An AI agent becomes operationally valuable when it can move beyond explaining a process and complete the underlying work. That same transition gives the agent access to sensitive data and consequential actions, so integration must be designed as both a product capability and a security boundary.
The practical objective is not maximum access. It is the smallest dependable set of permissions that lets an agent resolve a well-defined workflow, supported by deterministic controls, observable outcomes, and a clear path to human intervention.
System access changes both the value and the risk
Without backend access, an agent can describe how to update an account, check a renewal, or report a damaged order. With access to a CRM, billing platform, or order-management system, it can potentially retrieve the relevant record and complete the request during the conversation. The Intercom article presents this shift from answering to acting as a central difference between basic AI adoption and mature deployment.
The article cites Intercom’s 2026 Customer Service Transformation Report, reporting improved metrics among 87% of teams with mature AI deployments, compared with 62% overall. It also reports that 82% of senior leaders said their teams had invested in AI during the preceding year, while only 10% said they had reached mature deployment. These source-reported figures suggest an integration gap, but they do not independently establish that system access caused the reported improvements or that an integration is secure.
Security therefore cannot be added after the workflow succeeds. A customer-facing interface may remove the need to visit a separate application, but it must not remove identity and authorization checks. The agent still needs a trustworthy way to associate the request with the correct customer, determine what that customer is permitted to do, and constrain the backend operation accordingly.
Choose workflows where access justifies its complexity
Not every automated conversation benefits equally from deeper integration. Intercom reports the results of rebuilding four fixed, scripted Tasks as Procedures with system access. Over the 12 months through May 2026, the reported resolution rate for its bounce-list workflow rose from 9.3% to 79.9%, while bug reporting increased from 9.2% to 66.5%. Email forwarding moved from 44.9% to 66.5%, but Messenger installation rose only from 67% to 69.2%.
The variation is more instructive than the headline gains. According to the article, the bounce-list process required multi-step reasoning, dynamic branches, and error recovery. Bug reporting still ended in a human handoff, but the procedure improved that handoff by pre-triaging the issue, surfacing possible GitHub matches, extracting relevant URLs, and requesting impersonation access. Messenger installation was already a comparatively linear process, leaving less room for improvement.
A suitable first integration is therefore not merely a popular support topic. It should be high-volume and repeatable, have an identifiable system owner, and depend on live data or actions that materially change the outcome. Existing APIs improve feasibility, but the security review should also consider data sensitivity, reversibility, authorization complexity, and the consequences of acting on an ambiguous request.
Use an access ladder instead of a single launch
The phased approach described by Intercom can also serve as a security model. Each stage expands capability only after the workflow and its controls have produced enough evidence to justify the next step.
Stage
Agent capability
Appropriate use
Control emphasis
No integration
Guide, troubleshoot, check policy, triage, and route
Discover where explanations repeatedly lead to manual work
Evaluate answer quality, routing accuracy, and escalation behavior
Read-only access
Retrieve approved fields such as order or subscription status
Resolve information requests without changing a record
Restrict endpoints, records, and fields; verify customer authorization
Write access
Update records or initiate actions such as cancellations or refunds
Complete bounded workflows after earlier stages are dependable
Validate inputs, limit action scope, record outcomes, and require approval where consequences warrant it
Mock responses can test branching logic before an API is ready, as the Intercom article notes. It also proposes a temporary human-in-the-loop step when an integration is still several engineering sprints away. These methods can validate the workflow and expose missing requirements, but simulated success should not be treated as proof that production identity, authorization, failure recovery, and audit controls are ready.
Put deterministic controls around probabilistic decisions
Plain-language workflow instructions can guide an agent, but security-critical constraints should not depend solely on the model interpreting those instructions correctly. A safer architecture places enforceable controls between the agent and each backend system.
Control
Practical design implication
Dedicated identity
Give the agent its own service identity rather than borrowing a staff account, so permissions and activity remain attributable.
Least privilege
Allow only the endpoints, operations, records, and fields required by the selected workflow.
Read and write separation
Keep retrieval permissions distinct from mutation permissions and grant write access only when the use case requires it.
Independent policy enforcement
Validate identity, authorization, limits, and required inputs outside the model before executing an operation.
Bounded actions
Prefer narrow, purpose-built operations over unrestricted database or administrative access.
Human approval and escalation
Route ambiguous, exceptional, sensitive, or difficult-to-reverse cases to an authorized person.
Auditability and monitoring
Record the request, decision, tool call, result, and escalation so failures and unusual patterns can be investigated.
Safe failure behavior
Prevent retries, timeouts, or partial completion from producing duplicated or inconsistent changes.
The integration request should document the workflow in plain language, identify every read and write point, name the system owner, and specify the minimum required fields. It should also define how success and harm will be measured: not only whether the agent completed the conversation, but whether it selected the correct record, performed the authorized action once, protected restricted data, and escalated when it lacked sufficient confidence or permission.
This framing also improves the business case. Engineering is being asked to expose a narrowly scoped capability with explicit boundaries, rather than to provide broad access to a general-purpose agent. Leadership can then compare measurable workflow value with implementation effort and residual risk.
Key takeaways
System access creates value when it lets an agent complete work, but it simultaneously expands the security boundary.
The best initial workflow is frequent, bounded, operationally meaningful, and owned by a team that can approve its data and actions.
Progress from no integration to read-only retrieval and then to narrowly scoped write operations; do not treat access as an all-or-nothing decision.
Enforce identity, authorization, field restrictions, action limits, and audit logging outside the model’s natural-language instructions.
The strongest long-term pattern is a portfolio of small, governed capabilities rather than one broadly privileged agent. Each successful workflow can supply the evidence needed to extend access deliberately, while keeping the consequences of error visible and contained.
Package supply chain security is not simply a matter of choosing reputable libraries. The practical challenge is controlling an expanding dependency graph, the code that executes during installation, the resources that installed software can reach, and the automated tools allowed to make those decisions.
A useful defensive model follows the path an attack must take: enter through a package or dependency, execute in the development environment, discover valuable information, and transmit it elsewhere. Organizing safeguards around that sequence produces a stronger posture than relying on any single scanner, sandbox, or package reputation signal.
Package risk grows through the dependency graph
Developers usually evaluate the packages they select directly. The less visible risk lies in transitive dependencies: packages installed because another dependency requires them. The source article illustrates the scale of this effect by reporting that installing Jest brought in 266 packages. That example is not evidence that those dependencies were malicious; it shows how one deliberate choice can create hundreds of additional trust relationships.
This changes the unit of review. The relevant question is not only whether a named package appears legitimate, but whether its complete dependency graph is proportionate to the job. A small utility that introduces unfamiliar native modules, unrelated capabilities, or an unexpectedly broad tree deserves more scrutiny than its simple interface might suggest.
Manifests such as package.json, pyproject.toml, and requirements.txt make dependency installation repeatable. Repeatability alone, however, does not guarantee safety. If version ranges or unresolved transitive dependencies allow later releases to enter automatically, two installations based on the same manifest can produce different risk profiles. Pinning direct and transitive versions converts an evolving external graph into a more deliberate, reviewable input.
Match defenses to the stages of a package attack
The source article says an analysis covering more than 230,000 malicious-code incidents found a recurring pattern: malicious code first needs an entry point, then searches the device for sensitive data, and finally uses a network connection to exfiltrate what it finds. This reported pattern suggests three distinct control points.
Reduce risky entry and automatic execution
A waiting period for newly published packages can reduce exposure to releases that have not yet attracted community scrutiny. The article recommends installing only packages that are at least seven days old. That is a risk filter, not a guarantee: an older malicious package can remain undetected, while a legitimate urgent fix may occasionally justify an exception.
Installation scripts require separate treatment because they may execute before a developer has inspected the installed code. Disabling automatic install hooks by default creates a decision point. A package that depends on a post-install action can still be used, but the script, its purpose, and the capabilities it invokes should be reviewed first.
