Heading to ProductCon San Francisco 2025? I approach conference travel the same way I approach product strategy: optimize for outcomes, reduce friction, and invest in high-signal experiences. Here’s the playbook I use to choose the right hotel, find memorable meals, and make the most of every hour in the city.
For lodging, I prioritize walkability, safety, and quiet rooms so I can focus during sessions and recover at night. If you want to be steps from most venues and meetups, SoMa and the Yerba Buena corridor are ideal. InterContinental San Francisco, W San Francisco, and The Clancy (Autograph Collection) are reliable, business-friendly picks with strong Wi‑Fi and ample lobby space for impromptu one‑on‑ones. If you prefer classic energy and transit access, Union Square hotels like Hotel Nikko and The Westin St. Francis work well. For waterfront views and a calmer vibe, Hyatt Regency Embarcadero puts you by the Ferry Building with easy BART and Muni access.
My booking checklist is simple: reserve early, target a high floor away from elevators, and request early check‑in or late checkout around your session schedule. Loyalty programs often unlock better rates and quiet‑room preferences. If you need heads‑down time between talks, ask about day‑use meeting rooms or find a corner of the lobby with stable bandwidth. I also pack a compact power strip and a long USB‑C cable—two small upgrades that routinely save a day.
Coffee is the fuel of great product conversations. Near SoMa, I rotate between Blue Bottle (Mint Plaza), Sightglass (7th Street), and Philz (Front Street) for pre‑session caffeine and quick stand‑ups. If I’m on the Embarcadero side, the Ferry Building’s roasters are perfect for early starts, and morning lines move faster than you’d expect if you arrive just after opening.
For efficient lunches, I favor fast‑casual spots that can handle volume without sacrificing quality. Mixt, Souvla, Sweetgreen, Super Duper Burgers, and The Grove are dependable within a short walk of most downtown venues. When I need a higher‑signal lunch with a partner or prospect, I book a table slightly off the main corridor to avoid the rush—think Mourad for elevated Moroccan in SoMa or Boulevard along the Embarcadero for a polished, quiet conversation.
Dinner is where the best networking often happens, so I plan for atmosphere, acoustics, and a menu that works for mixed dietary needs. Kokkari Estiatorio (FiDi) excels for executive dinners. Liholiho Yacht Club is a creative, memorable choice for cross‑functional teams. Waterbar or Angler near the waterfront pair great food with views that impress visiting colleagues. For something more casual but still conversation‑friendly, Nopa or Sorella deliver consistently.
When it’s time for drinks, I think in terms of groups and goals. For panoramic views and small group catch‑ups, The View Lounge (Marriott Marquis) is a classic. For wine‑forward conversations with a quiet ambiance, Press Club near Yerba Buena works well. If you’re hosting a more energetic crew, Charmaine’s (SF Proper Hotel), Dirty Habit (Hotel Zelos), or 25 Lusk offer space, good music, and reliable service. For craft cocktails, Pacific Cocktail Haven and ABV are standouts if you don’t mind a short ride.
Transit and timing matter. From SFO or OAK, BART is often the fastest, most predictable route downtown; rideshare is convenient late at night. I walk whenever possible, but I time routes along well‑lit, busier streets and avoid sprinting between neighborhoods tight on time. Microclimates are real—bring layers, comfortable shoes, and a compact umbrella. I schedule 15‑minute buffers around key sessions to handle inevitable friend‑of‑a‑friend introductions.
If you need a professional setting for a quick working session, many hotels will extend lobby seating to guests and their visitors. For dedicated space, day passes at coworking operators like Industrious, CANOPY, or Regus are worth it when you’ve got a client briefing or board prep. For a more casual backdrop, Sightglass and Blue Bottle locations typically have reliable Wi‑Fi and just enough outlets if you arrive off‑peak.
Finally, a word on intent: I set a simple goal for each day—one meaningful connection, one surprising insight, and one concrete action to bring back to my team. ProductCon San Francisco 2025 is a catalyst if you design your experience with the same rigor you apply to your roadmap. If you spot me in a session or at a nearby cafe, say hello—I’m always up for trading notes on product strategy, pricing experiments, and what’s working in the field right now.
Quick note: restaurants and hours can change quickly—make reservations where possible and double‑check opening times the week of the event.
You have rewritten the roadmap as OKRs, asked teams to focus on outcomes, and changed the titles in the quarterly review. Yet feature requests still arrive as commitments, teams still need approval to change a solution, and leaders still celebrate launches more than customer behavior. The language changed. The operating model did not.
An outcome-driven product operating model changes who owns the problem, what leaders fund, how teams make decisions, and what evidence can alter the plan. If you are leading that transition, the practical test is simple: can each product team name the behavior it is trying to change, its current baseline, the business result that behavior should influence, its guardrails, and the decisions it can make without escalation?
Start with an outcome contract, not an outcome slogan
An outcome-driven model needs more than an outcome-shaped sentence. It needs a clear contract between leadership and the team.
Leadership defines the strategic direction, the customer or business result that matters, the constraints, and the boundaries of acceptable risk. The team owns discovery, solution choice, sequencing, and the experiments used to find a viable path. This division protects strategic alignment without turning leaders into backlog managers.
Describes the behavior or result that should change
More new accounts complete the first-value action
Metric
Measures that change
Activation rate or time-to-first-value
Target
Defines the desired movement and time horizon
The agreed improvement from the recorded baseline
Bet
States a possible way to create the outcome
Guided setup for the highest-friction step
Output
Names what the team may build or change
An in-app guide or revised onboarding flow
Keeping these elements separate matters. If the objective says “launch onboarding v2,” the solution has already been chosen. Discovery can only validate the predetermined answer. If it says “improve activation,” but there is no segment, baseline, causal explanation, or guardrail, the team has freedom without usable direction.
A strong outcome contract fits on one page and contains:
Target customer and problem: who is affected, where the friction appears, and why resolving it matters now.
Primary outcome: the single behavior or business result the team is expected to influence.
Baseline and target: the current measurement, desired movement, and decision horizon. If the baseline is unavailable, measurement is the first task rather than an assumption hidden in the plan.
Causal chain: the proposed connection from product change to customer behavior to business value.
Leading indicators: signals such as completion of a core action or time-to-first-value that can reveal movement before the lagging result is available.
Guardrails: measures that must not deteriorate, such as support demand, reliability, performance, satisfaction, privacy, or risk.
Constraints: non-negotiable regulatory, security, platform, brand, cost, or commercial boundaries.
Decision rights: what the team can decide, what requires consultation, and what requires leadership approval.
Evidence standard: what would justify continuing, changing, scaling, or stopping the bet.
The causal chain is the part most teams skip. “Build a dashboard to improve retention” jumps directly from output to business result. Ask what the customer will do differently because the dashboard exists, why that behavior should affect retention, and which signal would appear first. If no credible behavior connects the feature to the result, the feature is not yet a defensible bet.
Do not make the outcome so broad that no team can influence it. Company revenue, total churn, and overall customer satisfaction are often shared results shaped by pricing, sales, service, market conditions, and multiple product experiences. A team needs a customer behavior or operating result close enough to its work to guide daily choices, while still having a clear connection to the larger business outcome.
This is also why outputs should not disappear from planning. Teams still need delivery plans, quality standards, dependencies, and technical milestones. The mistake is treating those items as proof of value. Outputs tell you what changed in the product. Outcomes tell you whether that change mattered.
Give durable teams a problem and real decision rights
You cannot hold a team accountable for an outcome while reserving every meaningful decision for someone else. Outcome ownership without authority is delegated blame.
A durable team should own a customer problem or value area long enough to build context, observe behavior, test alternatives, and learn from the result. A stable product, design, and engineering partnership reduces the handoffs that appear when temporary project teams move from specification to design to implementation.
Durability does not mean a team owns the same feature forever. It means the team retains responsibility for an outcome space even as its solution changes. An activation team might work on guidance, setup defaults, education, performance, or removing a step entirely. The outcome provides continuity; the outputs remain flexible.
Make decision rights explicit at each level:
Executive leadership: chooses the strategic outcomes, sets material constraints, allocates investment across the portfolio, and resolves conflicts that cross organizational boundaries.
Product leadership: translates strategy into outcome spaces, defines evidence and review standards, protects coherent team boundaries, and makes portfolio trade-offs visible.
Product teams: investigate opportunities, choose solution hypotheses, decide how to test them, sequence delivery, and recommend whether a bet should continue.
Functional leaders: establish engineering, design, data, security, and product-management standards while developing the craft and capability of their people.
Stakeholders: contribute customer context, commercial needs, risks, deadlines, and operational knowledge. Their requests are important evidence, but they do not silently become roadmap commitments.
The wording of the boundary matters. “The team is empowered unless a senior stakeholder disagrees” is not a decision rule. Specify which constraints are binding, who can override a team decision, what evidence an override requires, and who decides which existing commitment will move as a result.
When a feature request arrives, use a short intake sequence:
Restate the request as a customer problem, business risk, or desired behavior change.
Identify the affected segment, current evidence, urgency, and consequence of doing nothing.
Compare it with the outcomes already assigned to the team.
If it fits, add it as an opportunity or solution hypothesis rather than an automatic commitment.
If it displaces an existing priority, ask the portfolio owner to make that trade-off explicitly and record what is being delayed.
This prevents the common pattern in which every request is individually reasonable but the combined roadmap is strategically incoherent.
Do not force enabling work into a fictional revenue claim. State the operational capability it must improve, the downstream product outcomes it enables, and the risk of postponing it. That gives platform and infrastructure investments a testable rationale without pretending every technical change has a direct, isolated effect on growth.
Manage a portfolio of bets instead of a feature queue
A feature roadmap creates the appearance of certainty too early. It commits the organization to solutions before the most important assumptions have been tested. An outcome-driven roadmap still communicates direction and sequencing, but it treats solutions as bets that can earn more investment through evidence.
Each roadmap item should answer four different questions:
Why this problem? The customer pain, strategic relevance, business consequence, and reason it deserves attention now.
What should change? The target behavior or result, baseline, leading indicators, and guardrails.
How might it change? The current solution hypothesis and the causal assumptions behind it.
What happens next? The evidence being gathered and the next continue, change, scale, or stop decision.
This format changes the roadmap conversation. Stakeholders can challenge the importance of the problem, the logic of the bet, or the quality of the evidence without treating a proposed feature as an irreversible promise.
Use a lightweight bet brief before substantial delivery begins. It should include:
The outcome contract and the strategic objective it supports.
The customer opportunity and evidence that the problem is real.
The causal chain from proposed change to behavior to business result.
The expected reach, frequency of exposure, and direction of behavior change.
The solution hypothesis and the riskiest assumptions within it.
Confidence, effort, dependencies, privacy implications, data requirements, and technical complexity.
The instrumentation, experiment, rollout, and guardrail plan.
The evidence that would change the decision.
A one-page impact brief is usually enough. If a team cannot express the logic concisely, expanding the document will not repair the missing understanding.
Prioritization frameworks can help compare bets, but they should expose judgment rather than replace it. Reach, impact, confidence, and effort are useful because they force assumptions into view. Cost of delay helps when timing matters. Neither method turns uncertain inputs into objective truth.
Pressure-test the inputs before trusting the score:
Is reach based on actual eligible users or the entire customer base?
Does “impact” refer to a behavior that can be measured, or merely to stakeholder enthusiasm?
Is confidence supported by behavioral evidence, customer discovery, prior experiments, or only opinion?
Does effort include instrumentation, rollout, migration, enablement, support, and dependencies?
Would the bet still rank highly if its most optimistic assumption were reduced?
The portfolio also needs balance. Some bets improve customer behavior directly. Others reduce material risk, strengthen a platform capability, or create the measurement needed to pursue later outcomes responsibly. Make those categories explicit so foundational work is not forced to compete through exaggerated short-term impact claims.
Set stopping conditions before enthusiasm and sunk cost distort the decision. A stopping condition might be failure to observe the necessary leading behavior, inability to reach the intended segment, unacceptable movement in a guardrail, or evidence that the customer problem is less important than assumed. Stopping a weak bet is not a delivery failure. Continuing it without a credible causal path is.
Make evidence change plans, funding, and reviews
The model becomes real only when evidence can change what the organization does. If every bet continues regardless of results, experimentation is theater. If quarterly reviews still focus on release counts, teams will optimize for releases.
Connect discovery, delivery, and measurement
Discovery is not a phase that ends when development begins. It is the work of reducing uncertainty throughout the bet. The useful sequence is:
Record the baseline. Confirm that the primary outcome and leading indicators can be measured for the relevant segment.
Map the causal chain. Identify the customer behavior that must change before the business result can move.
Test the riskiest assumption. Learn whether the problem, proposed value, usability, feasibility, or business logic is most uncertain.
Ship the smallest meaningful change. Reduce the scope needed to create observable behavior, not merely the number of tickets in the release.
Monitor leading and guardrail signals. Leading indicators may appear within days, while durable or lagging outcomes can require weeks to assess.
Write the learning memo. Record what happened, what remains uncertain, and whether the evidence supports continuing, changing, scaling, or stopping.
