Organizational change is exhausting—so I stopped trying to force it. After years of leading product teams, I’ve learned that trying to fix the people and processes around me is almost always wasted energy. If you’re eager to champion a better way of working inside a resistant organization, there’s a more sustainable path that actually drives results.
Here’s my starting point: individuals can’t change their organizations. I’m often asked to “train the PMs” or “install discovery practices,” but without executive sponsorship, organizational pain, and urgency, nothing moves. I now decline those well-intentioned requests and focus instead on creating the conditions for change.
My readiness check is simple and ruthless. Pain — organizational pain felt by leadership, not just you. Urgency — there has to be a cost to inaction. Awareness — people need to know solutions exist. If I can’t articulate these three clearly, I narrow the scope to what my team and I can control and demonstrate.
Practically, I elevate organizational pain by making it visible and quantifiable: missed outcomes vs output OKRs, customer churn tied to unmet needs, increased operational load from legacy workflows, or cycle time and deployment friction that slow learning. I create urgency by modeling cost-of-delay and showing the trade-offs we’re already making. And I build awareness by running small, transparent experiments that show there’s a credible alternative—continuous discovery, empowered product teams, and product trios solving for outcomes, not output.
“Organizational change starts with you — but it starts with you changing you, not your organization.” I take that literally. I refine my own discovery habits, make my assumptions explicit, and raise the quality bar on evidence. Whether it’s adopting AI responsibly in our workflow or redesigning how we do customer interviews, I change me first and let the results speak.
Show your work, don’t advocate your conclusions. Instead of arguing for “the right way,” I surface the pain, share how I reached my conclusion, and let others draw their own insights. I circulate decision logs that link customer evidence to product decisions, include short snippets from interviews, and map outcomes to proposals. That transparency lowers defenses, builds stakeholder buy-in, and shifts the conversation from opinion to observable facts.
Working within constraints, not against them. Stuck in a rigid, feature-factory process? You don’t have to change quarterly planning to do great discovery. Add customer context. Frame features around outcomes. Layer in the habits without touching the formal process. I’ve embedded discovery into existing rituals: adding customer insights to PRDs, tying features to measurable outcomes, and using thin-slice experiments that fit inside current delivery cadences. Over time, those habits compound.
The ripple effect is real. Teams that do great work and show it publicly become the ones everyone wants to emulate. That’s how influence actually spreads. I make results visible—brief Looms walking through our reasoning, dashboards that track outcome movement, and internal write-ups that highlight how the work changed a customer behavior. Visibility turns quiet wins into organization-wide momentum.
If you want a place to start this week, try this: define a sharp outcome, run three quick customer interviews, share your notes and decision rationale openly, and ship one small experiment tied to that outcome. Use the data to refine your next step and repeat. In a month, you’ll have a trail of evidence, not a pitch deck—and that’s what shifts minds.
In the end, sustainable change comes from consistent practice, not fiery advocacy. Focus on outcomes, make the pain and cost-of-inaction undeniable, and keep showing your work. The organization will move when it’s ready—your job is to make “ready” happen sooner by modeling what good looks like and making it impossible to ignore.
I’ve watched the rise of product engineering up close, and it’s reshaping how we build software. The old model of rigid handoffs and separate functions is giving way to small, empowered product teams where engineers own the customer problem end to end. That shift isn’t just cultural—it’s a performance advantage that compounds with every release.
I often summarize it this way: “Product engineers are taking over. They ship code, talk to users, and own outcomes—no handoff required. Here’s what the role is, and why it matters now.”
When I say “product engineer,” I’m describing a builder who goes beyond writing code. I expect them to partner in product trios with product management and design, participate in continuous discovery, and make decisions grounded in product strategy and real customer insight. They don’t toss features over a wall; they own the problem, the solution, and the measurable outcome.
Why now? Modern delivery practices like CI/CD and feature flags compress feedback loops, while behavioral analytics and session replay make customer friction visible in real time. As expectations rise for quick iterations and clear value, teams that reduce handoffs and align around outcomes outperform on DORA metrics such as deployment frequency and lead time for changes.
Day to day, a strong product engineer blends discovery and delivery. They join customer interviews, review support tickets, analyze usage patterns, and run A/B testing to validate hypotheses. Then they ship code in small, safe increments, instrument telemetry, and watch adoption and retention signals to confirm they’re moving the numbers that matter.
Team shape matters. I favor compact, cross-functional squads anchored by product trios, each with explicit outcomes vs output OKRs. Product engineers often operate like forward deployed engineers, partnering with customer success and solutions engineering to learn at the edge of real-world usage. This proximity to customers turns ambiguity into insight—and insight into product leverage.
Accountability is concrete. We track DORA metrics for delivery health and pair them with product outcomes such as activation, time-to-value, and Net Recurring Revenue (NRR) drivers. The combination keeps us honest about both how fast we move and whether what we ship truly works for customers.
The hiring profile is distinct. I look for engineers who are curious about the “why,” comfortable with trade-offs, and energized by customer conversations. They can navigate architectural complexity, but they also translate user feedback into crisp product bets. Many grow into natural facilitators of discovery rituals and developer evangelism across the organization.
If you’re getting started, pilot a single squad. Establish clear outcomes vs output OKRs, invest in CI/CD and feature flags, and commit to continuous discovery with weekly customer interviews. Give the team ownership of a KPI tied to product strategy, and measure progress with DORA metrics plus usage and retention signals. The early wins—fewer handoffs, faster learning, tighter feedback loops—build momentum quickly.
In short, product engineers thrive where accountability, autonomy, and user empathy meet. They reduce wasteful coordination, shorten the path from insight to impact, and ensure we ship code that customers actually adopt. That’s why this role is reshaping how software gets built—and why the teams that embrace it will set the pace for everyone else.
I’m processing a milestone moment for SaaS, AI strategy, and product leadership. One statement captures the news with clarity: “We’re excited to share that we just signed an agreement for Salesforce to acquire Fin for ~$3.6B. The transaction is expected to close in the fourth quarter of Salesforce’s fiscal year 2027.” As a product leader, I see this as a high-conviction bet on agentic AI, Customer Agents, and CRM integration at massive scale.
The backstory matters, and it’s remarkable: “Fin started as Intercom 15 years ago. We changed our name to cap our transformation just weeks ago. We were a darling of the SaaS era and invented so many of the patterns you see in software today. Nearly four years ago, in need of a reboot, we jumped on weeks-old modern LLMs to create and define the category we know as Customer Agents today.” That arc—from SaaS pioneer to LLM-powered category creator—illustrates how bold pivots, shipped with urgency and clear product strategy, can reset the trajectory of a company and a market.
From a product management lens, this deal reinforces a few truths: category creation rewards those who move first with conviction; “reboots” succeed when they’re anchored in genuine customer value; and modern LLMs, applied through disciplined roadmapping and eval-driven development, can unlock step-change outcomes in customer support ai strategy and product-led growth. It also signals the rising centrality of agentic AI and operational AI workflows inside the CRM.