Constrain access after installation
Pre-install review cannot catch every problem. The next layer limits what package code can inspect or modify if it does execute. Sandboxed folders and isolated development environments can reduce the blast radius, but the source cautions that isolation by itself does not prevent malicious code from entering. Access boundaries therefore complement package controls rather than replace them.
Limit unnecessary network egress
Stolen information has less value to an attacker if malicious code cannot transmit it. Restricting unnecessary outbound connectivity addresses the final stage of the reported pattern. This layer matters because a package may evade provenance review and execute inside an environment despite earlier controls. Entry controls, resource boundaries, and egress restrictions together create independent opportunities to interrupt the attack.
Provenance is a decision process, not a trust badge
No single popularity or identity signal proves that a release is safe. The source proposes evaluating maintainer history, download patterns, repository activity, signed releases, and consistency across registries. Their value comes from comparison: a sudden change in maintainership, an unusual release pattern, or a mismatch between repository and registry information may warrant investigation even when each signal looks plausible in isolation.
Context also matters. Dependency behavior should be compared with the package’s stated purpose. A capability that is normal for a database driver may be difficult to justify in a formatting utility. This purpose-to-capability test helps teams focus limited review time on anomalies rather than treating every dependency as equally suspicious.
These checks work best when they lead to a clear disposition: approve the package and lock the reviewed version, replace it with a narrower dependency, inspect it more deeply, or decline it. Provenance information without a decision rule can become documentation that does not change behavior.
AI coding agents must inherit the same installation policy
AI-assisted development introduces a governance problem as much as a technical one. A coding agent may be able to select and install a package while pursuing a larger task, compressing several human decisions into one automated action. If it can also reach broad areas of the file system and use the network, a malicious dependency may encounter a larger potential blast radius.
The source describes workflows in which Claude searches, creates, and edits files across a broad knowledge system, including notes derived from downloaded PDFs. That breadth provides productivity value, but it also makes one-folder isolation impractical for the reported workflow. The proposed response is disciplined configuration: hooks require the agent to follow the same package-age, install-script, provenance, and dependency rules expected of a human developer.
This principle is more durable than a rule tied to one assistant. Package policy should apply consistently whether an installation is initiated by a developer, an AI agent, a local automation script, or a build process. The initiator may change; the acceptable evidence, permissions, and exceptions should not.
Key takeaways
Review the full dependency graph, because the packages selected directly represent only part of the installed attack surface.
Use a waiting period for new releases as one filter, while preserving a documented path for justified exceptions.
Prevent install scripts from running automatically until their purpose and behavior have been examined.
Combine provenance checks with a purpose-to-capability test and an explicit approve, investigate, replace, or reject decision.
Pin direct and transitive versions, then run recurring audits to detect issues discovered after installation.
Apply the same package rules to coding agents, automation, local development, and build environments.
Layer installation controls, resource constraints, and network egress limits so that one missed signal does not determine the outcome.
A mature package security posture will increasingly depend on making these controls routine and machine-enforceable. As development becomes more automated, the teams best positioned to move quickly will be those that turn package trust from an informal judgment into a consistent operating policy.
I love being a builder. It feels like a superpower I can’t stop using, and lately I’ve been channeling it into better workflows, faster experimentation, and sharper product thinking.
I tinker with my Claude Code workflows to make every day more effortless. I’m having a blast creating AI-generated interview snapshots and opportunity solution trees for Vistaly. I also spend time digging into traces and iterating on the AI coaches I use for our discovery courses.
Then the recent wave of malicious software spreading through the open-source community popped my bubble. It hit companies big and small—names like OpenAI, PostHog, and Zapier. As I dug in, I realized what many cybersecurity experts have long known: this is a deep rabbit hole. If I want to build responsibly, I have to get significantly better at protecting my devices, credentials, and code. And if you’re building with AI or modern tooling, you likely do, too.
Here’s why. We all rely on open-source software. Most modern applications assemble tried-and-true components—parsing a PDF, handling dates across time zones, visualizing spreadsheet data, connecting to an API—rather than reinventing them. The same is true for agent skills and MCP servers; they accelerate how we get value from models. This is overwhelmingly a good thing. But it also creates an attack surface that bad actors exploit.
We don’t need to abandon third-party code. We do need to understand the mechanisms attackers use and consistently defend against them.
When one malicious worm compromises hundreds of packages, what should dev teams do? This visual teaser maps the agenda—how it spreads, how to guard against it, AI tool risks, and concrete steps to mitigate.
On May 11th, I started seeing tweets about a TanStack hack. At that time, I didn’t know what TanStack was. But apparently, it’s a popular set of JavaScript libraries that are used by a lot of React sites. At first, I didn’t pay much attention. Then I learned the packages were compromised by a worm—malicious software that self-replicates—and it spread quickly. Within hours, dozens of packages were implicated; by day’s end, it was in the hundreds. That’s when I knew I had to lean in.
If you’ve explored safe development practices with coding agents before, you’ve seen the basics of package safety. A package is a bundle of reusable code shared through registries, and nearly every app you use depends on them. The unfortunate twist with this specific hack, known as the Mini Shai-Hulud worm, is that it shows prior “safe enough” heuristics aren’t sufficient. Popularity and trust signals don’t guarantee safety. We have to do more.
So here’s what I’ll cover today: how malicious software typically works, a practical framework for guarding against it, the specific risks of using Cowork to write and run code, and concrete steps to mitigate that risk. My goal is simple: help you keep building—despite the risks—while protecting your data and your business.
Quick disclaimer: I’m not a security expert. I’m sharing my personal journey and what I’ve learned through research and hands-on work. Please use your best judgment when applying any of this.
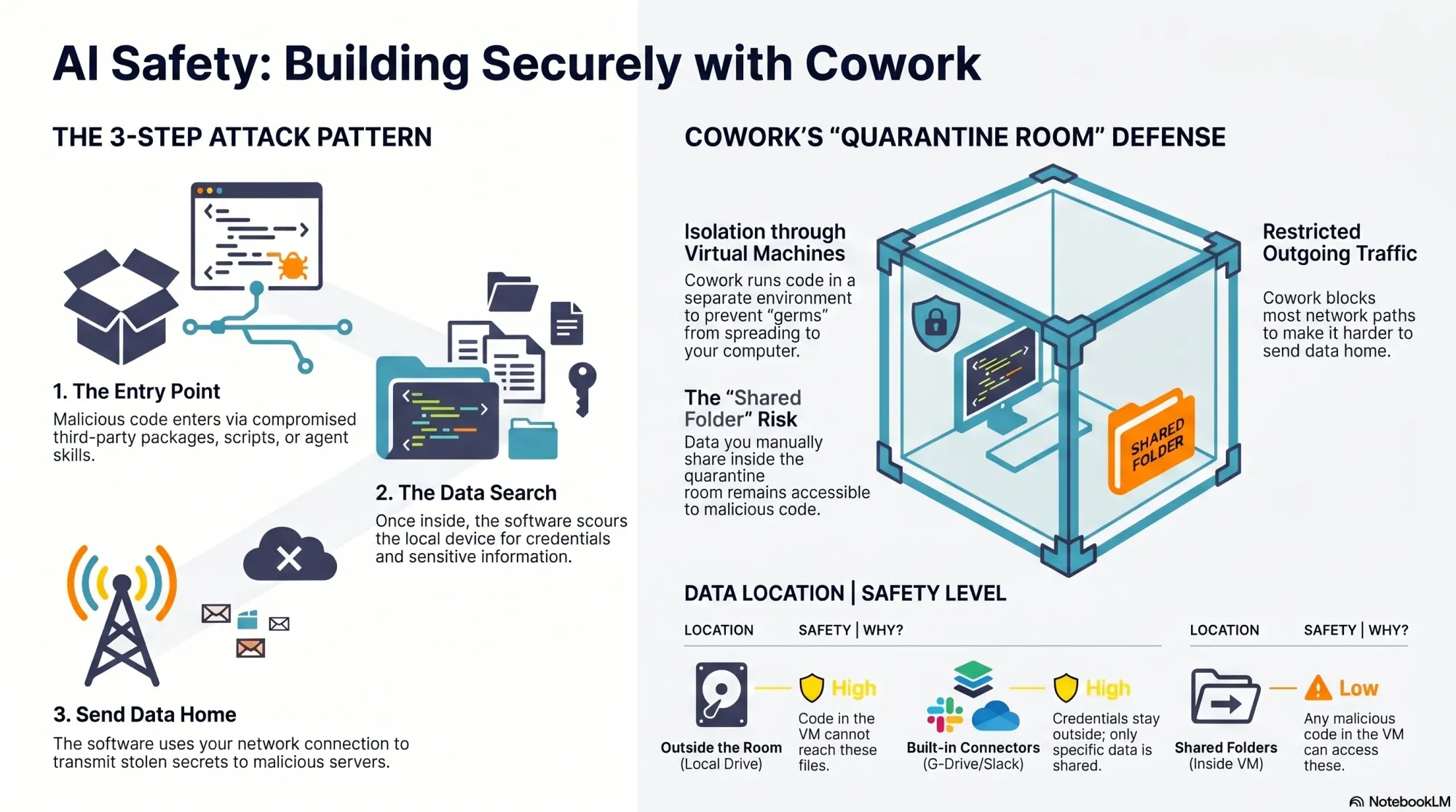
Package hacks share a simple playbook: get in, sweep for secrets, and phone home. This visual breaks down the 3 steps and flags new entry points—from packages to MCP servers, agent skills, and app extensions.