Instrumentation belongs in the bet, not in a cleanup backlog after launch. Define event names, eligibility rules, segments, exposure, dashboards, and metric ownership before the change reaches customers. Otherwise, the team may ship on time and still be unable to answer whether the intended behavior occurred.
Match the evidence method to the decision
Use an A/B test when you need causal confidence and can create valid comparison groups. Set the minimum detectable effect before the test so the team knows whether the available population and duration can detect a change large enough to matter. A test that cannot resolve the decision is activity, not useful evidence.
Not every change can be randomized. Sequential rollouts, pre-post comparisons, cohort analysis, and synthetic controls can still inform a decision, but their limitations should remain visible. Seasonality, selection effects, concurrent launches, and changes in traffic can produce movement that the product change did not cause. Label the conclusion with the strength of the evidence rather than presenting every dashboard shift as proof.
Also distinguish a negative result from an inconclusive one. A well-powered test that shows the necessary behavior did not change challenges the hypothesis. A test with weak exposure, broken instrumentation, or insufficient sensitivity says much less. The next decision should reflect that difference.
Replace status rituals with decision rituals
Each operating cadence should answer a distinct question:
Strategy reviews: Are the chosen outcomes still the right expression of the strategy, given current customer and business evidence?
Team reviews: What did the team learn about the problem, causal chain, solution, and metrics, and what will it test next?
Portfolio reviews: Which bets deserve more investment, which need to change, and which should stop?
Quarterly business reviews: What customer and business results changed, what was learned, and how should allocation change? Releases provide context, not the score.
A useful review page shows the baseline, current value, target, leading indicators, guardrails, confidence level, latest learning, and next decision. A release list without those fields is a delivery update, even if the slide is labeled “outcomes.”
Incentives must support the same behavior. Teams should be accountable for the quality of their discovery, the integrity of measurement, the speed with which they resolve material uncertainty, and the decisions they make from evidence. Treating every missed outcome as individual failure encourages conservative targets, favorable metric selection, and reluctance to stop weak bets. Outcomes are influenced, not manufactured on command.
Introduce the model through a real decision
A company-wide reorganization is not the safest starting point. Begin with an important product area where the current feature plan contains meaningful uncertainty and leadership is willing to let evidence change the solution.
Select one outcome and record its baseline, causal chain, leading indicators, and guardrails.
Assign it to a durable product trio with written decision boundaries.
Convert the planned initiative into a bet brief with assumptions and stopping conditions.
Change the existing team and portfolio reviews so they require evidence and an explicit decision.
At the end of the planning cycle, inspect where decisions still stalled: unclear strategy, missing data, dependency conflicts, weak skills, incentive mismatch, or executive overrides.
Repair those operating constraints before expanding the model to more teams.
Treat the operating model itself as a product. Its users are the teams and leaders making decisions. Its outcomes are clearer ownership, lower decision latency, stronger learning, and better allocation of effort. Changing an org chart without changing those behaviors is just another output.
Key takeaways for your next planning cycle
An outcome must name an observable change, not disguise a feature as an OKR.
Pair every outcome with a baseline, causal chain, leading indicators, guardrails, constraints, and an evidence standard.
Give durable teams authority over discovery and solution choices within explicit strategic and risk boundaries.
Manage solutions as bets that can earn, lose, or redirect investment as evidence changes.
Keep enabling work visible by naming the capability it improves, the outcomes it unlocks, and the risk of delay.
Review customer behavior, business movement, learning, and next decisions. Do not use delivery activity as a substitute for impact.
At your next roadmap review, take the most expensive planned initiative and rewrite it as an outcome contract and bet brief. If the room cannot agree on the target behavior, baseline, causal link, decision owner, and evidence that would stop the work, the initiative is not ready for a larger commitment. Resolve that uncertainty before adding more scope.
You’ve approved AI training, given people access to new tools, and watched the demos fill up. Yet product decisions still look the same. A few enthusiasts move faster, most people return to familiar workflows, and leaders struggle to explain what the investment changed.
The missing piece is usually not another course. It is a system that connects strategy, role-specific practice, manager coaching, and business evidence. If you are responsible for an AI-era workforce transformation, your job is to make new capability visible in the work, not merely available in a learning portal.
Start with the product behavior that must change
A broad goal such as “make the product team AI-ready” cannot guide a training program. It does not tell a PM what to do differently on Monday, a manager what to coach, or an executive what evidence to inspect.
Use this sequence to turn an abstract AI ambition into a trainable capability:
Name the strategic outcome. Choose an outcome already present in the roadmap or operating plan. Do not create a separate set of learning goals that competes with the business.
Locate the workflow. Identify where the outcome is won or lost: discovery synthesis, prioritization, experimentation, sprint planning, onboarding, product tours, or another recurring part of delivery.
Identify the accountable role. Be precise about whether the behavior belongs to a product manager, designer, engineer, analyst, product leader, or cross-functional partner.
Write the observable behavior. Describe what a capable person produces or decides. “Understands LLMs” is not observable. “Can define evaluation criteria before an AI feature enters development” is.
Inspect current evidence. Review real artifacts, decisions, and workflow data. Self-reported confidence can help you find anxiety or demand, but it does not establish competence.
Select the intervention and proof. Decide whether the person needs instruction, practice, feedback, a new role path, or some combination. Name the evidence you expect to improve.
Consider a team that wants to use generative AI in product discovery. “Complete prompt training” is an activity. A useful capability statement is more demanding: the PM can use an LLM to organize customer inputs, separate supported themes from plausible-sounding output, document the method, validate the findings, and turn the synthesis into a product decision. That statement tells you what to teach, what artifact to review, and where human judgment remains essential.
Capture these decisions in a small capability map with fields for strategic outcome, workflow, role, expected behavior, current evidence, learning path, practice assignment, reviewer, and outcome metric. The map becomes the contract between the executive sponsor, functional leader, manager, and learner. It also prevents the curriculum from expanding every time someone finds a new AI tool.
Decide whether you are upskilling or reskilling
Upskilling and reskilling require different commitments. Treating them as interchangeable creates false expectations for the learner and poor workforce plans for the business.
The person remains in the same role and performs it at a higher level.
The person moves toward a materially different role or set of responsibilities.
Problem it solves
The strategy requires stronger execution in an existing workflow.
The strategy creates a capability or talent need the current organization does not cover.
Typical product example
A PM adds LLM evaluation, AI-assisted synthesis, or privacy-by-design to existing product work.
An engineer or analyst develops toward an applied generative AI position.
Primary proof
Better behavior and decisions in the person’s current workflow.
Competent performance against milestones for the destination role.
Support model
Embedded practice, feedback, coaching, and reusable playbooks.
A role charter, staged milestones, tailored onboarding, a mentor, and sandboxed practice.
The cleanest decision test is role continuity. If the role remains intact and the person needs a stronger method, upskill. If the destination changes the person’s core responsibilities, decision rights, or career lane, reskill.
Do not disguise reskilling as a short course. A person moving into applied AI needs clarity about the destination role, protected practice, feedback from someone who can judge the work, and an explicit way to demonstrate readiness. Course completion may show effort. It does not show that the person can operate independently in the new lane.
You also do not need to choose one path for the entire workforce. A sensible portfolio can upskill most PMs and product leaders in AI product judgment while reskilling a smaller cohort of engineers and analysts for specialized applied work. The mix should follow the roadmap, not a blanket mandate that every employee become an AI specialist.
Put practice inside the product operating system
A course can introduce vocabulary and demonstrate a method. It cannot, by itself, make the method survive contact with a real roadmap, imperfect data, stakeholder pressure, and an approaching release. Transfer happens when the learner applies the skill in the environment where it must eventually work.
Use the 70-20-10 model as a design check: most development comes from doing, a meaningful share comes from coaching and peer learning, and a smaller share comes from formal instruction. The proportions are less important than the correction they force. If your plan is mostly video modules and workshops, it is missing the practice environment that creates capability.
A practical learning loop looks like this:
Teach one bounded concept. Examples include LLM foundations, prompt design, evaluation criteria, research synthesis, data governance, or privacy-by-design.
Demonstrate it on a recognizable artifact. Use a discovery summary, decision memo, prototype, roadmap decision, evaluation plan, onboarding flow, or product tour rather than a context-free exercise.
Let the learner perform the work. Start in an internal sandbox or a low-risk initiative, then move into a live workflow when the review and safety boundaries are clear.
Review the output, not the learner’s enthusiasm. A manager, mentor, guild, or product trio should critique the reasoning, evidence, risks, and final decision.
Publish the reusable pattern. Save the prompt, checklist, rubric, example, and known failure modes in a playbook that another person can use.
Repeat in the next work cycle. The learner should apply the capability again without relying on the instructor to drive every step.
Make each role path specific enough to practice
For product managers, concentrate on the judgments they already own: discovery synthesis, framing an AI opportunity, setting evaluation criteria, connecting a prototype to the roadmap, spotting unsupported model output, and communicating tradeoffs to stakeholders.
For product leaders and managers, add a different layer. They need to set decision rights, review AI work consistently, coach to outcomes, protect learning time, and distinguish a promising demonstration from a capability that can be adopted repeatedly. A manager who cannot evaluate the new behavior will unintentionally push the learner back toward the old one.
For engineers and analysts moving toward applied generative AI, use staged practice projects, senior mentorship, and explicit milestones. Internal tools can be useful assignments because they create real constraints and users without requiring the cohort’s first exercise to become a customer-facing production system.
For cross-functional partners, train around the handoffs they influence. Product tours, onboarding sequences, user activation, customer feedback, and stakeholder communication all benefit when the people involved understand both the product objective and the limits of the AI system.
Keep the safety boundary visible throughout the path. Do not turn a training exercise into an unreviewed production deployment or place sensitive customer data into a tool that has not been approved for it. Use sandboxed, synthetic, or otherwise appropriate material until privacy, data governance, access, and review requirements are clear. Responsible AI is part of competent product work, not a compliance module to append at the end.
Protect time as deliberately as budget
A learning budget does little when every calendar is full. Give the cohort recurring focus time, place practice assignments into normal planning, and make the manager accountable for preserving the space. When a new learning commitment enters the plan, ask what will be deprioritized. Without that tradeoff, development becomes extra work and participation will favor the people who already have the most discretionary time.
Make teaching visible as well. Communities of practice, cross-team demonstrations, shadow sessions, and critique groups allow effective methods to travel. Reward the people who turn tacit judgment into a usable rubric or playbook; their contribution raises the capability of more than one learner.
Measure adoption, behavior, and business impact separately
Attendance is an operational signal. It can tell you whether people reached the training, but it cannot tell you whether they can perform the work. Completion rates are equally limited. A person can finish every module without changing a single product decision.
Build the measurement plan in three layers:
Adoption: Is the learner using the workflow, tool, or method? Depending on the path, inspect time-to-first-value, repeat use, feature activation, participation in practice, or progress through role milestones.
Behavior and capability: Is the work different? Review the quality of discovery, evaluation plans, written strategy, stakeholder communication, prototypes, and decisions. Use a rubric so reviewers are judging the same attributes.
Business and operating outcomes: Is the changed behavior helping the system perform? Relevant measures can include time from insight to iteration, deployment frequency and other DORA metrics for engineering-heavy paths, onboarding time-to-productivity, retention analysis, user activation, and attributable ROI.
The metric must stay close to the capability. Training a PM in AI-assisted discovery and then judging the program only by company revenue creates an attribution gap too wide to manage. Inspect whether discovery synthesis and decisions improved first, whether the insight-to-iteration cycle changed next, and how those changes relate to the wider business result.
Establish the baseline before the cohort begins. Review examples of the current work, record the relevant workflow measures, and agree on what meaningful improvement would look like. Where the data supports it, define a minimum detectable effect so normal variation is not presented as proof that training worked.
Do not force every path into the same dashboard. An existing PM’s upskilling path may be best judged through discovery artifacts, decision quality, and cycle time. A reskilling path may require demonstrated milestones, mentor assessment, and time-to-productivity in the destination role. A manager path may require evidence that feedback quality and role clarity improved. Standardize the measurement logic, not the metric regardless of context.
Use the reviews to make decisions. If adoption is low, inspect access, relevance, manager support, and protected time. If adoption is high but behavior is unchanged, redesign the practice and feedback. If behavior improves but the business measure does not, revisit the assumed connection between the capability and the strategic outcome. A learning dashboard earns its place only when it changes the program.
Frame the problem. Choose a strategic outcome, map the relevant workflow and roles, inspect current evidence, and establish a baseline.
Select the cohorts. Put people into an upskilling or reskilling path based on the work they will own, not their interest in a particular tool.
Design the path. Combine narrow instruction with a real assignment, a sandbox where needed, a reviewer, a reusable artifact, and explicit evidence of competence.
Prepare the managers. Give them the capability rubric, coaching expectations, safety boundaries, and authority to protect time or remove competing work.
Run visible practice. Use demonstrations, critiques, shadowing, product trio reviews, and communities of practice to expose both good patterns and failure modes.