The leadership dimension is just as instructive. As the announcement framed it: “Salesforce invented modern software and SaaS. And Marc Benioff is like the final boss of tech founder CEOs. In seat for 27 years, he’s one of the last of his era. Still pushing, pivoting, placing big bets.” That ethos—placing big, principled bets while adapting the operating model—sets the tone for what sustained product management leadership looks like at scale.
Customer continuity and acceleration are clearly emphasized: “To our customers: Over the past few years we’ve been shipping intensely. Including recently our groundbreaking model, Apex, and our paradigm-defining internal agent, Operator. With the resources of Salesforce this will only accelerate. And yet little will practically change. I’ll still be CEO, Des will still be running R&D, we’ll both still be committed to continuing to lead this category. Thank you very sincerely and deeply for your belief in us.” For practitioners, the signal is strong: continued focus on shipping, sharper execution readiness, and tighter integration paths inside the Salesforce ecosystem.
Smiles, clinking glasses, and a roundtable toast in a cozy private room capture the energy of a big day—celebrating Salesforce's definitive agreement to acquire Fin and the teams joining forces for what's next.
There’s a human heartbeat here too: “While this is not the end, it is a major, pivotal, special, and emotional moment for us.” Moments like this remind me that building enduring products is equal parts craft and courage—powered by teams who commit to the long game, navigate uncertainty, and still ship relentlessly.
Strategically, I expect near-term priorities to center on secure data flow and governance, deep CRM integration, and unifying telemetry for Agent Analytics across channels. On the roadmap, I’d anticipate tighter alignment between LLM safety, retrieval-first pipelines, and enterprise-grade observability—plus thoughtful go-to-market strategy enabling sales-led growth to complement product-led growth. The real unlock comes when Customer Agents are natively orchestrated with Service, Sales, and Marketing workflows—measured with clear outcomes vs output OKRs and reinforced by robust knowledge management.
For fellow product leaders, the takeaways are actionable: define category boundaries with crisp value propositions; balance speed with governance; invest in eval-driven development and continuous discovery; and keep your product trios aligned around measurable customer outcomes. Above all, build the operating cadence—metrics, rituals, and talent—that lets you compound small wins into durable differentiation.
And I appreciate the spirit of this closing line: “And now, time to get back to work. See you at our next product launch in a few weeks. (:” That’s the mindset that turns a headline into execution: celebrate briefly, then ship the next proof point.
I’m continually evaluating how to invest in my team’s professional development in ways that create lasting capability, not just momentary enthusiasm. Recently, I revisited a compelling conversation featuring Teresa Torres and Petra Wille that zeroes in on how product teams actually learn best—especially when we’re accountable for product management leadership and sustainable practice change across empowered product teams.
Listen to this episode on: Spotify | Apple Podcasts
What's the best way to invest in your team's professional development — train everyone at once, let people self-direct, or something in between?
In my experience, the answer depends on your goals, the maturity of your product discovery habits, and how you create peer accountability. What resonated most with me was their argument that small, intentional groups are a powerful (and underused) learning model—one that aligns with how we build momentum in product discovery, product strategy, and continuous discovery routines.
Three Models of Team Learning
Train everyone at once — builds shared language, but not everyone is ready at the same time
Self-directed learning — works for highly motivated individuals, but lacks accountability
Small-group learning — the sweet spot: peer accountability, shared momentum, and just-in-time relevance
Across my teams, I’ve seen organization-wide training create useful common ground, but it rarely changes day-to-day behaviors without a follow-on mechanism for practice. Self-directed learning can inspire, yet it often fails to translate into consistent habits without peer pressure and shared goals. Small-group learning, especially within product trios or adjacent squads, consistently drives the most adoption because it blends relevance, peer accountability, and just-in-time application to real customer interviews, roadmap decisions, and stakeholder management challenges.
Why Learning Together Works
Creates natural accountability and deadlines
Helps people apply concepts to their own real work
Especially valuable for product leaders, who rarely have built-in peers to learn alongside
I’ve found small cohorts particularly effective for product leaders who need a safe space to pressure-test decisions, compare notes on org design, and align on product strategy trade-offs—without slipping into status updates. When leaders learn together, they build shared muscle memory that makes it easier to reinforce practices like continuous discovery and communities of practice across the organization.
Group/team: real work in the room, peer learning, bridges between leaders who rarely collaborate
Keep participants as close colleagues — trust and vulnerability go up when people already know each other
One-on-one coaching is invaluable for personal reflection and targeted growth. But when I need to accelerate collective behavior change—like improving discovery cadence, refining opportunity solution tree reviews, or aligning around outcome-based roadmapping—group coaching wins. Keeping participants as close colleagues increases vulnerability and candor, which in turn speeds up learning and leads to real changes in how teams plan, prioritize, and ship.
Key Takeaways
Start a book club — debriefing together beats reading alone
Train pilot teams before rolling out org-wide
Encourage duos or trios to take courses together
Match your learning format to your actual goal
Keep coaching groups tight for more honest, productive sessions
Here’s how I operationalize this: I start with a pilot team to validate the learning format and cadence, then expand to adjacent trios to build a network effect. We anchor learning to current initiatives (not abstract theory), ensure weekly touchpoints, and capture playbooks in our internal knowledge base so improvements persist beyond the cohort.
Resources & Links:
Follow Teresa Torres: https://ProductTalk.org
Follow Petra Wille: https://Petra-Wille.com
Mentioned in this episode:
Communities of Practice
Petra Wille's book Strong Product Communities – The Essential Guide to Product
Become a Better Product Leader: A 52-Week Transformation Journey – Petra's email course with quarterly live Q&A
Teresa Torres’ book Continuous Discovery Habits
Continuous Discovery Habits (CDH) Book Club
Petra’s STRONG Product People Corporate book clubs
Pendomonium can be treated as more than a source of product ideas. Its practical value lies in connecting an identified growth problem to behavioral evidence, a targeted intervention, and a measurable follow-through plan.
The supplied Pendo account spans analytics, onboarding tools, product strategy, expert advice, and peer conversations. Viewed together, those elements form a repeatable operating system for converting conference learning into product growth experiments.
Conference learning becomes useful when it enters a growth loop
The Pendo article describes several distinct kinds of conference value: behavioral analytics and retention analysis can clarify where users struggle; journey mapping and continuous discovery can improve the framing of those problems; and in-app guides, product tours, or broader UX changes can become possible responses. Sessions about empowered teams, stakeholder alignment, and outcome-focused roadmaps address the organizational conditions needed to execute those responses.
The synthesis is a four-part loop: diagnose a meaningful behavior, select an intervention that fits the observed friction, define the intended outcome, and establish ownership for the work. No single conference session completes that loop. A talk may sharpen the hypothesis, a workshop may produce a prototype, an expert conversation may challenge the targeting logic, and a peer discussion may provide a useful benchmark.
This framing also changes the standard for conference return on investment. The relevant question is not how many notes or feature ideas an attendee collected. It is whether the event improved a decision that can be tested against an activation, onboarding, or retention outcome.
