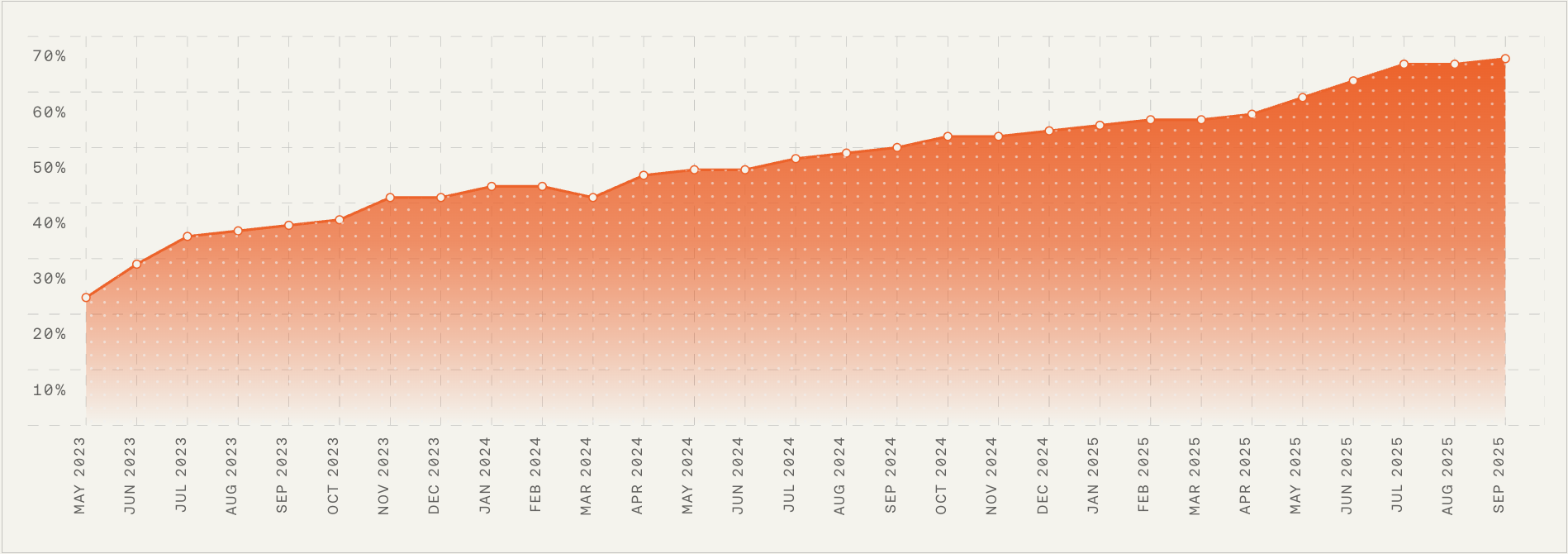
Your team has several credible AI demos, every sponsor sees potential, and no one can answer the question that matters: which idea deserves more engineering time, customer exposure, and operating risk?
That is not an ideation problem. It is an evidence-design problem. A useful AI innovation strategy makes each investment earn its way forward through customer outcomes, representative evaluations, and explicit kill-or-scale decisions. The result is not less experimentation. It is faster learning with fewer expensive surprises.
Start every AI bet with a decision contract
Most AI roadmaps begin too far downstream. The discussion jumps to a model, an assistant, or an agent before the team agrees on the user problem or the evidence required to fund the next stage. The feature then acquires momentum simply because it exists.
Replace the feature brief with a decision contract. This is a short agreement about what the bet must prove, how it will be evaluated, and what happens when the evidence arrives. It connects vision, portfolio choices, and execution to measurable outcomes before implementation choices harden.
- Name the user and the job. Specify who encounters the capability, what they are trying to accomplish, and which situations are out of scope. “Improve support with AI” is not a problem statement. “Help eligible customers resolve account questions without waiting for an agent” is testable.
- Choose the business outcome and its baseline. Use resolution rate, time-to-value, activation, retention, revenue lift, or another measure of customer and business value. Record how the existing workflow performs so the AI is compared with a real alternative, not with an empty screen.
- State the behavioral hypothesis. Explain how the proposed capability should cause the outcome to move. This exposes weak logic early. A faster response, for example, does not automatically produce a correct resolution.
- Define the evidence stack. Identify the offline evaluations needed to establish behavioral confidence and the live experiment needed to validate customer impact. Neither can substitute for the other.
- Set constraints and hard guardrails. Include unacceptable failures, privacy boundaries, safe-action requirements, latency expectations, and cost limits. A capability that is accurate but too slow, unsafe, or uneconomic is not ready.