Inspect the evidence. Review adoption, behavior, and outcome measures. Scale what transferred, change what created activity without capability, and stop what no longer serves the strategy.
Institutionalize what worked. Move validated paths into onboarding, career frameworks, manager expectations, product playbooks, and planning cadences so the capability survives beyond the cohort.
Set stakeholder expectations before the launch. Finance needs to understand how ROI will be evaluated. HR needs to connect reskilling and capability growth to career paths. Functional leaders need to agree on standards. Managers need to know that learning time is an operating commitment. The learner should not be left to negotiate these dependencies alone.
Key takeaways
Start with a strategic outcome and an observable product behavior, not a catalog of AI topics.
Upskill when the role stays the same; reskill when the person is moving into a materially different lane.
Use formal instruction to introduce a method, then build competence through live practice, feedback, and repetition.
Train managers to recognize and coach the new behavior, or the old operating habits will return.
Measure adoption, capability, and business impact as separate layers.
Run one upskilling path and one reskilling path in the first 90-day portfolio, then scale only what changes the work.
At your next planning session, choose one recurring product workflow where AI capability should already be improving the outcome but is not. Name the role, the behavior, the artifact, the reviewer, and the measure. That single path will teach you more about your organization’s readiness than another company-wide course.
Your team is shipping more often, yet roadmap debates still drag on and too many releases end without a clear decision. That is not high velocity. It is faster production without faster learning.
High-velocity product delivery reduces the time between identifying a customer problem, exposing a safe change, reading credible evidence, and deciding what to do next. You get there by treating experimentation and delivery as one operating system, with shared outcomes, explicit decision rules, controlled exposure, reliable instrumentation, and rapid recovery.
Measure velocity at the decision, not the deployment
Deployment frequency matters because small, frequent production changes shorten technical feedback loops. It belongs beside lead time for changes, change failure rate, and mean time to recovery as part of a balanced view of delivery performance and reliability. But deployment is only one step in the value chain.
A deployment puts code into production. A release makes a capability available to users. An experiment exposes a defined population to controlled alternatives so you can answer a question. A product decision uses that evidence to scale, revise, or stop the work. When those actions are treated as one event, teams accumulate large batches, launch cautiously, and struggle to identify what caused the result.
Signal
What it tells you
What it cannot tell you alone
Deployment frequency
How often code reaches production
Whether users received value
Release or exposure
Who can use the change
Whether the change caused an outcome
Experiment decision
Whether evidence changed a product choice
Whether the delivery system is reliable
Change failure rate and MTTR
How safely the system changes and recovers
Whether the product hypothesis was right
Customer or business outcome
Whether the result that matters moved
Which intervention caused the movement
I would not call a team high velocity merely because it deploys daily. I would look for a short decision cycle: the elapsed time from accepting a product question to recording an evidence-backed decision. Track that alongside the DORA metrics and the outcome the team owns. This prevents a local improvement in engineering throughput from masquerading as product progress.
You probably have a decision-flow problem if any of these patterns are common:
Features are declared complete at launch, with no owner or date for the readout.
Teams run tests but define success after seeing the result.
Several unrelated changes enter one release, making attribution difficult and rollback expensive.
Product reviews discuss shipped items while customer outcomes remain unchanged or unknown.
Deployment frequency rises while change failure rate or recovery time deteriorates.
Tests repeatedly end as inconclusive because traffic, detectable effect, or measurement quality was never checked before development.
Do not respond by setting an experiment quota or a deployment target in isolation. Measure the entire path from question to decision, locate the longest wait state, and remove that constraint. The bottleneck may be test execution, approval, instrumentation, exposure control, analysis, or leadership indecision. More work in progress will only hide it.
Write the decision before you write the feature
An experiment should begin with a decision that needs evidence, not with a feature searching for justification. Before implementation starts, write a compact experiment contract. It turns a vague bet into a question the team can actually answer and makes disagreement cheaper because it happens before code is built.
A reusable experiment contract
Customer problem and population: Name the behavior or friction you are addressing, the eligible segment, and any exclusions. Avoid a target such as all users unless the experience and expected response are genuinely uniform.
Outcome hypothesis: State what behavior should change and why. Use a falsifiable form: If this intervention changes this mechanism for this population, then this outcome should move.
Primary decision metric: Choose the one measure that will decide the test. Diagnostic metrics can explain the result, but they should not become alternate finish lines after the fact.
Minimum detectable effect: Define the smallest effect large enough to change the product decision. Setting the minimum detectable effect before an A/B test begins keeps the team from treating ordinary metric movement as a meaningful win.
Guardrails: Identify customer-experience, reliability, trust, and business measures that must not deteriorate beyond the agreed boundary. A primary metric win is not permission to ignore material harm elsewhere.
Measurement conditions: Record the assignment unit, exposure event, analysis population, start condition, required observation window, and known instrumentation dependencies. If the data cannot distinguish eligibility from actual exposure, fix that before launch.
Decision rule: Specify what will cause the team to scale, iterate, stop, pause, or classify the result as invalid. Name the decision owner and the readout date as part of the same contract.
The MDE is not the smallest movement you would enjoy seeing. It is the smallest movement worth acting on. It also has to be compatible with baseline behavior, eligible traffic, and the observation window. A tiny MDE may sound rigorous, but if the product cannot gather enough evidence to detect it, the team has designed a waiting period rather than a useful experiment.
Consider a hypothetical activation test. The problem is that new accounts fail to complete a clearly defined first-value workflow. The proposed intervention is a contextual setup guide shown after first login. The primary metric is completion of the activation event. Reliability errors and a relevant customer-friction signal are guardrails. The team scales only if the primary effect meets the pre-agreed MDE and the guardrails hold. Every field points to a future decision; none merely describes the interface being built.
Use an A/B test when controlled alternatives, stable assignment, and sufficient eligible traffic can answer the question. Use progressive exposure when the immediate question is operational safety or blast radius. Use discovery methods before either of those when the team still cannot state the customer problem or plausible mechanism. Calling every release an experiment does not make it one.
If assignment breaks, events are missing, or exposure is contaminated, classify the test as invalid. If the data is valid but the primary metric does not meet the success rule, the hypothesis did not earn further investment in its current form. That distinction protects the team from rerunning weak ideas under the label of a measurement problem.
Decouple deployment, exposure, and rollback
High-velocity experimentation needs a delivery system that can put code into production without exposing it to everyone. Feature flags, canary releases, and blue-green deployment make that separation practical. Automated tests, observable pipelines, and fast recovery make it responsible.
At HighLevel, I have helped products move from a weekly release train toward safe daily and eventually on-demand deployments without increasing incident volume. The important lesson was not to search for one breakthrough tool. Smaller batches, tests that fail when they should, immutable artifacts, flags, progressive delivery, and recovery controls had to work as a system.
A safe experiment-release path looks like this:
Merge a narrow change through trunk-based development, behind a flag that defaults to off for users.
Build and verify one immutable artifact so the tested artifact is the artifact promoted through the pipeline.
Deploy to production and check technical health before beginning customer exposure.
Expose an internal population, canary cohort, or other deliberately limited group appropriate to the blast radius.
Start experiment assignment only after exposure and measurement checks pass.
Monitor the primary metric and guardrails without rewriting the success rule in response to early movement.
Expand, pause, revert, or stop according to the contract. Preserve the result and rationale in the decision record.
Remove the flag after the rollout or rollback path no longer requires it. Give every flag an owner and cleanup trigger when it is created.
This sequence separates three kinds of failure that demand different responses:
Delivery failure: The change causes errors, incidents, or unacceptable system behavior. Reduce exposure, roll back or disable the path, and restore service before investigating.
Measurement failure: Assignment, event capture, or eligibility logic is unreliable. Stop interpretation, repair the measurement path, and rerun only if the decision still matters.
Product-hypothesis failure: The system is healthy and the data is valid, but the intervention fails the pre-registered decision rule. Stop or revise the bet instead of blaming the pipeline.
Large batches make all three failures harder to diagnose. Split work so a change can be deployed, observed, and reversed independently. Long-lived branches and release trains increase the amount of unverified work moving together; fast test feedback, contract testing between services, and preview environments reduce the pressure to accumulate that work.
A calendar restriction can reduce immediate exposure, but it does not create a safe delivery capability. If the organization cannot tolerate a routine deploy on a particular day, treat that as evidence that detection, rollback, staffing, or blast-radius controls need attention. The goal is not reckless release timing. It is a system in which an ordinary, narrow deployment is uneventful and recovery does not depend on heroics.
Give empowered teams a learning cadence, not a feature quota
Technical capability will not create velocity if every decision crosses several management and functional handoffs. Durable product trios should own a customer problem from discovery through delivery and readout. Leaders provide the outcome, strategic context, capacity, and non-negotiable constraints; the trio chooses how to learn and what solution, if any, deserves scale. That is the practical value of empowered teams organized around outcomes rather than output.
Make the operating contract explicit:
Leadership owns direction: Define the few outcomes that matter, the time horizon, material constraints, and where evidence could justify reallocating capacity.
The product trio owns the learning loop: Frame the problem, choose the method, write the experiment contract, deliver the change, interpret the evidence, and record the decision.
Platform and engineering leadership own the paved road: Provide CI/CD, test infrastructure, feature flags, progressive delivery, observability, and recovery mechanisms that teams can use without bespoke negotiation.
Data partners own measurement integrity with the team: Standardize event definitions, validate critical events, and make assignment, eligibility, and exposure auditable.
Governance owns clear boundaries: Use privacy-by-design defaults, pre-approved experiment patterns, and a short escalation path for work that changes data use, legal exposure, or customer risk.
Portfolio forums own reallocation: Use experiment decisions and outcome movement to continue, stop, or redirect investment. Do not turn the forum into a recital of completed tickets.
A unified analytics platform helps only when teams can trust and compare its events. For every decision-critical event, record the event name, exact trigger, required properties, owner, and validation status. Review taxonomy changes before launch and inspect live data before starting the experiment clock. Otherwise, the organization gains a shared dashboard but not shared truth.
Keep one visible record for every active bet. It should show the owned outcome, hypothesis, current state, exposure, decision date, result, and next action. Limit final states to scale, iterate with a stated reason, stop, or invalid. This makes abandoned readouts visible and prevents an endless backlog of tests that technically ran but never influenced a decision.
Planning and learning operate on different clocks. A roadmap may allocate capacity over a longer horizon, while an experiment can invalidate a bet much sooner. Connect them through regular decision reviews and use QBRs to move resources based on accumulated evidence. Do not force a team to continue a disproven initiative merely because the planning document has not reached its next revision date.
Judge the system with a balanced scorecard:
The customer or business outcome the team is accountable for.
Decision cycle time from accepted question to recorded action.
The share of launched experiments that reach a decision, separated from invalid tests.
Deployment frequency and lead time for changes.
Change failure rate and mean time to recovery.
Guardrail breaches, rollback quality, and unresolved measurement defects.
No single number should become a target detached from the rest. Faster deployment with rising failures is not healthy. More experiments with weak decisions is not learning. Better short-term conversion with damaged trust is not value.
Week 1: Map the real loop. Baseline production deployments by service, lead time, change failure rate, and MTTR. Trace one recent bet from initial question through release and readout. Mark every queue, approval, handoff, manual step, and missing event. Select one owned outcome and one active question for the pilot.
Week 2: Make the work smaller and the decision explicit. Choose two services and cut batch size in half. Enable feature flags for new code paths. Write the pilot experiment contract, including its population, primary metric, MDE, guardrails, exposure event, decision rule, owner, and readout date.
Week 3: Prove controlled exposure. Improve the fastest relevant test feedback in the pipeline. Add canary or blue-green delivery for one critical service. Deploy the pilot behind a flag, validate telemetry in production, and begin the smallest safe exposure that can support the test design.
Week 4: Close the loop. Publish one dashboard showing deployment frequency beside change failure rate and MTTR, plus the pilot outcome and experiment status. Hold the readout, record a scale, iterate, stop, or invalid decision, and run a retrospective focused on the next constraint to remove.
At the end of the month, success is not a dramatic improvement in every metric. Success is evidence that the operating loop works: a baseline exists, a narrow change can move independently, exposure is controlled, decision data is trustworthy, one bet reaches an explicit disposition, and the next bottleneck is visible. That is enough to choose the next product area without pretending the system is already mature.
Key takeaways
Define velocity as time to an evidence-backed product decision, then use deployment frequency as one enabling signal rather than the goal.
Pre-register the hypothesis, primary metric, MDE, guardrails, measurement conditions, and decision rule before implementation begins.
Separate deployment from user exposure with feature flags and progressive delivery so changes can be small, observable, and reversible.
Pair delivery speed with change failure rate and MTTR; pair experiment results with customer, reliability, and trust guardrails.
Give a durable product trio authority over the full learning loop, while leaders set outcomes and governance supplies clear boundaries.
Start with one product area, complete one question-to-decision cycle, and remove the bottleneck that cycle exposes.