Begin with a constrained product growth question
The Pendo author recommends defining explicit outcomes before booking the trip: one activation measure to improve, one source of onboarding friction to address, and one discovery practice to strengthen. That constraint is useful because it turns a large agenda into a decision filter. Sessions become relevant when they contribute evidence, methods, or execution support for the selected problem.
Preparation should make the question concrete. The source advises bringing access to analytics dashboards and, where possible, a staging environment. An attendee could then inspect an event taxonomy, review a relevant session replay, or draft guidance for a defined segment while expert input is available. These activities are more actionable than collecting generalized advice because they expose assumptions about instrumentation, audience selection, and user context.
The same discipline applies to office hours. According to the article, these appointments can fill quickly, and attendees should arrive with precise questions, such as an unexplained activation drop-off or uncertainty about a guide-targeting rule. A useful expert conversation should end with a clearer hypothesis or experiment, not merely a product demonstration.
Match evidence, intervention, and measurement
The strongest practice implied by the source is to keep diagnosis and intervention connected. Session replay, behavioral analytics, retention analysis, and journey mapping illuminate different parts of user behavior. In-app guides and tours are possible treatments, but they should not become automatic answers to every point of friction.
Product growth question
Relevant conference input
Useful work product
Where does progress break down?
Behavioral analytics, retention analysis, journey mapping, or session replay
An evidence-backed problem statement
What could reduce the friction?
Guide and tour workshops, UX examples, or expert feedback
A testable intervention rather than an unprioritized idea
Who should receive the intervention?
Segmentation and targeting guidance
A defined audience, context, and trigger
How will the team evaluate it?
Activation and onboarding discussions
A success measure tied to the original problem
This sequence helps prevent tool-first product management. If replay evidence suggests that users cannot understand an interface, contextual guidance might be appropriate. If the underlying workflow is structurally difficult, adding another tour could conceal rather than remove the problem. The conference contribution is therefore not just exposure to Pendo capabilities; it is the opportunity to examine when each capability fits the diagnosed need.
The author reports applying workshop ideas to experiments and subsequently seeing faster time-to-value for new users. That is a useful practitioner account, but it is not presented as comparative evidence. Teams adopting the practice should still establish their own baseline, success measure, and evaluation method.
Use a return-home cadence to preserve accountability
Conference insights decay when they remain in personal notes. The source proposes a note structure containing the problem, supporting data, proposed intervention, and success measure. It also describes leaving the event with two prioritized experiments, named directly responsible individuals, and an execution-readiness checklist.
Before the event: choose the activation measure, onboarding problem, and discovery practice that will guide agenda decisions.
During sessions and workshops: record evidence and assumptions separately from proposed features or guidance.
During expert and peer conversations: pressure-test the hypothesis, instrumentation, targeting logic, and execution constraints.
Within 24 hours of a useful introduction: follow up with a concise summary and a specific next step, reflecting the networking practice recommended in the source.
Within 48 hours of returning: hold the debrief described by the author, prioritize the experiment backlog, and agree on a shared activation or onboarding milestone.
Across the next 30, 60, and 90 days: review whether ownership translated the selected insights into tests, decisions, and measurable learning.
Intentional networking can support this cadence rather than sit outside it. The article recommends meeting peers with comparable metrics, product operations leaders, and solutions engineers. Their value is not simply expanding a contact list: each perspective can expose a different weakness in the plan, from an unrealistic benchmark to an instrumentation gap or an unresolved delivery dependency.
Key takeaways
Anchor the event to a specific growth outcome and a defined source of user friction.
Use analytics, journey evidence, workshops, expert advice, and peer input as complementary parts of one decision process.
Select guides, tours, or UX changes only after diagnosing the behavior they are intended to change.
Capture every promising idea with supporting evidence, a success measure, and a responsible owner.
Use the post-event debrief and 30-60-90 day follow-through to turn conference learning into accountable experimentation.
The durable opportunity is to make Pendomonium the start of a learning cycle rather than the end of an annual event. Teams that arrive with a narrow question and leave with an owned experiment can carry the conference’s value into their next product decision.
For an analytics product, positioning cannot stop at a market-facing promise. The promise has to appear in onboarding, become visible in user behavior, withstand technical evaluation, and give sales and product teams a consistent explanation of value.
Taken together, two Shivam.Consulting profiles describe complementary sides of that system at Amplitude. The profile of Darshil Gandhi emphasizes competitive, partner, and technical credibility, while the profile of Tommy Keeley concentrates on acquisition, activation, engagement, and experimentation. Their combined lesson is that positioning and product-led growth work best as one evidence loop rather than as separate marketing and product programs.
Positioning becomes credible inside the product
Product positioning defines the problem a product addresses, the value it promises, and the reasons a buyer should choose it. Product-led growth puts that proposition under immediate pressure: users encounter the product directly and can compare the promise with the experience.
The Darshil Gandhi profile reports that Gandhi leads competitive intelligence, partner product marketing, and technical marketing at Amplitude after serving as a principal on a solutions engineering team. The article treats that technical background as important because positioning must reflect real implementations, not merely persuasive language. It connects this approach to field-tested demonstrations, documentation, reference architectures, integrations, and feedback from sales and solutions engineering.
The Tommy Keeley profile approaches the same credibility question from the user’s side of the interface. It describes guided onboarding, product tours, progressive disclosure, contextual prompts, and other in-product guidance as ways to move users toward an early experience of value. Funnel instrumentation and session replay are presented as tools for locating friction in that journey.
These perspectives form a useful positioning test. A claim must be technically defensible during evaluation, understandable when a user first enters the product, and observable in subsequent behavior. If one of those conditions fails, stronger copy alone is unlikely to repair the mismatch.
Behavioral evidence closes the positioning loop
The two profiles both assign behavioral analytics a role beyond reporting. In the Gandhi article, Amplitude analytics are used to validate claims and identify themes associated with competitive wins. In the Keeley article, behavioral analytics, cohort analysis, funnels, pathing, and retention analysis help determine which actions are associated with longer-term value and where users abandon important journeys.
This creates a feedback loop between market language and product behavior. Positioning proposes that a capability produces a meaningful outcome. Instrumentation then shows whether intended users reach that capability, adopt it, and continue using the product. Field feedback adds another layer by revealing which claims survive buyer scrutiny and which require qualification or clearer proof.
The distinction between correlation and causation remains important. Cohort patterns can identify promising behaviors, but an association with retention does not by itself prove that encouraging the behavior will improve retention. The Keeley profile therefore pairs behavioral analysis with controlled A/B testing, minimum detectable effect thresholds, guardrail metrics, sequential testing, and feature flags. In this model, analytics generates hypotheses and experiments provide stronger evidence for decisions.
The same discipline applies to AI-enabled personalization. The Keeley article describes using generative AI for tailored onboarding, recommended next actions, and summaries of activity patterns, while placing interventions behind feature flags and evaluating them through controlled experiments with privacy-by-design constraints. AI is therefore framed as an extension of the measurement system, not a substitute for a clear value proposition.