An agent recently scoured over 230,000 malicious software incidents and found that most malicious software follows a similar pattern. First, it needs an entry point onto your computer. Once installed, it scours your device for sensitive data, and then it uses your network connection to send that data to its own servers. The Mini Shai-Hulud worm spreads via malicious package install scripts that run at download time, then searches the device for credentials (including package publishing rights), poisons additional packages to continue replicating, and uses multiple channels—including the victim’s own GitHub public repos—to distribute secrets.
In practice, most attacks boil down to three steps: 1) It finds an entry point to your device. 2) It searches your device for sensitive data. 3) It sends that data to its own server. The good news: this pattern also tells us how to defend. We can harden entry points, minimize what code and agents can access, and constrain outgoing network traffic.
Keep in mind that install scripts aren’t the only entry vector. Any code that runs on your machine could contain malicious payloads: third-party packages, agent skills, MCP servers, browser or desktop extensions—the list is long. As coding agents and “vibe coding” tools become mainstream, more non-engineers are exposed to the same risks engineers have managed for years.
You might be at elevated risk if you do any of the following: you download and use third-party skills or MCP servers; you let Claude Code, Codex, or other coding agents write scripts that run locally and use third-party packages; you use an IDE like VS Code or Cursor with third-party extensions; or you install third-party extensions in tools like Obsidian. This isn’t an exhaustive list, but if any of these apply, it’s worth tightening your approach.
Relying on third-party code? This visual highlights four common risk zones—agent skills/MCP servers, coding agents, IDE extensions, and Obsidian plugins—and urges a review of downloads, local scripts, and add-ons.
The “safest” approach would be to avoid installing third-party software on your local device entirely. That’s not realistic. We all depend on third-party components in our stack. So I’ll start with one of the most common paths for non-engineers writing and running code today: Cowork.
Evaluating Cowork’s safety was eye-opening. Cowork offers meaningful protection—more than running code directly on your machine—but it isn’t bulletproof. There’s a notable gap you should understand.
Here’s how Cowork helps. It runs code inside a virtual machine, which isolates the execution environment from your real device—a quarantine room for code. While Cowork doesn’t fully control what comes into the room (that part is on you), if malicious code gets in, it’s contained and cannot reach the rest of your filesystem. Cowork also limits outbound network traffic from the virtual machine, which helps disrupt data exfiltration. However, it’s not foolproof.
Because Claude can install packages inside Cowork, it remains susceptible to malicious code like the Mini Shai-Hulud worm. And GitHub is on the allow list so Cowork can read and write to your repos. Since the Mini Shai-Hulud worm uses GitHub to publish secrets, this creates exposure. The crucial mitigation: if you never give Cowork access to sensitive data, there’s nothing for an attacker to steal.
A quick visual from a security deep dive on package hacks shows how Cowork handles threats: entry points are contained, data is only safe when kept outside, and network traffic is partly limited—making shared data the gap to watch.
Your responsibility is straightforward but critical: your data is only safe if it stays outside the virtual machine. When you mount folders into Cowork, those folders become accessible to any code running inside the VM. That includes malicious scripts. Before sharing, ask two questions: do the folders contain any credentials or secrets, and do they include proprietary data that would be harmful if accessed?
It’s common for code to need credentials. That’s why Cowork includes connectors to third-party sources like Google Drive and Slack. Credentials configured for these connectors never enter the VM—they remain outside the quarantine room—so they’re not exposed to malicious code. But if your code requires additional credentials inside the VM, scope them tightly and assume they could be compromised.
You can also use custom MCP servers you create yourself with Cowork. Those credentials stay outside the VM as well, provided the MCP servers are remote (hosted on a web server, not downloaded locally). It’s more work than dropping in a local server, but it keeps secrets out of reach from VM-executed code.
Beyond credentials, scrutinize the actual content you share with Cowork, including anything accessed through connectors. Least privilege is the rule: grant only what’s absolutely necessary for the task, and nothing more.
Amid a wave of package-supply attacks, this Product Talk visual launches a 3-part guide to safer AI building—starting with Cowork safety today, then Claude code config next week, and off-device development coming soon.
What about skills? Cowork supports skills, and you can add third-party skills inside the quarantine room. If you’re not placing your own data in that room, you can afford more risk. The moment you add sensitive or proprietary data, be selective. Skills can include third-party code, and bad actors use skill directories to distribute malicious payloads. Personally, I never use third-party skills as-is. If one looks useful, I read through the files, then ask Claude to recreate it so I understand what it does and maintain control. If I were to use third-party skills, I’d do it in Cowork and keep their data access to the minimum necessary.
Overall, Cowork is a solid, “safe-ish” option if you’re disciplined about what you share. The challenge is that utility often requires access to real data—exactly what we’re trying to protect. In an upcoming deep dive, I’ll outline strategies to keep malicious code out in the first place. While I’ll focus on local development, the same patterns can extend to Cowork with a bit of setup.
One more important clarification: don’t confuse Cowork with the Code tab in the Claude Desktop app. Cowork runs code inside a virtual machine. The Code tab does not. If you ask Claude to write and execute code from the Code tab, that code runs on your local device and you’re fully responsible for security. There is one exception: the Code tab can run code in Anthropic’s cloud; I’ll cover that approach when we get into moving development off the local machine.
To summarize Cowork’s protections against the attacker’s three-step pattern: installs and scripts still run, but they’re contained inside an isolated virtual machine instead of your real device; access to sensitive data is strongly limited to the specific folders you mount, leaving the rest of your filesystem (including unrelated credentials) out of reach; data exfiltration is partially constrained because Anthropic limits outbound network traffic from the VM—helpful, but not absolute. By contrast, local Code tab sessions offer no isolation, no filesystem restrictions, and no network limits—so any malicious install scripts run directly on your machine with full access and open egress.
My takeaways so far: I still love building with AI, but I’m doing it more cautiously. Cowork offers meaningful containment when used deliberately. I still prefer the flexibility of Claude Code, and I’ve reconfigured my setup to reduce risk. Even so, “safer” isn’t “safe,” which is why I’m increasingly shifting development off my local device to more controlled environments. I’ll share the practical details—tools, configs, and scripts—in the next installments.
If this perspective is useful, let me know. I want builders to move fast—and safely—through this new era of agentic AI. Until then, stay safe out there.