Take one active roadmap bet tomorrow and ask for its decision rule, MDE, guardrails, exposure plan, and readout owner. If the team cannot write them, do not accelerate the build yet. Fix the question first. Then ship the smallest reversible change that can answer it, record the decision, and use what you learn to make the next cycle safer and shorter.
If your roadmap looks aligned in the planning deck but every launch triggers fresh negotiation, your product teams are not short of collaboration. They are working inside an operating model that lets each function finish its task while no one owns the customer result. The visible cost is delay. The larger cost is mistaking a full backlog for progress.
A silo is not simply a function with specialized expertise. You need strong product, design, engineering, marketing, sales, support, and data disciplines. The problem begins when accountability stops at a functional boundary even though the customer outcome crosses it.
That distinction matters because the usual remedies target attitude: ask people to communicate more, schedule another sync, or encourage greater transparency. Those actions cannot repair unclear ownership. They often add coordination work while leaving the original decision structure untouched.
Diagnose the operating model by tracing one recent product bet from the customer problem to the result. Do not start with the org chart. Follow the actual work and ask:
Who first defined the customer problem, and what evidence did they use?
Who chose the solution, scope, success measure, and launch conditions?
Which decisions moved between functions because nobody had clear authority?
Which assumptions were discovered only after engineering, go-to-market, or support had committed work?
Where did two groups solve the same problem independently?
Who inspected the customer or business result after release?
The answers reveal different failure modes. Duplicate solutions usually point to overlapping ownership. A decision that repeatedly moves between leaders points to unclear decision rights. Roadmap arguments grounded in preference point to the absence of shared evidence. A release with no owner for activation, retention, or another intended result points to output accountability.
Launch surprises are another strong signal. If sales learns the positioning late, support sees a new workflow shortly before release, or data discovers that the success metric cannot be measured, the handoff did not fail at launch. Alignment began too late. The missing voices should have shaped the hypothesis and constraints before delivery.
Do not begin with a company-wide reorganization. Moving reporting lines can preserve the same ambiguity under new names. Start with the smallest unit that can own one meaningful outcome from problem definition through measurement.
Give a product trio an outcome, not a bundle of tickets
A product trio brings product management, design, and engineering into the core decision-making unit. Each discipline keeps its craft responsibilities, but the trio shares accountability for a customer outcome. It is not a committee that approves one another’s deliverables. It is the group responsible for turning evidence into a bet, testing that bet, and adapting when the evidence changes.
The wording of the assignment determines how the team behaves. Ship a redesigned setup flow is an output. Improve activation for customers entering setup is an outcome. The first statement commits the team to a solution before learning begins. The second gives the trio room to investigate the obstacle, compare options, run an experiment, narrow scope, or stop an idea that does not move the metric.
An outcome is not permission to work on anything. Give the trio a short bet brief that makes its boundaries explicit:
The customer behavior or problem that needs to change, with the evidence currently supporting it.
The customer outcome and its connection to a business result.
The baseline, leading indicators, lagging measure, and guardrail metrics.
The hypothesis about what is preventing the desired behavior.
The constraints the team must respect, including dependencies and launch conditions.
The experiment or discovery activity that can reduce the most important uncertainty.
The decisions already made, the decisions still open, and who resolves cross-portfolio trade-offs.
This brief should remain lightweight enough to change when learning changes. Its job is not to predict every feature. Its job is to stop different functions from carrying different versions of the problem.
Decision rights must be just as clear. The trio should be able to choose the solution, experiment sequence, and scope within the agreed outcome and constraints. Functional leaders should own craft standards, coaching, staffing quality, and reusable capabilities. Executives should allocate investment across outcomes and settle trade-offs that span teams. Go-to-market, support, legal, security, finance, and data should enter when their knowledge can change the decision, not merely when an approval is needed at the end.
Empowerment without boundaries creates fresh ambiguity. Coordination without local authority creates a committee. A useful test is simple: can the trio stop a planned feature because discovery showed that it would not improve the assigned outcome? If every scope change still requires a chain of functional approvals, the team owns delivery rather than the result.
Replace functional handoffs with a learning cadence
Breaking silos does not require more meetings. It requires changing what the existing meetings are for. Status reporting moves information upward. A learning cadence brings evidence, decisions, and dependencies into the open while the team can still act on them.
Use the following sequence from discovery through delivery:
Before committing scope, align the trio and relevant adjacent functions on the outcome, hypothesis, evidence, constraints, and unknowns. This is where you expose assumptions that would otherwise appear as launch surprises.
During discovery, review what the team learned and which uncertainty should be reduced next. A polished presentation is optional. Evidence and a decision are not.
During sprint planning, connect substantial work to the hypothesis or measure it supports. Label enabling work and dependencies honestly rather than pretending every ticket directly produces customer value.
In the weekly cross-functional review, inspect the outcome signal, new evidence, decisions needed, and blocked dependencies. Skip the round-robin recitation of completed tasks.
At launch, confirm instrumentation, go-to-market readiness, support readiness, ownership of guardrails, and the date of the result readout.
At the readout, compare the observed result with the baseline and experiment design, then decide whether to continue, change, scale, or stop.
Use OKRs to express the outcome commitment, not to disguise a feature list as key results. Use quarterly business reviews to inspect the portfolio: which outcomes are moving, where confidence has changed, and which investments should be increased, redirected, or stopped. Do not make a team wait for the quarterly review to respond to weekly learning.
A decision log keeps the cadence from becoming corporate memory theater. For each consequential decision, record the context, decision, owner, evidence, trade-off, and condition that would justify revisiting it. The goal is not permanent certainty. It is to prevent an unresolved question from being reopened by a different stakeholder with no new information.
Review your recurring meetings after the pilot. Keep a meeting if it produces a decision, resolves a dependency, or changes shared understanding. Merge or remove it if the same update already exists in the scorecard or decision log. This is how better collaboration can reduce coordination overhead instead of adding to it.
Create one evidence path from customer behavior to business result
Teams can share an outcome and still operate in silos if each function brings a different version of reality. Product may watch feature use, marketing may watch campaign conversion, support may watch conversation volume, and sales may watch CRM stages. None of those views is inherently wrong. The problem is that they are not connected into one explanation of what changed for the customer and the business.
Start with the decision, not the dashboard. For the chosen outcome, map the relevant customer journey and identify the events or state changes that show progress. Agree on definitions, identity rules, data owners, and the system of record for each measure. Then connect the measures into a scorecard the trio and stakeholders can inspect together.
A practical outcome scorecard contains:
The outcome metric, its baseline, and its current value.
The leading indicators expected to move before the final result.
Guardrail metrics that could reveal customer or business harm.
The current hypothesis and the evidence for or against it.
The active experiment, including its status and minimum detectable effect.
The latest decision and the next scheduled readout.
The minimum detectable effect, or MDE, is the smallest effect an experiment is designed to detect reliably under its statistical assumptions. Define it before interpreting an A/B test. Otherwise, a result that is too imprecise to support a decision can be presented as proof, while a potentially useful result can be dismissed simply because the test was not designed to detect it.
A unified analytics platform does not have to mean one vendor. If your operating stack includes Amplitude for behavioral analytics, Pendo for in-product behavior, Intercom for conversations, and HubSpot connected to the CRM, the important work is agreeing on identities, event definitions, funnel stages, and ownership across those systems. Buying another tool without resolving those definitions gives every silo a newer dashboard.
When numbers disagree, resolve the definition and lineage before debating the roadmap. Ask which population is included, when the event is recorded, which system owns the state, and whether the same customer can be counted differently across tools. Link the agreed dashboard directly from the bet brief so evidence does not become an optional attachment to planning.
Run one focused pilot before changing the whole organization
A broad transformation program can reproduce the same illusion of work you are trying to eliminate. A focused pilot gives you a real outcome, real dependencies, and real decisions against which to test the operating model.
Choose one customer outcome that currently suffers from conflicting priorities, repeated decisions, or unclear ownership. It must have a measurable leading indicator.
Form one product trio and name the executive sponsor responsible for removing cross-portfolio constraints.
Write the bet brief, establish the baseline, and connect the outcome to its business relevance.
Map decision rights and dependencies. Invite adjacent functions early where their knowledge can change the hypothesis, scope, measurement, or launch conditions.
Select one experiment, define its success criteria and MDE where A/B testing applies, and instrument the relevant part of the funnel.
Use a weekly review centered on the shared scorecard and decision log. Reuse an existing meeting if possible.
Hold a two-week readout. Decide what the team learned, which work or meeting can stop, and whether the bet should continue, change, or end.
A two-week readout does not guarantee that a lagging customer or business outcome will have matured. Use it to inspect the available leading signal, the quality and speed of decisions, unresolved measurement gaps, and whether the new model eliminated duplicated or low-value work. Continue observation when the outcome needs more time; do not manufacture certainty to satisfy the calendar.
Judge the pilot on both impact and operating behavior. Did the trio make a decision that previously would have bounced between functions? Did early involvement expose a dependency before delivery? Did shared evidence let the team cut scope or stop an unsupported idea? Those changes show that accountability is moving closer to the outcome, even before the final metric is available.
Key takeaways
Treat silos as an ownership and decision-design problem, not a request for people to communicate more.
Give a product trio one measurable customer outcome and explicit authority within defined constraints.
Align adjacent functions while the hypothesis can still change, not when the launch needs approval.
Turn planning and review rituals into a cadence for evidence, decisions, dependencies, and learning.
Connect behavioral, product, conversation, and CRM data through shared definitions before declaring a source of truth.
Prove the model with one outcome, one trio, one experiment, and a two-week readout before scaling it.
Start with one roadmap item that attracts recurring debate. Before discussing its feature scope again, ask the responsible people to agree on the customer outcome, baseline, decision owner, and next piece of evidence. If they cannot, you have located the silo. That is where the bridge needs to begin.
Over the past year, I’ve been shipping agentic AI into production and coaching product teams on what it really takes to make these systems trustworthy in the wild. One story that crystallizes the playbook comes from Trainline’s move to an agentic architecture for travel assistance—an approach that mirrors what I’ve seen work in high-stakes, real-time customer experiences.
Trainline—the world’s leading rail and coach platform—helps millions of travelers get from point A to point B. Now, they’re using AI to make every step of the journey smoother.
I studied how "David Eason (Principal Product Manager) Billie Bradley (Product Manager), and Matt Farrelly (Head of AI and Machine Learning)" approached the build of "Travel Assistant, an AI-powered travel companion that helps customers navigate disruptions, find real-time answers, and travel with confidence." Their work exemplifies the kind of end-to-end thinking required to move beyond demos into dependable, on-the-go assistance.
They share how they: Identified underserved traveler needs beyond ticketing; Built a fully agentic system from day one, combining orchestration, tools, and reasoning loops; Designed layered guardrails for safety, grounding, and human handoff; Expanded from 450 to 700,000 curated pages of information for retrieval; Developed LLM-as-judge evals and a custom user context simulator to measure quality in real-time; Balanced latency, UX, and reliability to make AI assistance feel trustworthy on the go.
I align strongly with their core takeaways: "AI assistants need both scalable reasoning and deep domain context to be useful." "Tool design and guardrails are as critical as prompt design in agent systems." "LLM-as-judge evals make it possible to measure open-ended systems without massive labeling costs." And perhaps most importantly, "Even legacy companies can move fast when they embrace experimentation and tight PM–engineering collaboration."
From an AI strategy perspective, starting "fully agentic" was the right call. When the problem space is dynamic—disruptions, route changes, fare conditions—reasoning loops and orchestration aren’t luxuries; they’re table stakes. Tool selection becomes product design: you need the right retrieval interfaces, constraint-aware planners, and API contracts that are resilient to partial failures. Layered guardrails for safety, grounding, and human handoff reduce hallucination risk while preserving responsiveness—critical when users are standing on a platform waiting for an answer.
The retrieval scale-up—"Expanded from 450 to 700,000 curated pages of information for retrieval"—is a classic inflection point. I’ve seen teams stall here when they treat content growth as a pure indexing problem. The winning move is curation and structure: normalize sources, encode policy-level constraints, and align retrieval chunks to decision boundaries the agent actually uses. That’s how you keep precision high while coverage explodes.
Evaluation is where most open-ended assistants fail quietly, which is why I was encouraged to see "Developed LLM-as-judge evals and a custom user context simulator to measure quality in real-time." In practice, LLM-as-judge gives you scalable, scenario-based scoring without prohibitive labeling, while a user context simulator surfaces regressions tied to persona, itinerary state, and device constraints. The combination closes the loop between model behavior, tool layer changes, and UX outcomes.
On product delivery, the decision to have the system "Balanced latency, UX, and reliability to make AI assistance feel trustworthy on the go" shows mature prioritization. For travel, trust accrues in seconds: fast-enough responses, graceful degradation when upstream data lags, and explicit handoff when confidence dips. This is where guardrails meet UX writing—clear, bounded language signals competence even when the system defers.
Finally, the organizational pattern matters. The teams that win in agentic AI are cross-functional, experimentation-driven, and ruthless about instrumentation. Tight PM–engineering collaboration, explicit safety thresholds, and an eval stack that mirrors real user journeys are what turn promising architectures into dependable products.