A shared driver tree connects the market promise to growth
A recurring mechanism across both sources is the driver tree. The Gandhi profile recommends connecting capabilities to customer outcomes so competitive narratives remain consistent. The Keeley profile starts with a North Star Metric and maps drivers across acquisition, activation, engagement, retention, and monetization. Combined, these uses turn the driver tree into a translation layer between positioning and product-led execution.
At the top sits the outcome the product claims to enable. Beneath it are the behaviors that indicate users are realizing that outcome, followed by the product capabilities and interventions intended to support those behaviors. Competitive intelligence can examine whether the top-level promise is distinctive and relevant. Technical marketing can verify that the enabling capabilities work as described. Growth teams can measure whether users discover and adopt them.
This structure also changes acquisition decisions. The Keeley profile argues for optimizing beyond clicks toward post-signup behaviors associated with retention. That requires congruence among the landing-page message, the users being attracted, and the experience after signup. A campaign that produces registrations but draws people away from the product’s strongest use case may improve a top-of-funnel measure while weakening the product-led system.
Growth loops should follow the same logic. The Keeley article identifies collaboration invitations, user-generated content, and shareable artifacts as possible viral mechanisms. Their strategic value depends on whether sharing is a natural expression of the product’s core value. When distribution emerges from useful product behavior, the loop reinforces positioning; when sharing is detached from that value, it risks becoming a short-lived acquisition tactic.
Key takeaways
Positioning should be treated as a testable claim linking a capability, a user behavior, and a meaningful outcome.
Technical evidence, field feedback, and behavioral analytics answer different questions; credible differentiation needs all three.
A shared driver tree can align competitive intelligence, product marketing, growth, design, engineering, sales, and solutions engineering around the same value logic.
Acquisition quality should be judged partly by meaningful post-signup behavior, not solely by traffic or registration volume.
Onboarding, in-product guidance, and viral loops should express the core value proposition rather than operate as disconnected growth tactics.
Personalization, including AI-enabled interventions, needs feature controls, privacy safeguards, and experimental evaluation.
Organizational alignment is part of the positioning system
Neither source presents this work as the responsibility of a single function. The Gandhi profile emphasizes collaboration among competitive intelligence, partner product marketing, technical marketing, sales, solutions engineering, and product. The Keeley profile describes empowered product trios, continuous discovery, and outcome-focused roadmaps that connect engineering, design, and product decisions to measured growth drivers.
The synthesis suggests a practical division of responsibility without creating separate agendas. Market-facing teams clarify the buyer’s alternatives and the basis for differentiation. Technical teams establish what can be demonstrated and implemented. Product teams reduce the distance between signup and experienced value. Growth teams measure the journey and test interventions. Partners can make integrations and associated use cases more repeatable.
The forward opportunity is to make this loop increasingly explicit: every major positioning claim can be connected to product evidence, every growth initiative can be checked against the intended value proposition, and every field objection can become an input to product discovery. That approach gives Amplitude’s reported playbooks a broader implication for product-led companies: differentiation becomes more durable when the story, the implementation, and the observed behavior keep correcting one another.
In competitive markets, I see two options: try to win the game competitors set, or choose to play a different game. In the "Customer Agents" category, I’ve watched too many glossy, fabricated demos—especially around voice—mask the real challenges. Voice is just extremely hard. We all know the future of customer experiences will be Agent-driven voice, yet most of us haven’t actually spoken with a modern AI Agent when calling a business because the tech hasn’t been truly ready in the wild. Today, the bar moves.
What changed? There’s a live, public demo of cutting-edge voice tech you can stress test yourself—no smoke, no mirrors. I recommend taking it for a spin: https://fin.ai/voice. It’s fast, natural, and, yes, very, very good.
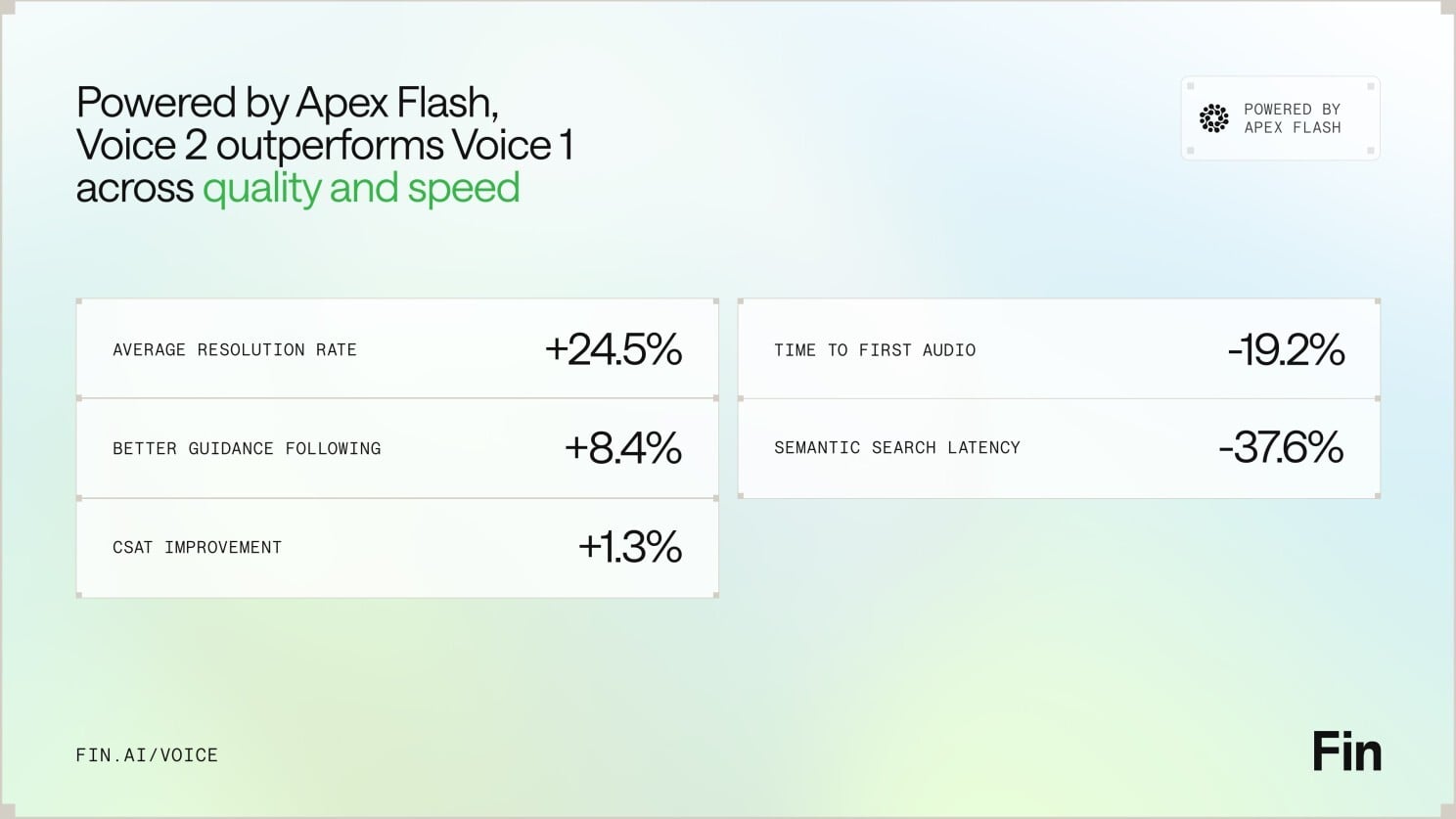
For context, yesterday brought Apex Flash, their newest and fastest model, built for the unique demands of low latency channels like voice. Today comes Fin Voice 2, a major upgrade to Fin Voice with over 20 new features, and the first product built on Apex Flash.