Procurement should accelerate value, not suffocate it. Listening to this episode, I found myself nodding (and wincing) through a painfully familiar story about how well-intended controls morph into barriers that keep great expertise out. As a product leader responsible for speed, outcomes, and brand experience, I see procurement as a direct mirror of culture—and an often overlooked part of the product operating system.
In the conversation, Teresa is cranky—and honestly, she has every right to be. She’s simultaneously juggling seven speaking engagement contracts, and six of them have become a part-time job in themselves—think 80-page ethics policies, 800-question security forms, and Multi-Factor Authentication (MFA) questions asked 17 different times. Meanwhile, the one company that just put her fee on a credit card? Scheduled, confirmed, and done in two weeks. That contrast is the whole story: friction repels talent; clarity and simplicity attract it.
Petra adds her own horror story—filling out 12 identical Word document forms—and together they surface a deeper truth I’ve seen across organizations: broken vendor processes don’t just frustrate consultants; they stop companies from getting the expertise they actually need. And despite what many assume, company size isn’t the deciding factor—leadership intent and process ownership are.
If you’ve ever wondered why a training got canceled, why a speaker backed out, or why your team can’t seem to bring in outside experts, this is likely the culprit: procurement theater. Repetitive forms, unbounded scope creep, and sprawling security reviews create drag that outlasts any short-term legal or compliance gain. The opportunity cost—lost learning, slower progress, and talent that simply says no—is enormous.
One detail that stood out: with CEO-level buy-in, a legal review timeline collapsed from four months to 10 days. I’ve seen the same thing. Executive sponsorship is the fastest procurement tool there is, and it reveals what the organization truly values. If you can compress the path when a leader cares, you can redesign the path so it’s always faster—without compromising real risk management.
I also loved the clarity of a simple policy from the episode: Teresa’s new policy is straightforward—her paperwork, credit card payment, no vendor setup—or no speaking engagement. That’s not obstinance; it’s a bright-line test for whether an organization respects expert time and understands total cost. The best experts have options, and friction filters them out first.
Here’s how I operationalize this in product-led organizations. Tier risk by engagement type (e.g., one-hour talk vs. long-term software vendor) and match the process to the risk. Offer a credit-card fast lane with standard, plain-English terms for low-risk work. Eliminate duplicate data entry and kill redundant questionnaires. Use a single, secure intake that auto-fills known fields. Track cycle time end to end, and publish SLAs for legal, InfoSec, and finance. Most importantly, make vendor experience a first-class metric—because it is a brand experience.
Security and compliance matter, but they must be right-sized. If you’re buying a keynote, you’re not buying data processing—so why the 800-question security review? Calibrate controls to actual data access and system interaction. The episode even references AWS DynamoDB and GuardDuty, plus Claude Code—helpful reminders that your stack context matters, but not every purchase touches it. Don’t conflate deep technical diligence for a SaaS integration with a simple, no-data engagement.
There’s a reason the classic film Office Space gets a nod—it’s the perfect metaphor for what happens when well-meaning governance calcifies. Bureaucracy compounds over time, usually after adverse events, until startups—or any team that still moves fast—run circles around you. Procurement that treats experts like adversaries won’t win the race that actually matters: learning faster than the market.
If you want the full story, listen to the episode here: Spotify (https://open.spotify.com/episode/2JHnTvnZX2WcFczml7ozKY?ref=producttalk.org) | Apple Podcasts (https://podcasts.apple.com/kh/podcast/procurement/id1794203808?i=1000770701690&ref=producttalk.org). It’s cathartic, but more importantly, it’s a blueprint for fixing what’s broken.
Mentioned in the episode: Hire Teresa to Speak (https://www.producttalk.org/hire-teresa-to-speak/), AWS DynamoDB (https://aws.amazon.com/dynamodb/?ref=producttalk.org), GuardDuty (https://aws.amazon.com/guardduty/?ref=producttalk.org), Claude Code (https://www.claude.com/product/claude-code?ref=producttalk.org), and Office Space (https://en.wikipedia.org/wiki/Office_Space?ref=producttalk.org).
I’d love to hear your experiences and fixes. Where does your procurement flow break, how do you measure cycle time today, and what would it take to create a vendor experience you’d be proud to put your brand on? Drop your thoughts below and let’s trade playbooks.
Your AI feature is ready to move beyond the prototype, but one question can still stop the release: exactly which customer data leaves your boundary, where is it copied, and who can retrieve it later? If the answer is scattered across architecture diagrams, vendor settings, and assumptions, you do not yet have a security decision.
You can resolve that uncertainty without turning every experiment into a committee exercise. Map the data path, assign the capability a risk lane, minimize what the model receives, and automate the controls that follow from the classification. The result is a release process that is both faster and easier to defend.
Start with the data path, not the model
The first security question is not what the model knows. It is what your product sends, retrieves, transforms, stores, logs, and displays. A provider can have a strong security posture while your implementation still exposes data through an overbroad retrieval query, a debug log, or an incorrectly scoped support tool.
Draw the complete path for one user request. Do not use a generic platform diagram. Follow the actual capability from the moment a user or system creates an input until every resulting copy has expired or been deleted.
Identify the original input, including form fields, uploaded files, messages, system-generated events, and API payloads.
List the context added by your application, such as account attributes, conversation history, analytics, retrieved documents, feature configuration, or tool results.
Mark every transformation before the model call: filtering, redaction, tokenization, summarization, chunking, or schema conversion.
Name the service that receives each payload, including gateways, model providers, observability tools, evaluation systems, queues, and caches.
Trace the response through validation, tool execution, display, analytics, support access, and downstream storage.
Record when each copy expires, how deletion propagates, and who can access it while it exists.
For every step, capture six fields: data class, system owner, access scope, external recipient, retention rule, and failure consequence. If any field is unknown, label it unknown. An explicit unknown is useful discovery work; an undocumented assumption is hidden risk.
Use a completion test that exposes weak assumptions
Your map is ready for a decision when someone outside the feature team can answer these questions from it:
What is the most sensitive field the capability can receive?
Which fields cross the company boundary, and which named service receives them?
Can one customer ever retrieve another customer’s data?
Are raw prompts, completions, retrieved passages, or tool results logged?
Which identities can inspect those logs or replay a request?
What happens to derived data when the original record is deleted or its permissions change?
Which control contains the incident if the model, retrieval layer, or tool call behaves unexpectedly?
If the team can only answer these questions by asking several vendors or searching production settings, keep the release open. The missing work is not paperwork. It is part of the product’s operating design.
Turn the risk assessment into a release lane
A risk score is useful only when it changes what the team must do. Avoid a long questionnaire that ends with an ambiguous rating. Use a small number of lanes, give each lane an observable entry condition, and attach default release controls.
Risk lane
Typical signals
Default release posture
Low
Internal capability; synthetic or public inputs; no sensitive context; no consequential external action
Approved provider, least-privilege credentials, basic access tests, and confirmation that secrets are not entering prompts or logs
Elevated
Customer-facing capability; authenticated user context; behavioral telemetry; stored prompts or outputs; retrieval from private content
Data minimization, pre-call redaction, permission-aware retrieval, explicit retention, adversarial evaluations, runtime monitoring, and a named incident owner
High
Regulated-data adjacent; payment identifiers; broad confidential retrieval; sensitive identity data; or authority to perform a consequential action
Early Security, Legal, privacy, and Data involvement; documented threat model; human approval where an action warrants it; verified containment; and release evidence reviewed before exposure
These lanes are an operating model, not a compliance determination. Applicable controls depend on the actual data, customer contracts, geography, industry, and use case. Security and legal specialists should make those determinations when the capability creates legal, regulatory, or material customer exposure.
Classify the capability, not the entire product. A writing assistant that uses text supplied for a single request may sit in a different lane from an account assistant that searches every customer conversation and updates CRM records, even when both use the same model.
Score the capability across these dimensions:
Data sensitivity: public, internal, confidential, personal, payment-related, or regulated-data adjacent.
Audience: constrained employee group, all employees, authenticated customers, or public users.
Retrieval reach: one supplied record, an authorized account subset, or a broad internal corpus.