It’s a behind-the-scenes look at how an established company is embracing new AI architectures to serve customers at scale.
If you’re building agentic AI in production, borrow these moves: invest early in tool and guardrail design, scale retrieval with curation not just volume, adopt LLM-as-judge plus context simulation for continuous evaluation, and treat latency and reliability as core product requirements—not afterthoughts. That’s how you ship AI assistance that customers trust when it matters most.
I’m excited to share that we’re opening our next R&D hub in Berlin to support significant investment in our AI customer service platform, Intercom, and market-leading AI Agent, Fin. We intend to hire 100 people in Berlin over the year ahead across engineering, AI, data science, product, and design. This move reflects our AI Strategy, our commitment to product management leadership, and our focus on building enduring product-led growth.
We believe that in a short number of years, the vast majority of customer service will be done by AI. Fin is already the world’s best Customer Service Agent. At Pioneer, our recent summit for AI customer service leaders in NYC, we talked about how Fin will become a true end-to-end Customer Agent, extending far beyond service. We showcased how companies like WHOOP, Anthropic, and Lightspeed are already pushing Fin in ways that help them grow their business.
This market opportunity is massive and expanding at unprecedented pace. Our ambition is to earn our place as one of the most successful AI businesses during this wave of AI disruption, and we want more brilliant people on our team to pursue this as aggressively as possible. If you’re motivated by Generative AI, LLMs, and building real products that scale, you’ll find both challenge and impact here.
We are already on track to be one of the fastest growing private software companies. Fin is the primary contributor to this, and is months away from passing $100m in ARR. So far, more than 7000 businesses have transformed their customer service with Fin, including German companies like electricity provider Ostrom, smart home technology provider tado°, and grocery delivery company Flink, along with global leaders like Vanta, Clay, Lovable, and Miro.
Why Berlin? We’re drawn to the city’s rare blend of deep technical talent and rich creative culture—within a vibrant, globally connected ecosystem close to our R&D hubs in Dublin and London. It’s a place where top-tier engineers and designers thrive, and where ambitious builders from around the world want to relocate and create category-defining products.
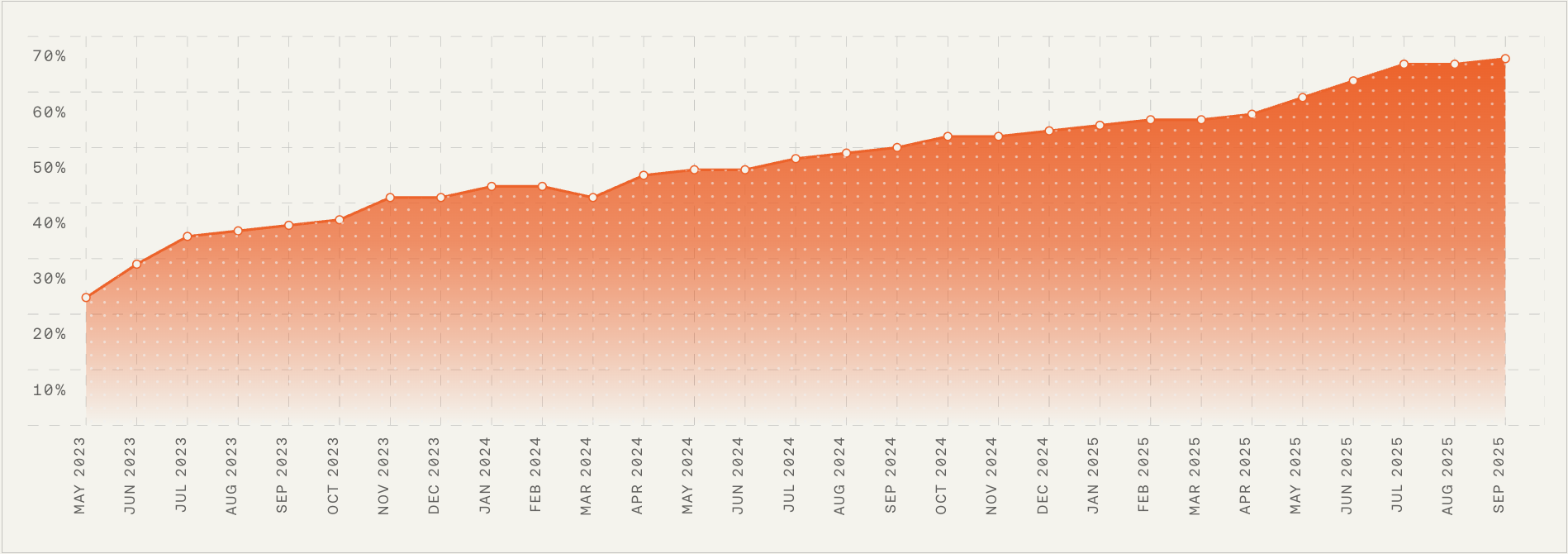
Momentum is building: this month-by-month chart shows a consistent rise from the mid-20s to nearly 70% between May 2023 and Sep 2025—signaling strong progress as we expand engineering, AI, and automation at our new Berlin R&D hub.
We needed a new location that would sustain the high ambition and standards held by our world-class AI teams in Dublin and London. Berlin has emerged as one of Europe’s hottest centers for AI talent, with a high density of AI-focused startups, applied research labs, and practitioners who bring exceptional literacy, optimism, and ambition. It’s the right accelerator for our AI hiring and a place to bring in brilliant minds to shape the future of our product and business.
While Intercom’s reach is global with our headquarters in San Francisco, our R&D leadership remains anchored in Dublin, where half of the executive team sits—making Berlin both geographically and strategically an ideal next location for our growth.
This isn’t our first time expanding our footprint; we previously bet on London and are delighted with how that’s been working. When we shared our Berlin news internally, the energy was palpable, with many teammates volunteering to help spin up the hub successfully—including colleagues who helped make London a big success, like Danny. That level of ownership and momentum is exactly what we aim to cultivate in Berlin.
We’re looking for people who thrive in a high-intensity, high-ambition, high-standards environment and want to help build one of the world’s best AI companies. For builders like that, the opportunity for impact, growth, and career progression is extraordinary. As with London and Dublin before it, the early Berlin cohort will have a disproportionate influence on team norms, culture, and long-term outcomes. We are in the middle of a huge disruptive wave with AI, and Fin is one of the leading examples of commercially successful AI applications. Joining Intercom is an opportunity to be part of this disruptive wave, and help us build out our vision for Fin becoming the world’s best Customer Agent.
On a minimalist stage, four speakers share insights on AI research, automation, and engineering as part of a panel tied to Berlin expansion and the launch of a new European R&D hub.
There are plenty of AI companies to join, but our technology and culture set us apart. Any AI product is only as good as the AI layer powering it. Ours is industry-leading, built by a highly talented, ambitious, and technical team of over 40 machine learning scientists, engineers, and designers in Europe who continuously optimize Fin’s performance through cutting-edge research, experimentation, and innovation. Fin’s average resolution rate increases 1% every month. That kind of steady, compounding improvement is exactly what great customer support AI strategy looks like in practice.
We also build in public and share our progress and learnings with the AI community at large. Recently, our Chief AI Officer Fergal Reid and SVP of Engineering Jordan Neill joined leaders from Cognition, Harvey, and Perplexity in San Francisco to share real lessons, challenges, and breakthroughs from building frontier AI products. Our AI team regularly publishes their insights on the AI research blog; from optimizing inference speed and availability, to building our own proprietary models that outperform general purpose models for CX.
Our AI group and the broader R&D org they operate within work at extraordinary scale and speed. We recognize that moving fast can’t be taken for granted—you must fight for it—and we’re doing just that, embracing the capabilities AI tooling brings us to achieve 2x the throughput. One example of this mindset in practice is us “Betting on the future of frontend at Intercom,” making a technology choice that optimizes for our teams’ ability to build high-quality product, fast.
Our design and product teams are world-class and forward-thinking; they’re embracing AI to evolve how they work, as shared in our 3-point framework for AI-driven design and recently presented by Emmet Connolly, our SVP of Design, at this year’s Hatch conference in Berlin. As a product leader, I’m grateful to work alongside brilliant product and design thinkers—it gives me confidence that we’re solving the right problems, solving them well, and driving real impact.
From live demos to hands-on coding, this snapshot captures the momentum we're bringing to our Berlin R&D hub – AI experiments, hand-tracking prototypes, and simulation tools powering our next wave of engineering.
We plan to open our Berlin office space in December or January. To get the office started, we’re hiring Senior Product Engineers, Machine Learning Scientists, Product Managers, Senior Product Designers, Engineering Managers, and Data Scientists immediately. If your craft sits at the intersection of LLMs for product managers, agentic AI, and empowered product teams, you’ll be right at home.
You can learn more about our open roles, company, culture, and locations on our careers site, or feel free to reach out to me, Jordan, Fergal, or Brian directly on LinkedIn if you have any questions.
Some of our engineering team will also be at LeadDev Berlin on November 3rd—come say hi if you’re attending.
I’m looking forward to continuing to build Intercom as one of our generation’s best AI companies—and I’m excited for our expansion into Berlin to be a major contribution to that success.
Context is king in AI-powered product work—and I felt that deeply while digging into “Context is King – All Things Product Podcast with Teresa Torres & Petra Wille.” The conversation affirmed a truth I see daily: AI becomes a powerful teammate only when we give it the right context, just as we do with empowered product teams. When we treat AI like a colleague joining mid-flight—without our company history, industry nuances, or strategy—we instantly unlock better outcomes.
Listen to this episode on: Spotify | Apple Podcasts
Here’s what stood out and how I’m applying it. First, most AI outputs fail without proper context. That’s not a model problem; it’s a leadership problem. Thinking of AI like onboarding a new intern is the right mental model—start with the minimum viable context, then iterate. Practical first steps matter: decision logs, clear success metrics, and structured documentation. The art is balancing enough context to guide performance without overloading the system. The parallels are striking: the way we create strategic context for product trios and teams is the same way we’ll empower agentic AI systems.
In my teams, we prepare for AI collaboration by operationalizing context. We keep decision logs to capture the why behind choices, use outcome-based success metrics (not just output), and maintain machine-readable documentation that LLMs for product managers can parse reliably. We define guardrails up front—constraints, customer segments, privacy-by-design considerations, and the non-goals that often trip up gen ai. This foundation turns AI from a novelty into a force multiplier for product discovery and product roadmapping and sprint planning.
I use a simple “context pack” to onboard AI agents and teammates alike: 1) business goals and outcomes, 2) constraints and guardrails, 3) canonical artifacts (like PRDs, journey maps, interview notes), 4) domain vocabulary and definitions, and 5) operating procedures (how we make decisions, when to escalate, what good looks like). Start small, then refine as the AI demonstrates capability. This mirrors great onboarding—and it works just as well for agentic AI as it does for humans.
Not all context is helpful. More isn’t better; the minimum effective context is. I resist the urge to dump our entire Confluence on an AI system. Instead, I progressively reveal relevant details—just like I would with a new PM on a complex problem space. This keeps signals high, noise low, and performance measurable against clear success metrics.
If your org isn’t adopting AI yet, don’t wait. You can become AI-ready now by documenting strategic intent, decision rationale, and definitions in structured, searchable, machine-readable ways. Treat this as core AI Strategy work that strengthens empowered product teams—regardless of tooling—while building your AI product toolbox for tomorrow.
For those who want to explore further, these resources and mentions are a strong complement to the episode’s themes.
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Agentic AI
Teresa’s new podcast, Just Now Possible in Youtube, Apple Podcast, and Spotify
Petra’s Coaching Packages
ChatGPT
Henrik Kniberg’s talk at Product at Heart on treating AI agents like interns
Teresa’s webinars on how she built the Product Talk Interview Coach: Behind the Scenes: Building the Product Talk Interview Coach and How I Designed & Implemented Evals for Product Talk’s Interview Coach
Josh Seiden’s blog series about AI
Teresa’s new blog posts: 15 Ways to Use AI at Home (and Fill Your AI Product Toolbox) and 21 Ways to Use AI at Work (And Build Your AI Product Toolbox)
Petra's new blog post: Why Context, Not Just Data, Will Define AI-Ready Product Teams
Have thoughts on this episode or how you’re preparing your teams to collaborate with AI? Leave a comment below—let’s compare playbooks and level up together.
Your AI team can deliver a polished feature and still be unable to answer whether it created value. That problem usually begins before development: a plausible use case becomes a roadmap commitment without a reliable baseline, a falsifiable hypothesis, or an agreed decision rule.
Evidence-driven delivery makes proof part of the product, not a measurement task scheduled after launch. You decide in advance which customer outcome must move, which risks must remain bounded, and what result would justify scaling, another iteration, or stopping. The payoff is faster learning with fewer decisions based on demos, anecdotes, and raw usage.
Start every AI bet with an evidence contract
A roadmap item such as add an AI assistant is a proposed output, not an investment case. Before a product trio commits delivery capacity, turn the idea into an evidence contract: a compact agreement about the user, the expected change, the proof required, and the decision that proof will support.