Here are the three things that stood out to me—and why they matter for customer support AI strategy and product strategy.
First — thanks to Apex Flash, Fin Voice 2 is now the fastest, most natural Agent for phone, with higher resolution rates and customer satisfaction scores than ever before. Apex Flash is trained on millions of customer experience interactions, fine tuned for customer service, and can be configured to understand all your knowledge and follow all your policies. The result is higher resolution at significantly lower latency—the best of both worlds for voice AI agent performance.
Speed and naturalness here aren’t accidental. Most voice AI products are slow because they convert speech to text, send it to a general model, get a text answer, and then convert it back to speech. Fin Voice 2 was designed to work differently, separating the real time layer that handles speech processing, and the layer that generates answers. That architecture is purpose-built for the demands of customer service on voice.
Powered by Apex Flash, Fin Voice 2 raises the bar on quality and speed—boosting resolution rates and guidance following while cutting time to first audio and semantic search latency, with a lift in CSAT too.
Second — Fin Voice 2 can handle complex queries end to end: taking actions in external systems, verifying callers’ identities, processing refunds, booking appointments, and more. Phone is a high-stakes channel, and Fin adapts to customers across emotional states, clarifies when needed, and confirms key details before taking action. Most of the time, Fin can resolve the query in full, and when it can’t, it seamlessly hands off to the human team, maintaining full customer context and history. You also get multiple improvements to call quality, plus proactive outbound calls to follow up on unresolved issues—all orchestrated by robust AI workflows.
Third — Fin Voice 2 gives you total control with industry-leading tools to configure and manage how Fin behaves. You get rich, detailed insights into call behavior and quality, the most common topics of calls, and one-click recommendations to improve. As with everything in Fin, you can fully self-serve and then manage it all with ease, without requiring professional services. Many vendors only let you set up their voice agent under supervision; with Fin, you get everything you need to iterate fast.
If you haven’t tried the demo yet, go check it out: https://fin.ai/voice. If you prefer to wait, don’t be surprised when you end up speaking with it at a favorite brand soon.
From a product management lens, this is what matters: latency is a feature customers feel; transparency builds trust in enterprise AI; and control is non-negotiable for CX leaders. The combination of a purpose-built, agentic AI architecture, measurable gains in resolution and CSAT, and true self-serve configuration signals that voice is moving from prototype theater to production reality. That’s the different game I want our industry to play.
I spend a lot of my time asking a deceptively simple question: what does excellent marketing actually look like in 2026? From the vantage point of product leadership, the answer isn’t a spreadsheet or a channel plan—it’s a feeling. Beloved tech brands earn the benefit of the doubt, create gravity around their roadmap, and make customers proud to belong. That kind of momentum is not an accident; it’s a system.
Here’s the hard truth I’ve learned building and scaling products: giving teams different goals creates dysfunction. When brand, demand gen, product marketing, and comms run on fragmented OKRs, you manufacture internal headwinds. “Marketing is one engine – not separate pieces.” One strategy, one narrative, one set of outcomes—expressed through different craft disciplines and time horizons.
That unity of purpose clarifies executive roles, too. The real difference between an SVP and a CMO is scope and narrative ownership. A great CMO architects the whole system—portfolio allocation, brand architecture, integrated go-to-market strategy, and the bar for creative taste—while refusing to get dragged into decisions they should never be making (for example, approving every headline or micromanaging channel tactics). Leaders should decide the outcomes, standards, and constraints; teams should control the craft.
On portfolio design, I run marketing like a portfolio of moonshots. You need a healthy mix: proven programs that compound, emergent bets that learn fast, and a small set of true moonshots that can change the slope of the curve. The point isn’t bravado; it’s risk-balanced exploration. If everything ships safely, you’re under-investing in differentiation. If everything is a swing for the fences, you’re not building a repeatable growth engine.
This is where taste becomes a strategic advantage. “Ubiquity is the opposite of cool.” If you want to be beloved, you cannot treat every channel, audience, and moment as equal. Early on, selective distribution, distinctive creative codes, and tight community loops create status and meaning. Later, you scale without sanding off the edges that made the product special.
Why do a few companies build a flywheel of momentum while others stall? They align story, product, and distribution. The product earns trust, the narrative creates aspiration, and the go-to-market strategy ensures the right customers experience both at the right time. Then perception cycles kick in—the Silicon Valley clock turns—and irrational optimism or skepticism can amplify signals. The antidote is compounding proof: consistent product shipping, community advocacy, and creative that makes people care.
Scaling taste across an organization is teachable. I codify brand principles, narrative guardrails, and examples of “right” versus “almost right.” I replace abstract feedback with decision rubrics—what we keep, kill, or revise and why. I run recurring creative reviews with a small cross-functional council, so judgment compounds. Taste can’t be fully automated, but it can be operationalized: shared references, a story bible, and a high bar for craft that’s explicit, not mystical.
In a post-LLM world, the fundamentals haven’t changed—but the frontier has. Generative tools supercharge iteration and research, yet the artistry never really left. You still need a point of view, a tension worth resolving, and a value proposition that’s felt, not just stated. Can taste be encoded in software? Parts of it—pattern libraries, style constraints, data-driven feedback—absolutely. But the spark that makes work unforgettable remains human: judgment, risk tolerance, and the courage to ship something that might not fit the playbook.
That’s why telling an optimistic, yet realistic story about AI matters. Over-automation drains humanity; under-automation wastes potential. The best work pairs AI Strategy with craft leadership: LLMs for rapid exploration, humans for narrative decisions and ethical judgment. Your message should show how AI expands customer agency, not just efficiency.
The brand-versus-growth debate is a false choice. The right story accelerates pipeline, and the right demand programs reinforce the brand. Look at Apple’s discipline around product truth and design codes, or Google Chrome’s “The Web Is What You Make of It (Dear Sophie)” for proof that emotion and utility can co-exist. Notion, Pinterest, Square, HubSpot, and Harley-Davidson show how community, identity, and product-led growth interlock when the company knows exactly what it stands for.
When it comes to launches, I’ve learned that announcement videos full of humans, lack humanity. Overproduced gloss often dilutes the truth customers seek: what problem does this solve, how quickly can I feel the value, and why does it matter now? Real users, real context, and a crisp arc from problem to promise will outperform most theatrics.