Action authority: produces a suggestion, drafts a change, or executes an external action.
Persistence: ephemeral processing, structured event storage, or retained raw inputs and outputs.
Third-party exposure: stays inside your controlled environment or passes through one or more providers and subprocessors.
Use the highest-risk dimension to set the initial lane. Lower it only after a design change removes the exposure. A promise to be careful is not a mitigating control; scoped retrieval, enforced redaction, disabled raw logging, and restricted tool permissions are.
Reclassify when the feature changes its data, audience, retrieval reach, retention, provider, or ability to act. A seemingly small roadmap addition, such as remembering past conversations or connecting a second data source, can change the security posture more than a model upgrade does.
Design the system to disclose less data
The most reliable way to protect data is to keep unnecessary data out of the AI path. Encryption and contractual terms matter, but they do not make an irrelevant customer field necessary. Start with the user outcome and ask which minimum facts the model needs to produce it.
Minimize before you redact
Redaction is a valuable deterministic safeguard, but it should not carry the whole design. Free-form text can contain names, secrets, identifiers, and confidential business information in formats your rules do not recognize. Reduce the payload first, then redact the smaller payload that remains.
Replace a full customer object with the few fields required for the task.
Use a temporary account token when the model does not need a person’s name, email address, or payment identifier.
Convert long interaction histories into purpose-specific structured fields when the task does not require the original prose.
Exclude internal notes, disabled fields, hidden metadata, and unrelated attachments by default.
Log structured events such as policy result, model identifier, latency, and request status when raw prompt text is not required.
Separate identity from content wherever the workflow allows it. The application can retain the relationship between a temporary token and an account while the model processes only the content needed for the task. Access to the token map should remain narrower than access to routine AI telemetry.
Make retrieval permission-aware
A retrieval-first architecture can keep the raw corpus inside your controlled boundary while selecting only relevant context for a request. It is not automatically private. If an external model receives the selected passages, those passages still cross the boundary and still require minimization, redaction, approved-provider controls, and a clear retention policy.
Apply authorization when the request is made, not only when content is indexed. The retrieval layer should constrain results by tenant, user, role, and current document permissions before any text becomes model context. Do not index content that the eventual searcher could never be allowed to read unless the architecture has another enforceable isolation boundary.
Treat embeddings and vector-store metadata as sensitive derived data. A vector is not a magic anonymizer, and metadata can disclose document names, account relationships, categories, or activity patterns even when full text is elsewhere. Your deletion and permission-change process must reach the index, cached results, evaluation copies, and any stored citations, not just the primary database.
Retrieved content is also untrusted input. A malicious or compromised document can contain instructions intended to change model behavior. Keep system instructions separate, restrict available tools, validate tool arguments, and enforce authorization in application code. The model should never be the component that decides whether a user may access a record or perform an action.
Place deterministic controls on both sides of the call
Before the call: validate the request schema, remove disallowed fields, redact known sensitive patterns, apply allow and deny policies, and constrain retrieval.
After the call: validate output structure, block disallowed sensitive patterns, verify any cited record belongs to the authorized scope, and check tool arguments before execution.
During operation: monitor unusual prompt, output, retrieval, and access patterns without creating a second uncontrolled store of raw content.
An output filter cannot undo data already disclosed to an external provider. Use post-call checks to protect users and downstream systems, but use pre-call minimization and access enforcement to prevent the disclosure itself.
Make vendor approval specific to the intended use
Do not approve an AI vendor in the abstract. Approve a defined service, account configuration, data class, region, retention posture, and use case. A provider suitable for public-content summarization may not be suitable for customer conversations or payment-related identifiers.
Ask questions that produce enforceable answers rather than broad assurances:
Training and service improvement: Can prompts, files, retrieved passages, outputs, feedback, or metadata be used to train models or improve services? Is the restriction a default, a setting, or a contractual term?
Retention: How long does each data type remain in primary systems, safety systems, failure logs, backups, and support tooling? What initiates deletion, and what exceptions apply?
Human access: Under what conditions can provider personnel inspect customer content, and how is that access authorized, logged, and reviewed?
Security controls: Is data encrypted in transit and at rest? What key-management options, private networking, scoped credentials, access logs, and administrative controls are available?
Location and subprocessors: Which regions process and store the data? Where can support access occur? Which subprocessors participate in the path?
Assurance evidence: Which services and controls are covered by SOC 2, ISO 27001, or HIPAA-related commitments where relevant to the use case?
Response: How will the provider communicate a security incident, policy change, model change, or subprocessor change that affects your approved use?
An audit or certification is useful evidence about a defined scope. It is not proof that your architecture, settings, or use case is safe. Confirm that the service named in the evidence is the service your product will actually call, and that your configuration does not bypass the controls you evaluated.
Keep a short decision record with the approved purpose, permitted and prohibited data, named endpoints or services, required account settings, retention terms, region, responsible owner, and review triggers. Reopen the decision when the purpose, data class, provider terms, model path, subprocessor chain, or architecture changes.
A shared catalog of approved providers and patterns also reduces shadow AI. Make the approved route easier to use by supplying scoped credentials, reference architectures, redaction utilities, retrieval patterns, and clear examples of prohibited inputs. Governance works better when the safe path is a usable product for internal teams.
Put the controls into delivery and incident response
A policy that depends on every engineer remembering every rule will drift. Store the capability’s classification, required controls, approved provider configuration, and decision owner alongside the delivery artifacts. Version changes so the team can see when a new data source or retention behavior altered the release posture.
Translate the release lane into automated checks wherever the control can be tested:
Scan prompts, templates, configuration, and code for exposed secrets and unapproved endpoints.
Unit-test redaction and tokenization against representative allowed and disallowed inputs.
Integration-test tenant boundaries, role permissions, retrieval filters, and deletion propagation.
Run evaluations that attempt to elicit restricted data, override instructions, retrieve unauthorized records, or trigger tools outside the allowed scope.
Validate the selected provider, model path, region, logging setting, and retention configuration against the approval record.
Block release when required evidence, monitoring, rollback controls, or an incident owner is missing.
Evaluation data needs the same scrutiny as production data. Remove unnecessary identities, restrict access, define retention, and avoid copying raw customer interactions merely because an evaluation system is internal. A test corpus can become a long-lived data store if nobody owns its lifecycle.
Monitor security-relevant events rather than indiscriminately recording content. Useful signals include blocked sensitive-data patterns, denied cross-scope retrieval, calls to unapproved services, unusual access behavior, unexpected changes in model or endpoint usage, and failed retention or deletion jobs. Structured metadata often provides the operational signal you need without preserving every prompt and completion.
Prepare containment before the first customer request
Your incident runbook should name the people and mechanisms needed to contain the feature. Depending on the incident, that can include disabling the affected path with a feature flag, revoking or rotating credentials, restricting retrieval, stopping unsafe logging, locating downstream copies, and contacting the provider.
Do not improvise evidence deletion or customer notification during an incident. Security, privacy, and legal owners should determine preservation, notification, and regulatory obligations based on the specific exposure. The product runbook should make those owners reachable and give them an accurate data-flow record, timestamps, affected systems, and containment status.
After containment, update the control that failed: the architecture, automated check, provider setting, policy, runbook, or team guidance. A review that ends with a reminder to be more careful leaves the same mechanism in place.
Key takeaways
Map every copy of the data, including retrieved passages, logs, embeddings, evaluations, caches, and tool results.
Classify individual capabilities by their highest-risk dimension, then attach mandatory controls to the lane.
Minimize fields before redaction, enforce permissions outside the model, and treat derived stores as sensitive.
Approve vendors for a named use, configuration, data class, region, and retention posture rather than issuing blanket approval.
Put redaction, access, retrieval, configuration, evaluation, and release checks into CI/CD.
Design containment and ownership before launch so an incident does not begin with a search for the right people and switches.
Pick one AI capability currently approaching release and produce its request-to-deletion data map. Assign its lane, turn every unknown into an owned backlog item, and automate the first control the team is still checking by hand. That is how security becomes part of product delivery instead of a negotiation at the end.