The bet should connect to a defensible customer or business outcome such as time-to-value, revenue expansion, retention, or cost-to-serve. It also needs to survive an early review of model choice, data readiness, privacy, security, and responsible-use guardrails. If the team cannot describe both the value and the exposure, the use case is not ready to compete for capacity.
A useful evidence contract contains:
Target user and workflow moment: Name the person, the job, and the trigger. Support representative handling a routine service request is more useful than customer support.
Current state: Record how the work happens now, where the friction occurs, and which baseline metric describes it. If the baseline is missing, say so. Measuring the existing workflow then becomes part of discovery.
Causal hypothesis: State why the AI capability should change behavior. For example, a grounded response proposal may reduce drafting effort because the user starts from relevant context instead of a blank field.
Primary outcome: Choose the customer or business result that will determine whether the bet worked. Response time, case resolution, deflection, win-rate lift, retention, and cost-to-serve are possible choices when they match the workflow.
Leading evidence: Identify the behavior expected before the outcome moves, such as feature discovery, task completion, acceptance, correction, or repeat use. This helps diagnose the mechanism without turning a proxy into the final goal.
Minimum detectable effect: Define the smallest improvement large enough to justify the cost, operational change, and risk. Set it before reading experiment results.
Guardrails: Specify the privacy, security, policy, data-quality, human-escalation, and customer-experience conditions that must remain within approved limits.
Decision rule: Write what will cause the team to scale, iterate, pause, or retire the capability. A result without a decision rule produces another debate, not evidence-driven delivery.
Keep outputs, adoption, outcomes, and guardrails separate
These metric types answer different questions and should not be collapsed into one launch dashboard:
Output asks whether the team shipped the capability, instrumented it, and made it available.
Adoption asks whether eligible users discovered it, tried it, completed the workflow, and returned.
Outcome asks whether customer or business performance improved enough to matter.
Guardrails ask whether the improvement came without unacceptable failures, escalations, privacy exposure, security problems, or customer harm.
A feature can ship on time and attract heavy usage while leaving the underlying outcome unchanged. It can also improve the primary outcome while violating a critical guardrail. Neither result earns an automatic scale decision.
The minimum detectable effect turns meaningful into an explicit threshold. Without it, a statistically visible but commercially trivial movement can be presented as success. It also forces the team to confront whether the planned experiment can generate enough evidence. If the available cohort cannot support the test, narrow the question, select a more frequent proximal measure that remains tied to the outcome, or label the evidence as directional. Do not lower the success threshold after seeing the result.
Match the evidence to the uncertainty at each stage
No single evaluation method can prove that an AI product is desirable, reliable, safe, and commercially valuable. Build an evidence ladder in which each stage answers a different question before the team accepts the next level of cost and exposure.
Stage
Question
Useful evidence
Decision supported
Opportunity
Is the workflow painful and valuable enough to change?
Customer interviews, workflow observation, behavioral data, and a current-state baseline
Reject the idea, refine the problem, or prototype
Prototype
Can the target user complete the job and understand the AI’s role?
Task-based prototypes, completion observations, corrections, and direct feedback
Revise the interaction, stop, or fund a working slice
Pre-release
Can the system handle known tasks and edge cases within policy?
Offline evaluations, an error taxonomy, model criteria, and privacy, security, and data-governance checks
Block release or approve a controlled live test
Live release
Does the capability cause the intended behavior and outcome?
End-to-end instrumentation and an A/B test against a control when randomization is appropriate
Scale, iterate, pause, or stop
Durability
Does the value persist after initial curiosity?
Retention, repeat workflow use, outcome persistence, and cost-to-serve
Standardize the pattern, constrain it, or retire it
Prototype feedback cannot establish production reliability. An offline evaluation cannot tell you whether users will change their behavior. Adoption cannot prove that the product caused a business result. Retention cannot rescue a workflow that violates a safety or privacy condition. The ladder works because it prevents one favorable signal from answering a question it was never designed to answer.
Build the evaluation harness before the launch gate
An evaluation harness should be a maintained product asset, not a spreadsheet assembled when release approval is due. Start it during discovery and expand it as customer behavior reveals new failure modes.
Use representative tasks from the intended workflow, including known edge cases and situations that should trigger human escalation.
Define the expected successful, unsuccessful, and safe outcomes before running the candidate system.
Score the generated response separately from the action taken. A plausible answer followed by an incorrect tool action is still a system failure.
Record the model, prompt, relevant data configuration, tool permissions, and policy version used for each run so a result can be reproduced.
Assign failures to a stable taxonomy instead of collecting an unstructured list of bad outputs.
Rerun the suite when the model, prompt, retrieval behavior, tools, policies, or important data dependencies change.
Offline evaluations are the release gate for known behavior. Live experimentation is the test of customer and business impact. When randomization is feasible, A/B testing provides stronger causal confidence than a before-and-after comparison. When it is not feasible, state the limitation plainly: changes in user mix, seasonality, operations, or adjacent product behavior may also explain the movement.
Retention adds a different test. Initial engagement may reflect curiosity, a launch campaign, or required training. Continued use alongside a sustained outcome is better evidence that the capability became part of a valuable workflow rather than a temporary novelty.
Ship the smallest slice that produces interpretable evidence
An oversized first release creates an evaluation problem. If an agent searches for context, classifies a request, generates an answer, chooses a tool, performs an action, and manages an exception, a failed outcome does not reveal which link broke. The team gets more surface area but less usable learning.
Write the operating boundary as part of the product specification:
Entry condition: Which user, request, account state, or workflow event makes the capability eligible?
Allowed context: Which data may the system read, and which data is excluded?
Tool boundary: Which tools can it call, with what permissions, and under which conditions?
Action boundary: Which actions may run automatically, which require confirmation, and which are prohibited?
Escalation rule: What uncertainty, policy condition, or failure sends the work to a person?
Human responsibility: Who owns the escalation, what information arrives with it, and what service level applies?
User affordance: How will the user understand what the AI produced, what it did, why it acted, and how to correct the result?
Exit condition: When should the system stop rather than improvise beyond its approved role?
This boundary is also a risk-control mechanism. Low-risk utilities can begin with suggestions or summaries. A workflow with broader tool access or autonomous actions needs stronger evaluation, clearer escalation, and tighter governance before exposure expands. More capable is not automatically more valuable if the additional autonomy makes the result harder to trust or operate.
Instrument the mechanism, not just the feature
Your event model should follow the actual workflow. A useful sequence is eligibility, exposure, start, AI result, user review, acceptance or correction, action attempt, action completion, business outcome, and later return. Adapt the sequence to the product, but do not jump directly from opened to completed. That gap hides whether the failure came from discovery, usability, output quality, tool execution, or the downstream process.
Use the right denominator. Adoption among all accounts can look weak when only a small subset had an eligible task. Adoption among eligible users or eligible workflow instances tells you whether people choose the capability when it can actually help. Then connect that behavior to the outcome in the relevant system of record.
Behavioral analytics in tools such as Pendo or Amplitude can capture feature discovery, task completion, engagement, and retention. The final business result may live in a CRM, support platform, billing system, or another operational system. An end-to-end measurement design needs a stable way to join those signals without weakening privacy controls.
Diagnostic logging deserves the same care. Model and prompt identifiers, tool calls, structured outcomes, escalation reasons, and user corrections can make failures debuggable. Raw customer content may also contain sensitive data. Apply data minimization, access controls, and retention rules instead of logging everything because it might be useful later.
Onboarding is part of the experiment. Product tours, in-app guides, contextual tooltips, and feedback prompts can teach the new behavior, but each should have a measurable purpose. Track whether the intervention improves discovery or task completion. Otherwise, low adoption may be blamed on the model when the real failure is that users do not know when or how to use it.
Use a weekly evidence review to make the next decision
A normal delivery review asks whether the work is on schedule. An evidence review asks whether the current result changes the investment decision. Run both, but do not confuse them.
A practical weekly evidence review follows a consistent order:
Read the primary outcome, minimum detectable effect, guardrails, and current decision rule before looking at the latest dashboard.
Review the experiment result and separate measured facts from explanations that still need testing.
Inspect representative conversations, errors, edge cases, escalations, and tool failures rather than relying only on averages.
Walk the adoption funnel to locate the step where eligible users abandon, reject, correct, or fail to complete the workflow.
Choose a decision: scale, iterate, pause, constrain, or retire. Record the evidence, the reasoning, the owner, and the next question.
The value of a weekly cadence is not the meeting itself. It is the short distance between observing a failure, classifying it, changing the product, and rerunning the relevant evaluation.
Use the error taxonomy to choose the intervention
Calling every problem an accuracy issue sends the team toward prompt changes even when the prompt is not the constraint. A more useful taxonomy separates the failure by mechanism:
Discovery failure: Eligible users do not notice the capability or cannot tell when it applies. Revisit placement, messaging, and onboarding.
Interaction failure: Users begin but cannot review, correct, confirm, or recover comfortably. Revisit the conversation and interface design.
Capability failure: The model misclassifies, reasons poorly, or produces an unsuitable result despite having the required context. Revisit the model, prompt, decomposition, or task scope.
Context failure: The necessary information is absent, stale, irrelevant, or inaccessible. Revisit data readiness, retrieval, permissions, and grounding.
Orchestration failure: The proposed decision is acceptable, but a tool call, integration, or workflow transition fails. Revisit the tool contract and execution path.
Policy failure: The system acts when it should stop, fails to escalate, or crosses an approved boundary. Tighten policies and block broader rollout until the guardrail holds.
Outcome failure: Users complete the AI-assisted task, but the customer or business result does not move. Question the original mechanism and the value proposition instead of optimizing engagement indefinitely.
Severity belongs beside frequency. A frequent cosmetic problem and a rare unauthorized action should not receive the same priority merely because both count as failures. Risk, reversibility, customer consequence, and the ability to detect the problem should shape the response.
Expand one dimension of exposure at a time
Scale only when the primary outcome clears the agreed threshold, guardrails hold, behavior persists, the evaluation suite is repeatable, and the operating model can support the workflow. That operating model includes human escalation, data governance, security controls, analytics, and an owner for failures after launch.
Expansion can mean more users, more task types, more data, additional tools, or greater autonomy. Change one dimension at a time where practical. Expanding all of them together makes a regression difficult to locate and lets evidence from the narrow release appear stronger than it is. A successful suggestion workflow does not automatically prove that autonomous execution is safe or valuable.
Standardize the reusable system around the feature: evidence-contract fields, event names, evaluation formats, error categories, audit records, escalation patterns, and governance gates. Do not mistake the first prompt for the platform. Models, prompts, and tools will change; the decision discipline should remain stable.
Evidence-driven AI delivery FAQ
What should you do when there is no reliable baseline?
Instrument the current workflow before claiming improvement. You can prototype in parallel, but the next delivery commitment should include a baseline measurement phase. Record the data coverage and known gaps. Comparing a production result with an assumed baseline creates false precision and makes the eventual scale decision fragile.
Can adoption prove that an AI feature is valuable?
No. Adoption can show discoverability, willingness to try, and repeated workflow use. It cannot establish that the intended customer or business outcome improved. High activity may include retries, corrections, or work that would have happened without AI. Pair adoption with task completion, downstream outcomes, guardrails, and a control group when causal testing is feasible.
When should you retire an AI capability?
Retirement is appropriate when repeated iterations fail to produce the agreed meaningful outcome, the expected behavioral mechanism does not appear, the operating cost outweighs the benefit, or critical risks cannot be kept within the approved boundary. A feature should not remain on the roadmap merely because it demonstrates technical capability. Retiring a weak bet returns capacity to a question with a better path to evidence.
At your next portfolio review, take the highest-priority AI item and ask its owner to complete the evidence contract. If the baseline is missing, measure the current workflow. If the decision rule is missing, define it before adding scope. Make the next commitment purchase the evidence required for a decision, not merely more functionality.
I just finished reviewing new findings on Japan’s marketing landscape, and the signal is clear: AI isn’t just a shiny tool—it’s a force multiplier for outcomes and careers. The headline that caught my attention, "Amplitude Releases New Research in Japan: Marketers are Unlocking Efficiency, Results, and Career Growth," aligns with what I’m seeing on the ground: teams that blend disciplined analytics with pragmatic AI adoption are pulling ahead.
Amplitude released a new survey of 500 Japanese marketers, which reveals how teams are benefiting from AI. Get the insights from the data
Here’s how I interpret the shift. AI accelerates the cycle from insight to action when it’s grounded in a unified analytics platform. With Amplitude analytics stitched into campaign and product signals, marketers can move beyond vanity metrics to diagnose true drivers of activation, engagement, and retention. That’s where efficiency compounds: fewer blind spots, faster iteration, and clearer attribution of what actually drives results.
On the strategy side, I’m seeing two dominant patterns. First, gen ai is speeding up creative workflows—audience research, message testing, and content generation—without sacrificing brand rigor. Second, agentic AI is emerging in operational loops: routing leads, prioritizing segments, and suggesting next-best actions based on behavioral data. The common denominator is data governance; without clean event schemas and consent-aware pipelines, AI amplifies noise instead of signal.