Practically, I architect my week to protect taste and outcomes. Early-week for strategy, portfolio reviews, and cross-functional alignment; mid-week for deep creative and product marketing work; late-week for decision clears and postmortems. I time-box “disruptive energy”—space to chase non-obvious ideas—and I guard it like any critical meeting. Without protected cycles for exploration, the urgent will always suffocate the important.
If there’s a single takeaway: playbooks are obsolete, but the fundamentals are not. The channels change; the psychology doesn’t. Run one engine. Allocate a true portfolio. Scale taste with rigor. In the AI era, make people care. That’s how beloved tech brands are built—and how they endure.
Procurement should accelerate value, not suffocate it. Listening to this episode, I found myself nodding (and wincing) through a painfully familiar story about how well-intended controls morph into barriers that keep great expertise out. As a product leader responsible for speed, outcomes, and brand experience, I see procurement as a direct mirror of culture—and an often overlooked part of the product operating system.
In the conversation, Teresa is cranky—and honestly, she has every right to be. She’s simultaneously juggling seven speaking engagement contracts, and six of them have become a part-time job in themselves—think 80-page ethics policies, 800-question security forms, and Multi-Factor Authentication (MFA) questions asked 17 different times. Meanwhile, the one company that just put her fee on a credit card? Scheduled, confirmed, and done in two weeks. That contrast is the whole story: friction repels talent; clarity and simplicity attract it.
Petra adds her own horror story—filling out 12 identical Word document forms—and together they surface a deeper truth I’ve seen across organizations: broken vendor processes don’t just frustrate consultants; they stop companies from getting the expertise they actually need. And despite what many assume, company size isn’t the deciding factor—leadership intent and process ownership are.
If you’ve ever wondered why a training got canceled, why a speaker backed out, or why your team can’t seem to bring in outside experts, this is likely the culprit: procurement theater. Repetitive forms, unbounded scope creep, and sprawling security reviews create drag that outlasts any short-term legal or compliance gain. The opportunity cost—lost learning, slower progress, and talent that simply says no—is enormous.
One detail that stood out: with CEO-level buy-in, a legal review timeline collapsed from four months to 10 days. I’ve seen the same thing. Executive sponsorship is the fastest procurement tool there is, and it reveals what the organization truly values. If you can compress the path when a leader cares, you can redesign the path so it’s always faster—without compromising real risk management.
I also loved the clarity of a simple policy from the episode: Teresa’s new policy is straightforward—her paperwork, credit card payment, no vendor setup—or no speaking engagement. That’s not obstinance; it’s a bright-line test for whether an organization respects expert time and understands total cost. The best experts have options, and friction filters them out first.
Here’s how I operationalize this in product-led organizations. Tier risk by engagement type (e.g., one-hour talk vs. long-term software vendor) and match the process to the risk. Offer a credit-card fast lane with standard, plain-English terms for low-risk work. Eliminate duplicate data entry and kill redundant questionnaires. Use a single, secure intake that auto-fills known fields. Track cycle time end to end, and publish SLAs for legal, InfoSec, and finance. Most importantly, make vendor experience a first-class metric—because it is a brand experience.
Security and compliance matter, but they must be right-sized. If you’re buying a keynote, you’re not buying data processing—so why the 800-question security review? Calibrate controls to actual data access and system interaction. The episode even references AWS DynamoDB and GuardDuty, plus Claude Code—helpful reminders that your stack context matters, but not every purchase touches it. Don’t conflate deep technical diligence for a SaaS integration with a simple, no-data engagement.
There’s a reason the classic film Office Space gets a nod—it’s the perfect metaphor for what happens when well-meaning governance calcifies. Bureaucracy compounds over time, usually after adverse events, until startups—or any team that still moves fast—run circles around you. Procurement that treats experts like adversaries won’t win the race that actually matters: learning faster than the market.
If you want the full story, listen to the episode here: Spotify (https://open.spotify.com/episode/2JHnTvnZX2WcFczml7ozKY?ref=producttalk.org) | Apple Podcasts (https://podcasts.apple.com/kh/podcast/procurement/id1794203808?i=1000770701690&ref=producttalk.org). It’s cathartic, but more importantly, it’s a blueprint for fixing what’s broken.
Mentioned in the episode: Hire Teresa to Speak (https://www.producttalk.org/hire-teresa-to-speak/), AWS DynamoDB (https://aws.amazon.com/dynamodb/?ref=producttalk.org), GuardDuty (https://aws.amazon.com/guardduty/?ref=producttalk.org), Claude Code (https://www.claude.com/product/claude-code?ref=producttalk.org), and Office Space (https://en.wikipedia.org/wiki/Office_Space?ref=producttalk.org).
I’d love to hear your experiences and fixes. Where does your procurement flow break, how do you measure cycle time today, and what would it take to create a vendor experience you’d be proud to put your brand on? Drop your thoughts below and let’s trade playbooks.
I’m celebrating the five-year anniversary of Continuous Discovery Habits by inviting you to read it with me this June. As someone who leads product management and coaches product trios, I’ve seen how a shared discovery practice tightens alignment, speeds up learning, and drives outcomes. This month, we’ll go deep on prioritizing opportunities—not solutions—and I’ll guide you step by step so you can apply the ideas on your own team.
Each month, I’m releasing an in-depth reading guide that includes:
We’ll discuss each month’s reading in the comments, and we’ll gather quarterly on a live call to unpack real-world applications, trade wins and missteps, and keep the momentum going.
Joining late? No problem. I monitor the comments on each reading guide throughout the year. Start with the current month or go back to January—whatever works for you. Ask for help, share what’s working, and connect with other readers at any point.
If you want to participate, grab a copy of the book (or dust off your old copy), share the “Spread the Love” videos with your team, block time for the exercises, and register for the community sessions. Let’s do this.
This Month’s Reading
Chapter:
Estimated reading time: ~16 minutes
This month's chapter will introduce you to:
Need a copy? Grab the book
Share the Love with Friends and Colleagues
We learn best in community. Use these short videos to spread the key ideas across your product trios, engineering partners, and stakeholders. Invite them to read along with you so your discovery cadence—and your product strategy—advance together.
Reflect & Discuss What You Read
When we reflect and discuss what we read, we absorb more and apply it faster. This chapter challenges a deeply ingrained habit: prioritizing solutions. I’ve been in those meetings—spreadsheets full of features, heated roadmap debates, and a creeping sense that we’re optimizing outputs rather than outcomes. The shift to opportunity-first thinking changed how my teams frame bets, sequence discovery, and communicate product strategy.
Individual Reflection
Team Discussion
Put It Into Practice
This month is all about shifting from solution-first to opportunity-first thinking. These short, focused exercises will help your product trio practice opportunity prioritization and improve decision speed without sacrificing product discovery rigor.
Exercise: Map Your Roadmap to Opportunities
Time: 45 minutesDo this: With your product trio
Take your current roadmap or backlog and work backwards. For each planned feature or solution:
This exercise often reveals that you're either:
Use these insights to inform your next prioritization conversation.