Fraud teams are drowning in signals—events, alerts, and edge cases that look suspicious but rarely point to what truly matters now. In my role leading product, I focus on turning that noise into clear, ranked actions the team can trust. Behavioral analytics is how we bridge the gap from “something looks off” to “here’s why it matters and what to do next.”
See how behavioral analytics helps fraud management teams surface anomalies, prioritize risk factors, and act faster with greater confidence.
When I build fraud capabilities, I start by defining the outcomes that matter: find anomalies early, prioritize by impact, and respond in minutes—not days. That requires a rigorous approach to data governance, strong observability across the stack, and a mindset tuned to threat detection and response rather than passive reporting.
For me, behavioral analytics means unifying event streams across web, mobile, payments, and support into a single, trustworthy, unified analytics platform. We then apply anomaly detection on top of baselines for user, device, and entity behavior—capturing velocity spikes, geolocation drift, account takeover signals, and unusual journey paths. The win is not more alerts; it’s clearer context per alert.
Prioritization is where the value compounds. I combine deterministic signals (e.g., device fingerprint mismatches, impossible travel, repeated declines) with weighted risk scoring that adapts to emerging patterns. This helps fraud analysts triage by potential loss and customer impact, not just alert volume—so the highest-risk cases land at the top of the queue with the right context attached.
Actionability is the final mile. I map each risk tier to a playbook—step-up authentication, temporary holds, secondary review, or immediate block—so teams can act with confidence. Real-time alerts route to the right channel; feature flags allow fast containment; and AI risk management practices ensure continuous learning while preserving precision and recall. We close the loop by measuring investigation time, false positive rates, and recovery to keep improving.
A few lessons keep paying off: instrument early and consistently; keep your schema stable; document risk definitions; and test changes with A/B testing to quantify impact before scaling. Treat your fraud stack like a mission-critical cybersecurity system with tight SLAs, clear ownership, and auditable decisions—because it is.
If you’re evaluating your next move, start with a narrow but high-ROI use case (account takeover or payment fraud), stand up clear dashboards for analysts, and iterate on the risk scoring model weekly. With disciplined data practices and aligned playbooks, behavioral analytics turns scattered signals into decisive, defensible action.
Inspired by this post on Amplitude – Perspectives.
You have an alert queue full of low-context signals, analysts spending time assembling evidence, and pressure to show that AI can improve the operation. The tempting move is to add a copilot to the security console and call the problem solved.
The harder leadership decision is where AI may influence a security decision, where it may take action, and how you will know it is helping. The right goal is not an autonomous security operations center. It is a shorter, more reliable path from signal to containment, with explicit limits on what a model can do.
Design the decision loop before choosing the AI
AI-enabled cybersecurity operations are easier to manage when you separate three capabilities that vendors often bundle together:
Detection models identify patterns, anomalies, or risk signals in security telemetry.
Generative AI explains evidence, summarizes an incident, retrieves a relevant playbook, and proposes a next action.
Orchestration performs a deterministic operation such as collecting evidence, updating a ticket, isolating an endpoint, or rotating a credential.
These components should not share the same authority. An anomaly score is not proof of compromise. A fluent explanation is not an approved response. A tool call is not safe merely because the model produced valid syntax.
Map the operational loop before you evaluate a model:
Observe: collect the endpoint, identity, network, and application signals relevant to the use case.
Detect: rank suspicious activity without hiding the underlying evidence.
Enrich: add asset criticality, identity context, recent changes, and the applicable response procedure.
Decide: show the recommended action, its prerequisites, and the reason for escalation.
Act: send the approved instruction to deterministic automation with narrowly scoped permissions.
Learn: record the analyst’s disposition, edits, approval, execution result, and any reversal.
For each stage, name the owner, permitted inputs, expected output, failure mode, and fallback. If the AI service becomes unavailable, established detections and response paths should continue to work. If the model produces a poor recommendation, an analyst should be able to reject it without fighting the workflow.
This map is also the product specification. It gives security engineering, SRE, product management, and risk owners a shared object to review. It prevents the initiative from collapsing into a feature list such as summarization, chat, and automation without a defined operational result.
Start with one detection decision, not another alert stream
A strong first use case has frequent decisions, usable feedback, and enough context to evaluate the model. It should improve an existing analyst workflow instead of creating a separate queue that someone must remember to check.
Behavioral models can examine endpoint telemetry, identity signals, and network flows to find activity that fixed signatures may miss. The useful product is not the anomaly itself. It is a ranked case that tells the analyst what changed, which evidence drove the score, what asset or identity is exposed, and what decision is required.
Use these criteria to choose the first workflow:
The decision is specific. “Investigate unusual authentication behavior for a privileged identity” is testable. “Use AI to detect threats” is not.
The evidence is available at decision time. If analysts must leave the workflow and search several systems before judging the recommendation, the AI is working with incomplete context.
The disposition is captured. Confirmed threat, benign activity, insufficient evidence, and duplicate are more useful than a generic closed status.
The existing path remains visible. Analysts should be able to compare the AI-ranked case with the evidence they already trust.
A wrong answer is recoverable. Begin with prioritization and investigation support, not an irreversible action.
Do not treat a smaller alert queue as proof of better detection. A model can reduce noise by suppressing useful signals. Measure precision and recall together: precision asks how much surfaced work was relevant, while recall asks how much relevant activity the workflow found. Because missed incidents may become visible only later, define how labels will be corrected when an investigation changes the original disposition.
Mean time to detect also needs a precise starting point. Decide whether the clock begins when the event occurs, when telemetry reaches the platform, or when an existing control first observes it. Otherwise, a faster model can appear to improve detection while ingestion or analyst queue time remains untouched.
The launch question is therefore not “Did the model find anomalies?” Ask whether it moved the right cases forward sooner, preserved the evidence needed for judgment, and avoided pushing material risk below the analyst’s line of sight.
Give the response copilot context, not unchecked authority
Incident response is a natural place for generative AI because analysts repeatedly assemble timelines, summarize evidence, search runbooks, draft ticket updates, and prepare remediation steps. Those tasks are language-heavy, but the actions they inform can disrupt production or destroy evidence.
Use a retrieval-first flow for response recommendations:
Retrieve the approved playbook and the version that applies to the incident type.
Assemble the facts the model is permitted to see, including the alert evidence and relevant asset context.
Generate a recommendation tied to a named playbook step rather than relying on the model’s general memory.
Check prerequisites, identity permissions, environment, and action scope through policy code outside the model.
Present the evidence, proposed action, expected impact, and rollback path to the designated approver.
Execute the approved operation through a deterministic orchestration layer.
Log the retrieved material, prompt, output, approval, tool arguments, result, and subsequent reversal or escalation.
This architecture makes an important distinction: the model can propose an action, but policy and people grant authority. The model should never be able to expand its own permissions or substitute a different tool when the approved operation fails.
An authority ladder gives that distinction operational force. Use the following as a starting policy and adapt it to the blast radius of your environment:
Action class
Examples
AI role
Required control
Read-only support
Summarize evidence, retrieve a runbook, collect approved diagnostics
Generate or execute within a fixed scope
Least-privilege access, complete logging, and no mutation permissions
Reversible operational change
Update a ticket, isolate an endpoint, rotate a credential
Recommend and prepare the action
Named human approval, validated target, impact warning, and tested rollback
High-blast-radius or irreversible change
Block a production network segment, alter broad access policy, delete data or evidence
Explain and escalate only
Incident command process and approval from the responsible system owner
Endpoint isolation can interrupt legitimate work. Credential rotation can break services when dependencies are unknown. Deleting data can permanently remove forensic evidence. Put those consequences beside the approval button, and provide a safe alternative such as collecting more evidence or opening an incident bridge.