For product-led growth motions, this research validates what empowered product teams have practiced for years: instrument the customer journey, frame outcomes vs output OKRs, and experiment in short, learnable cycles. When marketing, product, and data join forces as true product trios, teams can run in-app guides and product tours, tune onboarding, and perform rigorous retention analysis that ties growth to product value rather than spend.
My playbook in this environment is simple but disciplined. Start with first principles decision making: define the problem, the decision, and the evidence required. Use a unified analytics platform to connect lifecycle events across acquisition, activation, and expansion. Align go-to-market strategy with product roadmapping and sprint planning, so insights move directly into experiments—not slide decks. Then close the loop with clear outcome metrics and QBRs that reward learning velocity, not activity volume.
There’s also a career arc embedded in this shift. Marketers who cultivate analytical fluency and AI literacy are becoming indispensable partners to product management leadership. They can articulate a differentiated value proposition, shape product positioning with live behavioral data, and influence board-level narratives with credible, causal evidence. That combination—story plus signal—unlocks both performance and professional growth.
My commitment going forward is to operationalize these lessons: tighter event taxonomy, sharper outcomes framing, and more systematic experimentation across channels and in-product touchpoints. With the right data foundation and a pragmatic AI strategy, we can convert curiosity into capability—and capability into repeatable growth.
Inspired by this post on Amplitude – Perspectives.
Your team can now create a credible prototype, rewrite an onboarding flow, and generate several UX variants before the next planning meeting. Yet the decision at the end of the experiment may still be painfully slow: Was the lift real? Did the feature create durable value? Is the result strong enough to change the roadmap?
That is the central product challenge of the AI era. Generative AI has lowered the cost of exploring solutions, but it has not lowered the standard of evidence required to make a good decision. If you lead product, your goal should not be to run the most tests. It should be to find the shortest defensible path from uncertainty to action.
Key takeaways
Start every experiment with the decision it must unlock, not the variants AI can generate.
Use prototypes and offline evaluation to eliminate weak ideas before spending live traffic on them.
Treat the smallest effect worth acting on and the minimum detectable effect as two different quantities.
Replace one-time sample-size estimates with MDE curves at planned decision points as traffic and variance develop.
Measure treatment integrity, user behavior, operational guardrails, and retained value on their appropriate timelines.
Judge the experimentation program by decisions and uncertainties resolved, not experiment count or win rate.
Start with a decision contract, not a backlog of variants
AI makes divergence easy. Give a model an onboarding screen and it can propose new headlines, layouts, prompts, tooltips, and calls to action almost instantly. That abundance feels productive, but it can bury the question that deserves an answer.
Before anyone generates a treatment, write a short decision contract. It is not a requirements document or an experiment ticket. It is an agreement about what uncertainty matters, what evidence will resolve it, and what action follows.
Decision: Name the roadmap, rollout, positioning, onboarding, pricing, or packaging decision waiting on the result.
Hypothesis: State the proposed causal mechanism. Explain why this treatment should change the user behavior you care about.
Population and assignment unit: Identify who is eligible and whether assignment happens by user, account, workspace, or another stable unit.
Primary outcome: Choose the single behavioral or business outcome that would support the decision.
Guardrails: Name the outcomes that must not degrade, such as latency, error rate, or a critical downstream funnel step.
Evidence horizon: State when the outcome can reasonably appear. Activation, Day-7 retention, and lifetime value do not mature on the same schedule.
Meaningful effect: Define the smallest improvement that would justify the cost, risk, and operational complexity of shipping.
Decision rules: Record what you will do after a positive, negative, or inconclusive result.
The meaningful effect is a product and economic judgment. Minimum detectable effect, or MDE, is a property of the test design and the data available at a particular point. An experiment might be able to detect only a larger change than the business needs. That does not make the business threshold wrong; it means the proposed experiment cannot yet answer the question.
The inconclusive branch deserves particular care. If the test was sensitive enough to detect an effect worth shipping and still found no persuasive difference, you may have useful evidence against the bet. If the test never became sensitive enough, the result is not evidence of no effect. You must either continue under a pre-committed rule, redesign the test, or decide that further evidence costs more than the decision is worth.
Use AI to widen the solution space, then narrow it
Do not send every AI-generated concept into an A/B test. Every additional live treatment consumes traffic, adds operational surface area, and creates another comparison to interpret. Live traffic is scarce measurement capacity, even when generating variants is nearly free.
Ask a product trio to screen candidates before exposure. Keep a treatment only if it represents a distinct mechanism, creates a material user-visible difference, can be instrumented cleanly, meets product and brand constraints, and could plausibly produce an effect the planned traffic can detect. Cosmetic variations that do not test meaningfully different ideas should not become separate roadmap bets.
Then match the evidence method to the uncertainty. A controlled production test is powerful, but it is not the right first tool for every question.
Question in front of you
Useful evidence
What it can establish
What it cannot establish alone
Can the AI system produce acceptable behavior?
Offline evaluation, replay, and structured review
Whether a candidate meets defined quality or safety criteria before release
Whether customers will adopt it or receive durable value
Do users understand the proposed interaction?
Prototype testing, in-app guides, or a lightweight product tour
Comprehension, obvious usability problems, and signs of intent
Causal impact on production behavior or retention
Does the candidate change user behavior?
A controlled live experiment
Incremental impact on activation, conversion, task completion, or another primary outcome
Durable value when the relevant outcome has not matured
Does the change create lasting product or business value?
Retention and revenue analysis at the appropriate horizon
Whether early behavior persists and contributes to longer-term outcomes
A fast answer when the value naturally takes longer to appear
This sequence prevents two common mistakes. The first is paying for production evidence to reject an idea that a prototype could have exposed as confusing. The second is treating positive prototype feedback or an offline model score as proof that the product will change real behavior.
For an AI feature, define the treatment more precisely than a screen name or feature flag. Record the model version, system prompt or instruction template, retrieval configuration, available tools, generation settings, fallback behavior, and relevant interface state. Freeze those elements during the test when practical. If one changes, annotate it and decide whether you have introduced a new treatment.
Generative output may vary within a treatment; uncontrolled configuration drift is a different problem. Keep assignment stable so the same eligible unit does not bounce between control and candidate experiences. If the feature is shared across an account, assigning individual users can also contaminate the comparison because treated and untreated people may influence the same workflow.
Replace the static sample-size promise with an MDE curve
A static A/B test calculator usually returns a reassuringly precise sample size. The precision is conditional. It typically assumes a stable baseline conversion rate, balanced allocation, independent observations, predictable variance, no seasonality, no novelty effect, no unplanned product changes, and a fixed stopping horizon. Real product traffic routinely violates some of those conditions.
Acquisition mix changes. Weekdays and weekends behave differently. Traffic ramps gradually. Funnel variance changes between activation and retention. Teams look at results before the planned end. Sample ratio mismatch can leave the observed allocation different from the intended split. At low event counts, a convenient normal approximation can also be fragile. A single required-sample number hides all of this behind false certainty.
An MDE curve asks a more useful question: what is the smallest lift or reduction this experiment can reliably distinguish at each planned decision point, given the traffic and variance available then? The answer changes as observations accrue, so the plan should show a range over time rather than one finish line.
Start with the business threshold. Decide which effect would be large enough to change the product decision.
Forecast traffic by day. Preserve weekday patterns, ramp plans, and known shifts instead of dividing a monthly total evenly.
Estimate the baseline and variance from relevant history. Use the same population, metric definition, and analysis unit intended for the experiment.
Plot detectable effects at useful checkpoints. A practical view can show the expected MDE after 3, 7, 14, and 28 days rather than promising one universal sample size.
Add operational annotations. Mark feature-flag ramps, campaign changes, holidays or seasonal periods, tracking changes, and product releases that could alter traffic or behavior.
Update the view with actual data. Refresh traffic, allocation, variance, and the resulting MDE band without silently changing the business threshold.
Use a valid monitoring method. If you plan interim decisions, use a sequential design or an explicitly chosen Bayesian approach rather than repeatedly reading a fixed-horizon result as if no peeking occurred.
Updating the curve is not permission to move the goalposts. The metric, meaningful-effect threshold, analysis method, and stopping logic should be committed before exposure. The live curve tells you whether the experiment is becoming capable of answering the original question.
A HighLevel onboarding-flow experiment shows why this matters. A static estimate initially implied that the test needed three weeks. The MDE-over-time view indicated that expected weekday traffic could reveal a meaningful 4-6% lift within a week, while volatile weekend traffic could reliably reveal only an 8-10% lift. Scheduled interim checks and agreed stopping rules supported a decision after nine days, saving a sprint without relying on a premature read.
Nine days is not a reusable benchmark. The reusable practice is to expose how sensitivity changes with traffic and variance, then choose decision points before the result is emotionally or politically convenient.
The curve also improves stakeholder conversations. On day 7, you can say that the experiment is capable of detecting effects of a certain magnitude but not smaller ones. On day 14, the band may narrow enough to resolve the business question. That is far more informative than saying a test is merely still running or has not reached significance.
Measure the chain from AI behavior to retained value
An AI product can look better at one layer and worse at another. A response may score well in an offline evaluation but fail to help a user complete the job. A new prompt may increase initial engagement while adding latency. A novel interaction may lift first-session activation and still have no durable effect.
Build the measurement plan as a chain rather than compressing everything into one headline metric.
Treatment integrity: Confirm assignment, exposure, model and prompt configuration, retrieval state, tool availability, and event delivery. Check for sample ratio mismatch before interpreting outcomes.
Primary user outcome: Measure completion of the user job or the behavioral step most directly connected to the hypothesis. Messages sent, tokens generated, or feature opens may be useful diagnostics, but they are rarely the value by themselves.
Quality diagnostics: Choose signals that explain the primary outcome, such as acceptance, immediate retry, abandonment, or a return to a manual workflow. Treat them as explanations unless the decision contract names one as the primary outcome.
Operational guardrails: Monitor latency, error rates, fallback frequency, and other conditions that could make an apparent product gain too costly or unreliable to ship.
Define each metric before launch. Record the event or calculation, eligibility rules, exclusions, analysis unit, observation window, and desired direction. This metric contract prevents a familiar failure mode: two dashboards share a metric name but use different populations or time windows, so stakeholders debate definitions after seeing the outcome.
Do not force all layers onto the same clock. An activation metric can support an early operational decision if the contract allows it, but it cannot stand in for Day-7 retention or lifetime value. Keep the later cohort alive after an initial rollout decision, and be explicit about which claims remain unproven.
Guardrails should also affect the action, not merely decorate the dashboard. A candidate that improves task completion while causing unacceptable latency or error behavior has not produced an uncomplicated win. The action may be to retain the product concept, fix the operational constraint, and run a new treatment rather than roll out the current implementation.
Run a learning review that changes the roadmap
An experimentation review should be a decision forum, not a show-and-tell meeting. A weekly cadence can work well for empowered Product, Design, and Engineering trios because it keeps hypotheses, implementation choices, and evidence connected. The meeting should not manufacture a decision every week; it should make the state of each decision clear.
Before exposure: Review the decision contract, instrumentation, eligibility, assignment unit, configuration logging, MDE curve, and stopping method.
During the run: Inspect treatment integrity, traffic and allocation, current MDE, guardrails, and annotated operational changes. Avoid debating the winner at unscheduled looks.
At a decision point: Compare the observed evidence with the pre-committed rules. Label the outcome positive, negative, or inconclusive, and record the product action immediately beside it.
After the decision: Preserve the hypothesis, treatment definition, result, caveats, and reusable learning. Link the learning to the roadmap item or playbook it changes.
The leadership dashboard should emphasize learning throughput rather than activity. Track how long important hypotheses take to reach decisions, which uncertainties were retired, which roadmap choices changed, and how often tests were inconclusive because of inadequate sensitivity or broken instrumentation. Repeated underpowered tests are a planning problem. Repeated sample ratio mismatch is a platform or implementation problem. Neither should be disguised as healthy experimentation volume.
Avoid setting experiment win rate as the goal. It encourages teams to choose safe hypotheses, search through metrics for favorable movement, or avoid documenting losses. A well-run experiment that rules out an expensive roadmap branch can create more value than a small positive result that changes no decision.
The compounding advantage comes from reuse. When a test clarifies which onboarding mechanism drives activation, which quality signal predicts abandonment, or which guardrail constrains an AI interaction, make that learning available to the next product trio. AI can accelerate the production of another candidate; the organizational advantage comes from not paying to relearn the same lesson.
Before your next roadmap review, choose the AI-related bet with the most consequential disagreement. Write its decision contract, select the cheapest evidence that can retire the first uncertainty, and put an MDE curve beside the live-test plan. If nobody can state which decision the result will change, do not launch the experiment yet.
Your roadmap can look aligned while the teams behind it are solving different problems. Product is aiming for adoption, marketing is preparing a launch, engineering is controlling delivery risk, and data is still trying to establish what activation means. The mismatch appears late as rework, conflicting dashboards, launch friction, or an argument about whether the release succeeded.