- Pre-commit to the decision. Record the minimum detectable effect for the live experiment, the evaluation thresholds that block release, the time at which evidence will be reviewed, and the conditions for killing, refining, or scaling the bet.
The contract should separate three metric layers. The outcome metric tells you whether customer or business value changed. Behavioral metrics tell you whether the AI performed its assigned job. Guardrails tell you whether that performance remained safe, reliable, responsive, and affordable. This prevents a team from celebrating a model score while the customer experience deteriorates.
Consider a customer-support assistant. Eligible deflection and first-contact resolution can represent the business outcome. Factuality against the approved knowledge base, helpfulness, tone, retrieval accuracy, and safe CRM actions describe the system’s behavior. Harmful-content rate, unsafe-action rate, response latency, and token cost act as guardrails. A live test can then examine customer satisfaction and resolution instead of merely counting generated replies.
This is the practical difference between an output and an outcome. Shipping an assistant is an output. Producing more successful resolutions without unacceptable safety, latency, or cost regressions is an outcome. Disciplined evaluation makes that distinction measurable.
Match the evidence burden to the type and consequence of the bet
A portfolio needs different kinds of AI innovation, but it should not evaluate every bet in the same way. Core optimization, adjacent expansion, and transformational innovation face different uncertainties. The label determines the strategic question. The consequence of failure determines the rigor.
| Portfolio bet | Question it must answer | Evidence that matters most | Typical decision |
|---|---|---|---|
| Core optimization | Can AI improve an established journey without damaging what already works? | A reliable baseline, regression tests, live A/B results, and cost and latency guardrails | Adopt the change only when the improvement survives the existing quality bar |
| Adjacent expansion | Does the capability solve a known job for a new segment, channel, or use case? | Problem discovery, segment-representative evaluation cases, activation signals, and retention evidence | Expand only after the new audience reaches a meaningful value moment |
| Transformational innovation | Can a materially different workflow create value and be trusted? | Task-completion tests, human review, adversarial testing, safe tool-use checks, and a staged customer pilot | Increase autonomy and exposure only as reliability and business evidence mature |
A core change can have a small strategic scope and still require a high evidence burden. An apparently simple classifier may sit inside a sensitive workflow. Conversely, a transformational concept can begin with a narrow, reversible prototype. Do not use “experimental” as permission to lower the bar for privacy, security, or consequential actions.
The same discipline improves build, partner, and buy decisions. Generic demonstrations do not reveal how a system will perform on your customers’ language, your knowledge, your policies, or your tools. Run every viable option through the same representative task set. Compare task quality, latency, cost, integration effort, data boundaries, governance fit, and failure recovery. The vendor category matters less than whether the option can satisfy the decision contract.
Portfolio funding should follow evidence maturity rather than presentation quality. Continue a bet when the team can identify remaining uncertainty and run a proportionate test to reduce it. Pause or kill it when customer value does not materialize, critical failure modes remain unresolved, or the required quality cannot fit inside the operating cost and latency envelope.
A neutral experiment is not automatically wasted work. It can eliminate a weak hypothesis and release capacity for a better bet. But a poorly instrumented or under-sensitive experiment does not produce a useful neutral result. Set the minimum detectable effect and instrumentation before launch so “no movement” has an interpretable meaning.
Build an evaluation stack that resembles the real product
An AI evaluation is useful only when it represents the decisions the product must make under realistic conditions. A polished answer to a convenient prompt is weak evidence. The production system also has to handle ambiguous requests, imperfect retrieval, policy boundaries, long-tail inputs, adversarial behavior, and tool failures.
Turn the golden dataset into an executable product specification
Your golden dataset should express product intent through examples. Start with real, properly anonymized inputs from discovery, support, and product usage. Add important edge cases, long-tail situations, and adversarial prompts deliberately; waiting for production to reveal them transfers avoidable risk to customers.
Each case should carry enough context to diagnose a failure, not just assign a score:
- The user input and relevant conversation or workflow state
- The approved information or system state the response may rely on
- The expected behavior, acceptable answer range, or permitted action
- A rubric for correctness, helpfulness, tone, and safety
- A risk label that distinguishes ordinary quality defects from release-blocking failures
- Metadata for the user segment, use case, input pattern, or workflow stage
Keep the set versioned. Preserve cases that caught previous regressions, refresh it as customer behavior changes, and hold back examples that are not used for prompt tuning. Otherwise, the team can optimize for a familiar test set while making little progress on the wider product experience.
Privacy belongs in dataset design. Anonymization, access control, retention rules, and approved data boundaries should be established before customer interactions become test fixtures. Retrofitting those controls after an evaluation pipeline spreads sensitive data is slower and riskier.