Test the copilot as a security product, not as a conversational demo. Your evaluation set should cover correct recommendations, missing prerequisites, conflicting evidence, obsolete playbooks, requests outside the user’s permission, sensitive data, malformed tool arguments, and situations that require refusal or escalation. Measure whether the recommendation is grounded in the approved playbook, whether the action is appropriate, and whether the system preserved the required approval boundary.
Begin in shadow mode, where recommendations are evaluated but cannot change systems. Move next to draft-only assistance. Permit bounded execution only after the team has defined promotion criteria, rollback behavior, and an owner who can stop the workflow.
Prompt and output logs deserve the same access discipline as other sensitive security records. They may contain identities, indicators, configuration details, or incident evidence. Apply contextual data policies before information reaches the model, restrict access to the logs, and make retention a deliberate governance decision rather than a vendor default.
Counter AI-enabled attacks by changing the process
Change the process that turns a convincing message into access, money movement, or sensitive disclosure:
Require an out-of-band verification step for unusual executive requests, especially when the request changes credentials, access, payment details, or normal procedure.
Do not let familiarity with a voice, writing style, profile image, or caller ID serve as identity proof.
Harden identity controls with multifactor authentication, conditional access, and continuous risk scoring.
Give help-desk and operations teams a defined escalation path when a requester applies urgency or asks them to bypass verification.
Train employees with realistic AI-generated lure patterns, then measure reporting behavior and successful compromise rather than course completion alone.
Use AI-assisted red-team exercises to test the process, and use deception controls where they can divert attacker effort without putting production data at risk.
This reframes awareness training. Employees are not expected to become media-forensics experts. They need to notice when a request crosses a risk boundary and know the exact verification step to take. Product leaders can help by removing friction from the safe path: make reporting easy, make escalation visible, and avoid punishing someone who pauses a suspicious request.
The same principle applies to detection. Do not build the defense around whether content “looks AI-generated.” Build it around identity, behavior, privilege, asset sensitivity, and the actions an attacker is attempting.
Use a 90-day plan with measurable promotion gates
A focused 90-day plan is enough to establish an operating model if you keep the scope narrow: one high-signal detection decision, one mature response playbook, and one employee risk path such as phishing. The purpose is not to automate the security operation in a quarter. It is to prove that the decision loop can become faster without weakening control.
Days 1-30: define the workflow and baseline
Map the current signal-to-action path and identify where time, context, or consistency is lost.
Name a product owner, security owner, model-risk owner, and operational approver for the workflow.
Select the detection decision, response playbook, and employee risk process in scope.
Record baseline mean time to detect, mean time to recover, queue time, disposition quality, and the existing failure modes.
Define the data the model may access, the data it must not access, and the identity under which each tool operation runs.
Write the authority ladder, fallback behavior, stop condition, and rollback procedure before connecting production tools.
Days 31-60: evaluate in shadow mode
Run the detection model beside the existing workflow and compare ranked cases with analyst dispositions.
Test response recommendations against approved playbooks, including ambiguous and adversarial cases.
Review false positives and false negatives with analysts instead of reducing model quality to one aggregate score.
Confirm that sensitive-data policies, model access controls, prompt and output logging, and audit access work as designed.
Run a tabletop exercise covering model failure, unavailable retrieval, unsafe recommendations, excessive permissions, and orchestration failure.
Set promotion criteria for model quality, operational benefit, privacy, access control, and reversibility. Use thresholds appropriate to the risk of the chosen workflow rather than copying a generic benchmark.
Days 61-90: release bounded capability
Release the detection workflow to a defined analyst group while preserving the established fallback.
Enable draft-only response assistance before allowing any system mutation.
Permit only the actions covered by the approved authority policy; keep high-blast-radius changes outside model execution.
Review analyst edits, rejections, approvals, reversals, and escalations to find where the workflow lacks context.
Compare mean time to detect and recover with the baseline, while checking that precision, recall, privacy, and control failures have not regressed.
Make the next release decision explicitly: expand, hold, narrow the scope, or stop. A pilot that exposes an unsafe assumption has still produced a useful result.
The dashboard should separate outcomes from guardrails. Detection and recovery time tell you whether the operation improved. Precision, recall, recommendation correctness, and playbook grounding tell you how the model behaved. Rejections, manual edits, reversals, unauthorized-action attempts, and sensitive-data policy violations tell you whether the workflow is safe enough to scale.
Acceptance rate alone is not a quality metric. Analysts may accept a recommendation because it is correct, because the interface makes editing difficult, or because workload encourages quick approval. Review the resulting action and later incident outcome, not only the click.
Governance must continue after launch. Assign an owner to every model-enabled workflow, control access by role and context, version the model and retrieved playbooks, retain an auditable decision record, test for drift and bias, and repeat tabletop exercises when permissions or orchestration change. A model update is a security-product release, even when it arrives through a managed vendor.
Key takeaways
Optimize the full signal-to-action loop; do not add a disconnected AI queue.
Let models detect, summarize, and recommend, while policy and named people control authority.
Ground response guidance in approved, versioned playbooks before generating remediation steps.
Use shadow mode, draft-only assistance, and bounded execution as separate promotion stages.
Defend against convincing AI-generated lures by hardening identity and verification processes, not by expecting perfect human detection.
Your next operating review should end with three named decisions: the detection workflow you will improve, the response action the AI may only recommend, and the metric that would stop the release. Once those are explicit, AI becomes a governable capability instead of an open-ended security experiment.
In my role leading product management, I take brand trust and cybersecurity seriously—especially when it affects people’s livelihoods. Over the past few weeks, I’ve seen a troubling uptick in brand impersonation and social engineering targeting candidates. It’s a reminder that protecting our community isn’t just a technical problem; it’s a product management leadership and stakeholder management responsibility.
We want to warn you about recent instances of fraudulent job offers purporting to be from Pendo and/or its affiliate companies.
If you receive an unexpected outreach claiming to be from Pendo with a fast-track offer, requests for payment, or a push to move conversations to informal channels, treat it as a red flag. Scammers often spoof logos, clone profiles, and use vague role descriptions to create urgency. Their goal is to extract personal data, money, or access—classic social engineering tactics that undermine data governance and privacy-by-design principles.
Here’s how I advise candidates to protect themselves while keeping their job search momentum. Validate every opportunity through the company’s official careers page and confirm the recruiter’s identity through corporate channels. Check that email addresses and domains match publicly listed corporate information, and be wary of communication conducted exclusively through messaging apps. Never pay fees, buy equipment up front, or share sensitive data like Social Security numbers or banking information before a formal, verified offer is in place.
If something feels off, pause and verify. Contact the company via the channels listed on its website, ask for a video meeting with the recruiter using an official corporate account, and request written details on the role and interview process. If it’s fraudulent, report it to the company, the platform where the outreach occurred, and—when appropriate—local authorities. Acting quickly helps with threat detection and response and protects other candidates from harm.
From a product and security perspective, this is a cross-functional issue that benefits from AI risk management discipline. Strong signals include clear public guidance on recruiting practices, a dedicated reporting mailbox for suspected scams, and hardened email authentication (SPF, DKIM, DMARC). Pair these with privacy-by-design reviews for hiring workflows, recruiter verification checklists, and ongoing education for talent teams. These measures reduce attack surface while reinforcing brand integrity.
If you believe you’ve shared information with a fraudulent recruiter, take immediate steps: change any reused passwords, enable two-factor authentication, place fraud alerts or freezes with credit bureaus as appropriate, and monitor accounts for suspicious activity. Document all communications; they can help security teams and platforms act faster.
Recruitment fraud is emotionally taxing and can erode confidence in the process. Don’t let scammers slow your momentum. Stay vigilant, verify before you trust, and share this warning so others can avoid similar traps. If you’re ever unsure about a message that appears to come from Pendo, pause, validate through official channels, and prioritize your safety first.
In my role leading product management, I take brand trust and cybersecurity seriously—especially when it affects people’s livelihoods. Over the past few weeks, I’ve seen a troubling uptick in brand impersonation and social engineering targeting candidates. It’s a reminder that protecting our community isn’t just a technical problem; it’s a product management leadership and stakeholder management responsibility.