The answer is not another status meeting. You need an operating system that gives people a shared outcome, common evidence, explicit decision rights, and a fast path from production signals to the next decision. When those elements are visible, cross-functional collaboration becomes part of delivery instead of an extra activity surrounding it.
Begin with the behavior you want to change
Output creates the appearance of agreement because it gives everyone a concrete noun: redesign, integration, campaign, dashboard, or launch. It does not prove that the team agrees on the customer problem or the result that would make the work worthwhile.
Consider the difference between these two statements:
Output: Launch guided onboarding.
Outcome: Help new accounts reach their first useful workflow and continue using it.
The output tells design and engineering what to build. The outcome gives product, design, engineering, marketing, and data a problem they can examine together. It also leaves room for the team to discover that a product tour, a clearer empty state, a setup checklist, better lifecycle messaging, or a change to the workflow is the more appropriate intervention.
I use a simple test for alignment: ask each function to explain, in its own words, whose behavior should change, why it is not changing now, and what evidence would show improvement. If the answers differ materially, the initiative is not ready for a scope discussion.
Capture the agreement in an outcome contract. This can be a one-page brief, but it should contain enough precision to govern later decisions:
Customer: The segment and situation you are addressing, not a label as broad as “all users.”
Problem: The obstacle or unmet need, supported by the evidence already available.
Behavior change: What customers should start, stop, complete, repeat, or understand differently.
Success measures: The signals that would indicate progress, including any guardrail that must not deteriorate.
Assumptions: What must be true about the customer, solution, channel, or underlying technology.
Non-goals: Adjacent problems that this initiative will not solve.
Decision owner: The person accountable for resolving tradeoffs when the functions disagree.
Revisit condition: The evidence or dependency change that would justify reopening the direction.
The contract is not a requirements document. It is a boundary around autonomous problem-solving. Teams can change the solution without asking for permission each time, provided the new approach still addresses the agreed problem, respects the constraints, and can be measured against the same outcome. That is the practical value of connecting customer problems, behavior change, and KPIs before delivery begins.
Watch for a problem statement that already contains the preferred feature. “Customers need an AI assistant” is a solution claim. “Customers abandon configuration because they cannot determine which settings apply to their workflow” is a problem the team can investigate. Ask whether you would still fund the initiative if the proposed feature disappeared. If the answer is no, you may be sponsoring an output without having established an outcome.
Separate contribution, consultation, and decision authority
Cross-functional does not mean that everyone decides everything. That interpretation produces large meetings, diluted accountability, and compromises that satisfy the room without serving the customer. Good collaboration expands the evidence going into a decision while keeping responsibility for the decision clear.
A product manager, designer, and technical lead can form the decision-making nucleus. The trio holds the customer, usability, business, and feasibility perspectives close enough to shape the work together. Marketing, data, support, customer success, security, legal, and other partners should enter while their knowledge can still change the approach, not after the solution is effectively frozen.
Contributor
Primary lens
Question to resolve early
Product manager
Customer and business outcome
Which problem deserves investment, and what result would justify continuing?
Designer
Behavior, comprehension, and workflow
Can the intended customer understand and use the proposed experience?
Technical lead
Feasibility, architecture, and delivery risk
Which constraints or unknowns could invalidate the approach?
Marketing
Audience, positioning, and demand
Which promise will make sense to the intended audience, and can the product fulfill it?
Data
Measurement and validity
Which observable signals distinguish real behavior change from activity?
Support and customer success
User language and operational failure modes
Where are customers already confused, blocked, or compensating with workarounds?
The table identifies perspectives, not departmental vetoes. For each material choice, name a directly responsible individual before the debate begins. Then use a consistent decision protocol:
Write the decision as a question. “Should the first release support every account type?” is easier to resolve than a vague discussion about scope.
List the viable options and constraints. Include the option to stop or defer when it is genuinely available.
Separate facts from assumptions. A technical limitation, a customer observation, and a forecast do not carry the same certainty.
Timebox the debate. Contributors provide evidence and consequences; the named owner resolves the remaining tradeoff.
Record the decision. Preserve the chosen option, the alternatives rejected, the reason, and the condition that would warrant reconsideration.
A useful decision record is short. It exists so the next contributor does not have to reconstruct context from messages and calendar invitations. It also prevents a settled choice from being reopened merely because someone new entered the conversation. New evidence is a reason to revisit a decision. A new attendee is not.
Evidence needs the same discipline as ownership. A shared analytics system cannot create agreement if teams use different populations, events, observation windows, or exclusions for the same metric. Create a metric contract for every KPI that can change a roadmap or release decision:
The metric name and plain-language meaning.
The eligible population and any exclusions.
The events and properties used in the calculation.
The observation period or qualifying window.
The owner responsible for definition changes.
The dashboard or query treated as the canonical implementation.
Known caveats and breaks in comparability.
“Activation” is not an operational definition. It is a label. Until the team agrees on who can activate, which behavior qualifies, and within what window, two dashboards can be internally correct while supporting opposite conclusions.
When metrics disagree, do not average the numbers or choose the more convenient chart. Compare the population, event trigger, properties, window, exclusions, and data freshness. Resolve the definition before using the metric to judge the product. This is why event hygiene, operational definitions, self-serve dashboards, and explicit decision ownership belong in the collaboration model rather than inside separate data and governance processes.
Connect discovery, planning, delivery, and learning
Many collaboration failures are timing failures. The right function participates after the decision it could have improved. Marketing sees the experience when messaging is due. Data reviews instrumentation when code is nearly complete. Support learns the workflow when customers begin asking questions. Engineering receives a polished concept before feasibility has shaped it.
Define what each phase must produce and which decision that artifact supports. The lifecycle can remain lightweight while still making participation intentional:
Phase
Shared artifact
Question the team must answer
Resulting decision
Problem discovery
Outcome contract and evidence summary
Is this problem real, important, and appropriate for this team?
Explore, defer, or stop
Concept discovery
Prototype and test findings
Does the approach appear understandable, useful, and feasible?
Refine, test another approach, or prepare delivery
Planning
Living roadmap and dependency map
Which bet best advances the objective under the current constraints?
Sequence the work and assign dependencies
Delivery
Working demonstration and instrumentation checklist
Can the product be released, observed, explained, and supported?
Release, narrow the scope, or resolve a blocking gap
Production learning
Behavior dashboard and feedback summary
Did the intended behavior change, and what remains uncertain?
Expand, modify, run another test, or retire the approach
Bring partner knowledge into discovery
Discovery is where collaboration has the greatest room to change the answer. Customer interviews can expose the problem and the language customers use. Concept tests can reveal confusion before implementation. An instrumented prototype can connect stated reactions with observable behavior. Existing support conversations and in-product feedback can show where the current experience fails.
Do not turn discovery into a series of presentations from one function to another. Give each partner a question that can alter the decision:
Ask marketing which audience assumption and value promise need validation.
Ask data which signals can distinguish the intended behavior from superficial activity.
Ask support and customer success which workarounds, vocabulary, and failure patterns already appear in customer interactions.
Ask engineering which unknowns need a technical exploration before the concept becomes a commitment.
Ask design which behavior can be observed in a prototype rather than inferred from preference.
Package each useful insight with its implication. A screenshot, quote fragment, event pattern, or test result without a decision connection becomes background material that few people revisit. State what was observed, what it may mean, what remains uncertain, and which open choice it affects.
Treat the roadmap as a traceable argument
A roadmap should show why the work belongs, not merely where it sits. Maintain a visible chain from objective to bet to epic to experiment. If the team cannot trace an epic to an outcome, it has probably inherited work without inheriting its rationale.
Invite stakeholders to shape the roadmap where they can reveal dependencies, constraints, risks, and opportunities. That does not make roadmap planning a vote. The product decision owner still has to rank the bets against strategy and evidence. Participation supplies context; it does not erase accountability.
For every meaningful dependency, record the owner, the condition you need satisfied, and what happens if it is not. “Waiting on platform” is status. “The identity team must expose the account permission before this workflow can serve multi-location users; without it, the first release is limited to a narrower account type” is planning information.
Keep the roadmap alive as discovery changes the evidence. A roadmap that cannot absorb a disproven assumption is a delivery calendar, not a product strategy tool. When priorities change, update the objective-to-work trace and the decision record so people can see the reason rather than invent one.
Design the release as a learning loop
A launch confirms that the team delivered something. It does not confirm customer value. The release plan therefore needs a learning path as concrete as the delivery path.
Feature flags and smaller release batches let the team control exposure while observing behavior. In-app guidance can explain a new interaction at the moment of use. Instrumentation connects that exposure to activation, engagement, conversion, or retention, depending on the outcome contract. These mechanisms turn production into a place to answer a question rather than merely distribute completed work.
Before releasing, confirm that the team has:
A named owner for the flag, rollout, and reversal decision.
Verified events and properties for the behaviors that matter.
A dashboard using the agreed metric definitions.
Customer guidance appropriate to the change.
Enough context for support and customer success to recognize expected questions and genuine defects.
A defined review point and a decision the resulting evidence will inform.
Do not collect every available signal. Measure the behavior named in the outcome contract and the guardrails that protect the wider experience. If the team cannot explain what it would do when the metric moves, stays flat, or becomes ambiguous, the dashboard is reporting activity rather than governing a decision. Small releases, feature flags, in-product guidance, and behavioral feedback are useful because they shorten the distance between a product choice and the evidence needed to improve it.
Make the collaboration system visible enough to inspect
Healthy collaboration is observable. You can find the current outcome, see who owns an open decision, inspect the metric definition, understand why a bet is on the roadmap, and locate what the team learned after release. If that context exists only in people’s memories, the operating model will weaken whenever the team grows, reorganizes, or adds a new partner.
Use rituals for specific transitions rather than filling the calendar with recurring status:
Initiative kickoff: Confirm the outcome contract, decision owner, contributors, and known assumptions.
Discovery review: Examine new evidence, identify which assumptions changed, and select the next question.
Decision checkpoint: Resolve a named tradeoff and publish the decision record.
Product demonstration: Inspect the experience in working form and expose gaps across usability, feasibility, messaging, measurement, and support.
Roadmap review: Re-rank bets when strategy, evidence, capacity, or dependencies change.
Learning review: Compare production evidence with the outcome contract and decide whether to expand, modify, test again, or stop.
Every ritual should produce a decision, new evidence, or an updated shared artifact. If it produces none of those, redesign it or remove it. A meeting whose only purpose is to transfer status is a sign that the underlying work is not visible enough.
Use the lightest communication form that preserves the decision context. A one-page brief works for a bounded initiative. A narrative memo is useful when the tradeoff needs more reasoning. A short demonstration video can show product behavior more clearly than written status. A decision record protects context. A shared dashboard gives each function access to the same behavioral evidence. Each artifact should have an owner, current state, and links to the work it governs.
Transparency matters most when the evidence is uncomfortable. Visible roadmaps, shared channels, accessible calendars, and open decision records reduce the temptation to manage disagreement through private escalation. The leader’s job is not to eliminate friction. It is to keep friction focused on the customer, the evidence, and the tradeoff while making it safe to expose a weak assumption early. Plain-language artifacts, transparent working spaces, and respectful disagreement make that behavior easier to sustain.
Run this diagnostic on one live initiative
You do not need an organization-wide maturity model to find the first weakness. Choose an initiative with visible coordination cost and answer these questions:
Can each function name the same customer, problem, intended behavior, and success measure?
Can a contributor find the operational definition of the primary metric without asking the data team?
Does every unresolved material decision have a named owner?
Did marketing, data, engineering, design, and customer-facing partners contribute before their relevant choices were fixed?
Can you trace each major item from an objective to a bet and from the bet to an experiment or release?
Does the release have verified instrumentation and a decision tied to the resulting evidence?
Can a new contributor discover why the team chose the current approach without reconstructing old meetings?
A “no” identifies a specific operating gap. Do not answer it by adding a broad collaboration initiative. Fix the missing contract, role, definition, artifact, or feedback loop inside the live work. That gives the team an immediate benefit and makes the new behavior easier to repeat.
Key takeaways
Define collaboration around a customer behavior and measurable outcome, not a shared list of deliverables.
Use a product trio as the decision nucleus, involve extended partners while they can still alter the approach, and name one owner for each material choice.
Give important metrics operational definitions. A common dashboard is not a common truth when populations, events, windows, and exclusions differ.
Connect discovery, roadmap planning, delivery, and production learning with small shared artifacts that support explicit decisions.
Treat every release as a test of the outcome contract, supported by controlled exposure, verified instrumentation, customer guidance, and a planned evidence review.
Make outcomes, decisions, roadmaps, metrics, and learning visible so collaboration survives beyond the people who attended the meeting.
Pick the live initiative creating the most coordination friction. Put its outcome contract, metric contract, decision owner, open choices, roadmap trace, and release learning plan on one linked page. At the next working session, resolve the first missing item before discussing more scope. You will make collaboration testable: not by whether people feel aligned, but by whether they can make a sound decision from shared context and learn from what reaches customers.