what released behavior teaches them. This preserves learning without making committed delivery wait for every future question to be answered.
Maintain a compact bet record for every meaningful investment. It should show:
- the customer problem and strategic outcome;
- the current solution hypothesis;
- the evidence gathered so far;
- the assumptions that remain unresolved;
- the current mode: learning or earning;
- the next decision and the evidence required to make it;
- the primary metric and guardrails;
- the delivery constraints and dependencies that materially affect the bet.
This record should travel into roadmap and sprint decisions. A roadmap then becomes a sequence of outcome bets, ordered by expected leverage, evidence, dependencies, and strategic fit. Sprint work remains concrete, but each significant task can be traced to the hypothesis it supports. That traceability exposes orphan features: work with no defined problem, no testable belief, and no measurable result.
Turn stakeholder reviews into decision reviews
Stakeholders usually ask for feature certainty because feature status is what the operating system gives them. Change the review format and the conversation changes with it.
For each bet, report the outcome, the evidence gained since the previous review, the decision that evidence supports, the largest remaining risk, and the delivery forecast when the work is in earn mode. Then ask:
- Has the customer problem or strategic priority changed?
- Did the latest evidence increase or reduce confidence?
- Is the team still testing the highest-risk assumption?
- Has new scope appeared without a corresponding outcome or risk reduction?
- Does the next investment buy learning, value capture, or neither?
This is also how you control scope without turning every discussion into a negotiation. New work must improve the expected outcome, address a documented risk, or satisfy an explicit constraint. If it does none of those things, it belongs outside the current bet.
A stakeholder can still impose a solution for regulatory, contractual, architectural, or strategic reasons. Record that constraint plainly. Then preserve the team’s responsibility for validating the problem, minimizing unnecessary scope, instrumenting the result, and reporting whether the mandated solution actually changed behavior.
Instrument the decision loop, not just the launch dashboard
A release is evidence that the team produced something. It is not evidence that customers encountered it, understood it, used it successfully, or changed their behavior because of it.
Build a metric chain before production work becomes expensive:
- Business result: the strategic effect the company ultimately cares about.
- Customer behavior: the action expected to contribute to that result.
- Product signal: the observable event or state that indicates the behavior occurred successfully.
- Capability: the shipped solution intended to influence the signal.
If retention is the business result, successful setup or repeated use might be an earlier behavioral signal. That relationship is still a hypothesis in your product. Do not assume a leading indicator matters merely because it is easy to move. Validate its connection to the downstream result over an appropriate measurement window.
Before release, define who is eligible, how exposure will be recorded, what successful use means, which segment will be analyzed, what baseline or comparison will be used, and which guardrails could stop expansion. Verify the instrumentation itself. Otherwise, a missing event can be mistaken for missing adoption, while duplicate or ambiguous events can create fictional progress.
Where traffic and exposure permit, an A/B test can estimate whether the capability caused an incremental change. Where randomization is not practical, a staged release, cohort comparison, or carefully monitored pilot can still provide directional evidence, provided its limitations are stated. In either case, observability should cover both customer behavior and the operational health of the released system.
Use the post-launch review to make a decision, not to celebrate a dashboard. Work through the causal chain in order:
- No meaningful exposure: investigate eligibility, distribution, rollout, onboarding, or instrumentation before judging the solution.
- Exposure without use: examine relevance, comprehension, trust, discoverability, and usability.
- Use without the intended behavior: challenge the solution mechanism and the definition of successful use.
- Behavior change without the business result: reassess the assumed link, segmentation, and measurement window.
- Primary improvement with guardrail damage: pause expansion and address the tradeoff rather than averaging the harm away.
These are diagnostic starting points, not automatic conclusions. Their value is that they direct the next investigation. The review must end with an explicit choice: expand, continue observing, revise the solution, test a different opportunity, or stop investing.
AI changes the cost of learning, not the evidence standard
Generative AI can make prototypes, interface variants, and qualitative synthesis much faster. That is useful because it lowers the cost of testing assumptions. It also makes it easier to produce a convincing solution before anyone has established that the problem deserves investment.
Treat an AI-generated prototype as a learning instrument, not customer validation. A plausible interface or polished response does not show that customers will trust it, incorporate it into their workflow, or achieve a better result. Those questions still require evidence from the intended users and context.
For an AI-powered feature, separate system quality from product outcome. Prompt changes, model changes, response quality, and task-level evaluations can explain how the capability behaves. The customer outcome tells you whether that capability improved the workflow that matters. A better model-level result can coexist with a flat customer outcome if the feature addresses the wrong problem, appears at the wrong moment, or creates too much friction around the generated output.
Keep risk guardrails beside the primary outcome from the beginning. The relevant guardrails depend on the use case, but they should capture the ways an apparently successful AI feature could create unacceptable customer, operational, ethical, or business consequences. Faster experimentation is valuable only when the decision loop can detect both value and harm.
Outcome-driven product development FAQ
What if an executive has already specified the feature?
Treat the feature as a proposed or mandated solution, then ask what result makes it worth building. Document any non-negotiable constraint and write the outcome contract around it. Offer alternatives when discovery shows a cheaper or more effective route, but do not hide the original decision. The team should still instrument the feature and report whether it delivered the intended behavior.
How long should discovery take?
Long enough to cross the evidence gate for the decision being made, and no longer. Timebox each experiment, not the truth of the entire opportunity. A reversible, limited bet may need modest evidence; an expensive or risky commitment warrants more. If discovery continues without changing confidence or informing a decision, narrow the question or stop the activity.
Can an outcome-driven team still commit to a delivery date?
Yes, once the work is in build-to-earn mode and the important delivery unknowns are bounded. Keep the delivery forecast separate from outcome confidence. A team may be highly confident about when a capability will ship while remaining uncertain about the behavior it will cause. Reporting both prevents schedule confidence from being mistaken for product confidence.
What should happen when the outcome does not move?
Start with exposure, then use, then behavior, then the business connection. Identify where the chain broke before adding scope. If the evidence weakens the underlying hypothesis, revise or stop the bet. Outcome accountability means changing course when the mechanism fails, not punishing a team for refusing to manufacture a favorable story.
At your next roadmap review, take the highest-investment item and replace its feature description with an outcome contract. If the problem evidence, behavioral measure, guardrails, or decision rule is blank, fund the missing learning before you fund scale. That single change will reveal whether the roadmap is managing customer and business progress or merely scheduling production.
References