Exercise: Practice Two-Way Door Thinking
Time: 30 minutesDo this: With your product trio
Choose 3-5 recent or upcoming product decisions. For each one, discuss:
The goal is to calibrate your team's decision-making speed. Two-way door decisions should be made quickly with "just enough" evidence. One-way door decisions deserve more deliberation and data.
Go Deeper: Additional Reading
If you prefer an audio summary of this month’s reading, including the book chapters and the following resources, I’ve included an audio version for members at the bottom of this post.
Related In-Depth Guides
Supplementary Reading
Related Courses
Our Live Discussion Schedule
Our live discussion sessions are for registered members. Sessions are not recorded. Invitations will go out two weeks before the scheduled event—reserve time now.
Audio Summary
Prefer to listen? Stream the audio overview here: June — Prioritizing Opportunities (audio).
Ready to put continuous discovery into action? Grab the book, share the videos with your team, schedule the exercises, and join the community sessions. Opportunity-first product strategy is a muscle we can build together.
The chapters we will be readingA preview of the most important concepts we'll be learning aboutShort videos you can share with friends and colleagues to help spread the ideasIndividual and team discussion questions to help you absorb and engage with the readingTeam exercises to help you put the ideas into practiceAdditional reading to help you go deeper on the core ideasChapter 7: Prioritizing Opportunities, Not SolutionsWhy product strategy happens in the opportunity space, not the solution spaceHow to focus on one target opportunity at a time to deliver value iterativelyUsing the tree structure to simplify prioritization decisionsThe four criteria for assessing opportunities: sizing, market factors, company factors, and customer factorsWhy treating prioritization as a messy, subjective decision leads to better outcomes than scoring formulasThe concept of two-way door decisions and how they apply to opportunity prioritizationWork on one small opportunity at a time – Reduce your batch sizeGetting started with compare and contrast decisions – Choose the right target opportunityTurn big intractable problems into smaller, more solvable problems – The power of decompositionThink about your team's current roadmap or backlog. How much of your time is spent prioritizing features versus understanding and prioritizing customer opportunities? What would change if you flipped that ratio?Reflect on the last time you made a product decision. Did you treat it as a one-way door (irreversible) or a two-way door (reversible)? How did that framing affect your decision-making process and timeline?Consider the four assessment criteria (opportunity sizing, market factors, company factors, customer factors). Which of these does your team currently emphasize most? Which do you tend to overlook or underweight?As a team, list the top 5-10 items on your current roadmap or backlog. For each one, try to identify the underlying customer opportunity it addresses. If you can't clearly articulate the opportunity, what does that tell you about how you're making decisions?The chapter argues against scoring formulas (like RICE or ICE) for prioritization, calling them "made-up math." If your team uses a scoring system, discuss: What is it really measuring? Does it help you make better decisions, or does it just make subjective decisions feel more objective?Walk through a recent prioritization decision. Did you assess options in isolation ("should we build this?") or compare and contrast them? How might your decision have been different with a compare-and-contrast approach?Identify the customer opportunity it's meant to addressWrite it as something a customer might say (e.g., "I can't find anything to watch" not "We need better search")Look for patterns: Are multiple solutions addressing the same opportunity? Are some solutions disconnected from any clear customer need?Spreading yourself thin across too many opportunitiesOver-investing in a single opportunity with multiple solutionsBuilding solutions with no clear opportunity attachedIs this a one-way door decision (hard to reverse) or a two-way door decision (easy to reverse)?If it's a two-way door, what's the smallest step we could take to learn whether we're on the right track?What would we need to see to know we made the wrong choice?If we realize we're wrong, how quickly could we course-correct?Opportunity Solution Trees: Visualize Your Discovery to Stay Aligned and Drive OutcomesCustomer Interviews: Uncover Hidden Insights from Every ConversationPrioritize Opportunities, Not Solutions7 Key Benefits of Using Opportunity Solution TreesProduct in Practice: How 2-Way Door Decisions Helped Simply Business Learn FastProduct in Practice: Getting Started with Opportunity Solution Trees at SuperAwesomeProduct Discovery Fundamentals: Learn a structured and sustainable approach to continuous discovery.Tuesday, June 16, 2026: 9am-10am PDTThursday, September 17, 2026: 9am-10am PDTWednesday, December 16, 2026: 9am-10am PST
Every moment of friction in a product carries a hidden cost: attention drifts, motivation wanes, and the next click becomes a support ticket—or worse, silent churn. Over the years, I’ve learned to treat “stuck” as an urgent product signal, not just an operational nuisance. When we unstick users in the flow, we protect revenue, brand trust, and the momentum that powers product-led growth.
Learn how Amplitude’s Global Support team uses AI Assistant to reduce support tickets, prevent user churn, and increase conversions.
I reference that line often because it captures a proven pattern: meet users where confusion peaks and resolve it instantly. In my practice, the formula is straightforward—pair behavioral analytics and session replay with a just-in-time AI Assistant, routed by clear driver trees. This transforms support from reactive firefighting into a proactive, in-product experience that accelerates onboarding and boosts user activation.
Here’s how I operationalize it. First, I use Amplitude analytics and behavioral analytics to surface high-friction steps—pages with elevated drop-off, loops, or rage clicks. Session replay clarifies the “why” behind the numbers, while cohort and retention analysis reveal who’s most at risk. Then I deploy targeted in-app guides and tooltip design to preempt known pitfalls, while an AI Assistant handles real-time questions with context from our knowledge base and product docs.
The AI Assistant is more than a chatbot. With well-structured AI workflows, it detects intent, pulls precise snippets from docs-as-code, and handles routine issues instantly. When complexity spikes, it executes a graceful handoff to consultative support via Intercom or a Zendesk integration—preserving conversation history and sentiment cues—so humans spend time where judgment matters. This hybrid model keeps response times low without sacrificing quality.
To de-risk changes, I lean on A/B testing and feature flags. I measure time-to-value, activation rate, and funnel conversion as leading indicators, while tracking ticket deflection, CSAT, and NRR as trailing indicators. The goal isn’t just fewer tickets; it’s faster learning loops and a compounding improvement in user outcomes. When we see activation curves steepen and onboarding friction flatten, we know the system is working.
Practically, I start with the top three friction points in onboarding, implement narrow in-app guides, and deploy the AI Assistant with strict guardrails and clear escalation paths. Weekly reviews align product, customer success, and solutions engineering around shared telemetry—so we tune prompts, content, and UI patterns together. Over time, I’ve seen ticket volume decline meaningfully, while conversion and retention rise as users experience fewer dead ends.
If you’re evaluating where to begin, identify the moments where confusion compounds—pricing configuration, integrations, and data mapping are common culprits. Then introduce targeted, context-aware help right where users hesitate. You’ll not only prevent “every stuck user” from turning into a ticket—you’ll convert friction into confidence, and confidence into growth.
Inspired by this post on Amplitude – Best Practices.
Your teams are running more experiments, but decisions are not getting easier. Results arrive late, apparent wins fail to repeat, and every readout starts a new argument about the data.