We want to warn you about recent instances of fraudulent job offers purporting to be from Pendo and/or its affiliate companies.
If you receive an unexpected outreach claiming to be from Pendo with a fast-track offer, requests for payment, or a push to move conversations to informal channels, treat it as a red flag. Scammers often spoof logos, clone profiles, and use vague role descriptions to create urgency. Their goal is to extract personal data, money, or access—classic social engineering tactics that undermine data governance and privacy-by-design principles.
Here’s how I advise candidates to protect themselves while keeping their job search momentum. Validate every opportunity through the company’s official careers page and confirm the recruiter’s identity through corporate channels. Check that email addresses and domains match publicly listed corporate information, and be wary of communication conducted exclusively through messaging apps. Never pay fees, buy equipment up front, or share sensitive data like Social Security numbers or banking information before a formal, verified offer is in place.
If something feels off, pause and verify. Contact the company via the channels listed on its website, ask for a video meeting with the recruiter using an official corporate account, and request written details on the role and interview process. If it’s fraudulent, report it to the company, the platform where the outreach occurred, and—when appropriate—local authorities. Acting quickly helps with threat detection and response and protects other candidates from harm.
From a product and security perspective, this is a cross-functional issue that benefits from AI risk management discipline. Strong signals include clear public guidance on recruiting practices, a dedicated reporting mailbox for suspected scams, and hardened email authentication (SPF, DKIM, DMARC). Pair these with privacy-by-design reviews for hiring workflows, recruiter verification checklists, and ongoing education for talent teams. These measures reduce attack surface while reinforcing brand integrity.
If you believe you’ve shared information with a fraudulent recruiter, take immediate steps: change any reused passwords, enable two-factor authentication, place fraud alerts or freezes with credit bureaus as appropriate, and monitor accounts for suspicious activity. Document all communications; they can help security teams and platforms act faster.
Recruitment fraud is emotionally taxing and can erode confidence in the process. Don’t let scammers slow your momentum. Stay vigilant, verify before you trust, and share this warning so others can avoid similar traps. If you’re ever unsure about a message that appears to come from Pendo, pause, validate through official channels, and prioritize your safety first.
I get asked this constantly by boards, CIOs, and product teams: WTF is MCP, and why does it matter for enterprise AI? Here’s my straightforward take from the trenches of rolling out agentic AI across complex, regulated environments—and why it changes how we design, govern, and scale autonomous capabilities.
“Model Control Protocol gives your AI agents arms and legs to go do stuff with your data.” That framing resonates because it’s both simple and accurate. MCP turns passive “chatbots” into active agents that can safely take action within defined guardrails.
In practice, MCP is the connective tissue between models and the tools, systems, and workflows we trust. It standardizes how agents request permissions, execute tasks, and report outcomes—so enterprises can move from demos to durable operations. The benefit isn’t just autonomy; it’s autonomy with accountability, aligned to our AI Strategy and data governance obligations.
When I pilot agentic AI in production, I start with a narrow scope: which systems the agent touches (for example, CRM integration via HubSpot), what actions it can take (read, write, or propose), and what evidence it must log (inputs, outputs, and approvals). That discipline keeps us compliant with privacy-by-design while unlocking real business impact.
Great MCP use cases emerge where read-write actions compress time-to-value. Think: pulling Amplitude analytics cohorts to personalize outreach, auto-generating Pendo in-app guides based on feature adoption, or triggering customer support workflows with predefined playbooks. Each action is observable, reversible, and measured—because in the enterprise, repeatability beats novelty.
From a product management leadership perspective, I treat MCP-enabled agents like any other product surface. We define clear outcomes, not outputs: success rate per task, mean time to resolution, quality score, and safety incidents. We validate uplift with A/B testing and a minimum detectable effect (MDE) before scaling. Then we feed results into an Agent Analytics dashboard, just as we would for product-led growth funnels.
Governance is where MCP earns trust. I enforce least privilege, time-boxed credentials, environment isolation, and tamper-evident audit logs. Every tool call is tied to a business purpose, owner, and SLA. We integrate with existing threat detection and response processes so cybersecurity teams see the same telemetry they’re used to—no shadow AI, no surprises.
There’s also an adoption playbook that works: start with a contained domain, ship a sandboxed agent, require human-in-the-loop approvals, then progressively relax controls as accuracy and alignment improve. Document the boundaries in plain language, and instrument everything from day one. This is how we de-risk AI risk management while accelerating impact.
The most exciting shift is cultural: teams move from asking “Can the model do this?” to “What outcomes should the agent own—and what guardrails make that safe?” That mindset unlocks empowered product teams, clearer ownership, and faster iteration. MCP is simply the operational backbone that lets those choices stick.
If you’re evaluating where to start, pick one workflow with high frequency, clear rules, and measurable outcomes. Wire it to MCP with tight scopes, ship it to a friendly cohort, and learn aggressively. Autonomy isn’t the end goal—reliable, governed value is. MCP just makes that scalable.
Every week, I watch the cybersecurity landscape bend under the pressure of AI. The pace isn’t linear—it’s compounding. What worked for IT teams last quarter often needs a rethink today, and the difference between merely coping and truly competing lies in how quickly we adapt our strategy, tooling, and operating rhythms.
Learn the ways in which AI is transforming both cybersecurity offense and defense for IT teams.
From my vantage point leading product strategy, I see three shifts that matter most right now: AI is supercharging attackers, accelerating defenders, and reshaping governance. Together, they redefine how we prioritize investments, measure risk, and align product and security roadmaps.
First, AI has leveled up the offense. Large language models can industrialize social engineering—hyper-personalized spear-phishing at scale, deepfake voice notes that spoof executives, and highly convincing support chats that trick users into bypassing controls. Code-generation tools lower the barrier to crafting polymorphic malware and automating reconnaissance. The net effect is ruthless efficiency: more credible lures, faster campaigns, and broader reach with fewer human operators. I now assume adversaries have an AI co-pilot—and plan defenses accordingly.
Second, AI is accelerating the defense. Modern detection and response stacks are moving beyond rules to behavioral analytics—correlating identity signals, endpoint telemetry, and network events to spot subtle anomalies that signature-based tools miss. Copilot-style assistants are augmenting SecOps by summarizing incidents, explaining probable root cause, and proposing next steps. The aim isn’t blind automation; it’s decision acceleration—shrinking mean time to detect and respond while reducing analyst toil. On the build side, AI-assisted code scanning and dependency analysis help teams shift security left, catching vulnerabilities earlier and turning secure defaults into muscle memory.
Third, governance is being rewritten in real time. As AI models ingest sensitive data and generate code and content, data governance and privacy-by-design move from compliance checklists to active risk management. We’re formalizing AI risk management alongside traditional AppSec: model inventories, usage policies, red-teaming prompts, and guardrails against prompt injection and data leakage. Identity remains the control plane—zero trust principles, least privilege, and continuous verification become nonnegotiable. I’ve found that aligning security, product, and IT leadership on a single policy-as-code backbone prevents drift and keeps audits predictable.
Practically, I guide teams to start with a crown-jewel inventory: What data and systems would materially impact customers, revenue, or brand if compromised? Map data flows, instrument comprehensive telemetry, and prioritize detection coverage where it matters most. Choose AI to augment before you automate—prove the loop with humans in the middle, then graduate to higher autonomy levels with clear rollback paths and audit logs.
Culturally, this is a product problem as much as a security one. We bring empowered product teams and SecOps into the same room, set measurable objectives (signal-to-noise ratio, mean time to contain, escaped defect rate), and iterate with the same cadence we use for product features. When security outcomes are treated as customer outcomes, adoption soars and friction recedes.
The takeaway: AI has tilted the field, but not inevitably against defenders. With a clear AI strategy, disciplined data governance, and pragmatic automation, IT leaders can turn reactive security into a proactive advantage—meeting attackers’ speed with speed, and outlasting them with better judgment.