The fix is not another testing tool or a higher experiment count. You need an operating system that protects validity when traffic, products, models, and customer behavior change underneath you. That system starts before exposure, routes each question to the right evaluation method, and ends with a decision your team can execute.
Give every experiment a decision contract
An experiment should begin with a decision, not a feature. Ask what you will do if the result is positive, negative, inconclusive, or unsafe. If the answer is the same in every case, the test is not worth running.
Turn the proposed test into a short decision contract before engineering begins. Record:
The customer problem: the friction or unmet need you observed.
The causal hypothesis: the product change, the behavior it should alter, and why.
The eligible population: who can enter the experiment and who must be excluded.
The primary outcome: the one metric that determines whether the hypothesis worked.
The guardrails: the measures that can block a rollout even when the primary outcome improves.
The decision thresholds: the minimum effect worth acting on and the conditions for shipping, iterating, stopping, or rolling back.
A driver tree helps you connect the primary metric to the business outcome without pretending that one experiment can prove the entire chain. If the goal is retention, for example, the immediate experiment may be designed to change activation behavior. The contract should distinguish that leading behavior from the longer-term outcome.
Set the minimum detectable effect and guardrails before reading results. The minimum detectable effect is not the smallest movement your analytics can display. It is the smallest improvement that would justify the cost, risk, and complexity of the change. If your available population cannot reliably detect that effect, narrow the question, combine low-traffic variants, choose a more sensitive proximal metric, or do not run the test.
Pre-committing to the metric, stopping rule, exclusions, and decision criteria also limits convenient reinterpretation. Teams can still investigate unexpected patterns, but those findings should become new hypotheses rather than retroactive proof that the original bet won.
Match the question to the cheapest reliable evidence
Production A/B testing is only one layer of experimentation. It is often the slowest and most expensive layer because it consumes customer attention, operational capacity, and statistical power. Use it when real behavior is necessary to resolve a meaningful decision.
Evidence layer
Best question
Move forward when
Offline evaluation
Does the output meet a defined quality, policy, or safety standard?
The candidate passes the agreed evaluation set and regression checks.
Replay or shadow mode
How would the change behave on realistic inputs without affecting users?
Failure patterns, cost, and latency remain inside the operating limits.
Targeted canary
Is the change safe and observable under live conditions?
Telemetry is healthy and no guardrail triggers a rollback.
Controlled A/B test
Does the change cause a valuable shift in user behavior?
The result meets the pre-registered decision criteria.
Progressive rollout
Does the effect and reliability persist as exposure expands?
Segment-level outcomes and operational measures remain acceptable.
This layered model becomes essential for AI products. Prompts, retrieval logic, policies, model versions, and traffic composition can all change the experience. A single production metric cannot tell you whether a decline came from product value, output quality, latency, cost, safety, or an upstream model shift.
Do not use a multi-armed bandit simply because it can direct more traffic toward a leading variant. Bandits are useful when the objective is clear, feedback is timely, and guardrails are dependable. They are a poor substitute for stable measurement or causal understanding. If you need to estimate an effect, learn about segments, or detect delayed harm, retain a controlled comparison.
Engineer trustworthy measurement and reversible delivery
An experimentation program is only as resilient as its event pipeline. A mathematically correct analysis built on shifting event definitions is still wrong. Treat instrumentation as a product interface with owners, documentation, versioning, tests, and observability.
Before exposure begins, verify that assignment, exposure, outcome, and guardrail events share consistent identities and timestamps. Confirm that users enter only the experiments for which they are eligible. Check that retries, duplicate events, delayed ingestion, and cross-device behavior cannot silently change the denominator.
During the run, monitor data quality separately from product performance. Sample ratio mismatch, assignment failures, missing exposure events, sharp volume changes, and implausible segment movements should pause interpretation. Do not explain these signals away because the headline result looks attractive.
Delivery must be reversible as well as measurable. Put material treatments behind feature flags. Start with a targeted canary, watch operational and customer guardrails, and expand exposure in stages. Define who can stop the rollout and make sure that person has both the telemetry and access required to act.
For broad platform or AI changes, maintain a persistent holdout when feasible. A long-lived control gives you a reference point for cumulative effects that short experiments miss, including changes in retention, trust, support burden, and cost. Protect the holdout from accidental contamination and document every change that affects its interpretation.
Scale the program around decisions, not test volume
A central experimentation team cannot design and analyze every test at scale. Product teams need autonomy inside a governed system. Centralize the parts where inconsistency creates shared risk: assignment services, metric definitions, event standards, quality checks, templates, and audit records. Let teams own hypotheses, customer context, treatment design, and decisions inside those guardrails.
Use a lightweight review based on risk. A reversible interface change with a proven metric can follow a standard path. A pricing change, safety policy, ranking system, or shared AI capability deserves stronger review, tighter exposure controls, and a clearer rollback plan. Governance should become more demanding as the blast radius grows.
Maintain a portfolio view rather than a leaderboard of teams by test count. For each active experiment, track the decision it supports, expected value, detectable effect, traffic requirement, risk class, owner, and current evidence layer. This reveals when several teams are competing for the same population, when a strategic question is underpowered, and when multiple small tests should become one coherent learning plan.
Reset a brittle program over 90 days
You can make the operating model concrete without attempting a platform-wide rebuild:
By day 30: audit the backlog and current tests. Stop or consolidate experiments that cannot meet their minimum detectable effect. Identify unreliable events, missing owners, conflicting metric definitions, and launches without explicit decision criteria. For AI surfaces, establish a minimal offline evaluation harness for prompts, policies, quality, and safety.
By day 60: publish standard hypothesis and readout templates. Put high-risk changes behind feature flags, make guardrails visible, and introduce canary exposure. Establish persistent holdouts where broad or cumulative effects matter. Add alerts for instrumentation drift and operational regressions.
By day 90: manage a balanced portfolio across offline evaluations, replay or shadow tests, canaries, controlled experiments, and progressive rollouts. Review program health through decision speed, valid learning, repeatability, and detected harm rather than the number of tests launched.
Create a community of practice alongside these controls. Regularly examine inconclusive results, failed replications, instrumentation incidents, and stopped rollouts. These cases expose weaknesses in the system more reliably than a gallery of wins. The goal is not to eliminate failure. It is to make failure informative, contained, and cheap.
Key takeaways
Start with the decision the experiment must support, then pre-register the hypothesis, primary metric, guardrails, detectable effect, and stopping rule.
Use offline evaluations, replay, shadow mode, and canaries to eliminate weak or unsafe candidates before consuming production traffic.
Treat event semantics, assignment, exposure, lineage, and anomaly detection as production infrastructure.
Pair controlled measurement with feature flags, progressive exposure, explicit rollback authority, and persistent holdouts where cumulative effects matter.
Judge the program by trustworthy decisions and reusable learning, not experiment volume or the percentage of positive results.
Choose one upcoming decision with meaningful customer or operational risk. Write its decision contract, identify the cheapest evidence layer that could disprove it, and verify the rollback path before anyone builds the treatment. That single discipline is a practical starting point for a program that can keep learning as your product and organization change.