Use several evaluators because each catches a different failure
No single evaluation method is a complete quality system. Layer methods according to what is being tested:
- Deterministic tests are appropriate for business rules, schemas, required fields, forbidden actions, exact calculations, and tool arguments. If a rule can be checked directly, do not ask another model to guess whether it passed.
- Grounded checks compare claims with an approved knowledge base or retrieved context. They are essential when the product promises answers based on company or account information.
- LLM-as-judge scoring can cover subjective dimensions such as helpfulness, relevance, and tone at useful scale. Define the rubric tightly and calibrate the judge against human decisions. Consistency is not enough if the judge consistently applies the wrong standard.
- Pairwise preference tests help compare prompt, retrieval, or model variants when an absolute score is hard to interpret. They answer which candidate better satisfies the same rubric.
- Human review remains necessary for critical, ambiguous, policy-sensitive, or high-consequence cases. It also provides the reference needed to recalibrate automated judges.
- Red teaming probes manipulation, unsafe requests, policy evasion, and unexpected combinations of otherwise valid instructions.
Agentic systems need evaluation beyond the final prose. A fluent confirmation can hide a failed or unauthorized action. Measure whether the agent chose the correct tool, supplied valid arguments, respected permissions and confirmation requirements, completed the intended task, and recovered safely when a dependency failed. Task-completion reliability and safe-action rate are more revealing than answer style alone.
Quality must also be evaluated inside the cost-quality-latency envelope. A larger model can improve a difficult generation task and still be the wrong default for a simple classification step. Test model routing, token budgets, caching, prompt structure, retrieval quality, and function-calling patterns by task. The goal is not to minimize each cost independently; it is to meet the product’s quality bar with an operating profile the business can sustain.
Turn evaluations into release gates and portfolio decisions
An evaluation document that lives outside delivery will eventually be skipped. The evaluation suite should run whenever a prompt, model, retrieval pipeline, knowledge source, tool schema, or workflow changes. That makes evaluation part of the release mechanism instead of a launch ceremony.
Use a gate sequence from discovery through production
| Stage | Evidence to collect | Decision enabled |
|---|---|---|
| Problem discovery | User problem, current workflow, baseline, value hypothesis, and major risks | Decide whether the problem deserves an AI bet |
| Prototype | Representative golden-set results, failure taxonomy, latency, and estimated operating cost | Decide whether the capability has a credible path to the product bar |
| Pre-release | Regression suite, calibrated human review, adversarial cases, privacy checks, and safe-action tests | Block, revise, or approve a controlled rollout |
| Controlled rollout | Predefined A/B test, value-moment telemetry, satisfaction, guardrails, and incident signals | Validate whether offline quality creates customer and business value |
| Production scale | Continuous monitoring, segment-level failures, cost and latency trends, incidents, and refreshed evaluations | Scale, route, constrain, roll back, or retire the capability |
Separate hard gates from optimization targets. A prohibited action, a privacy-boundary violation, or a broken business rule should block release. A modest tone improvement or non-critical cost regression may be handled as a tracked trade-off. If every metric is a hard gate, delivery stalls. If none is, the gate is theater.
I use a simple test for gate quality: if two accountable leaders can read the same result and reach opposite release decisions, the decision rule is incomplete. Define the failing threshold, affected cases, permitted exception process, and rollback action before the result arrives.
For systems that can change customer data, communicate externally, or trigger another consequential action, start with narrow permissions and human confirmation. Log the proposed action, the tool call, the result, and the reason for escalation. Increase autonomy only when the relevant task and safety evaluations hold under real usage. A human-in-the-loop control is most useful when the escalation path, response owner, and incident procedure are explicit.
Offline evaluations create confidence to expose the product. They do not prove business impact. A live experiment must test the stated outcome with a predefined minimum detectable effect while watching for novelty bias and segment-specific failures. Instrument the customer’s value moment, not merely clicks on the AI entry point. An assistant can attract curiosity without improving activation, retention, resolution, or satisfaction.
Production telemetry should feed back into the golden dataset. Add recurring failures, newly observed edge cases, incidents, and examples where users abandon or escalate. This turns customer reality into the next regression suite and prevents evaluation from freezing at the assumptions held before launch.
Carry one scorecard from the product team to the QBR
Leadership does not need a separate innovation narrative built from feature updates. Use one scorecard at product reviews, investment reviews, and QBRs. It should contain:
- The portfolio class and strategic outcome
- The target user, job, and current baseline
- The causal hypothesis and non-AI alternative
- The primary business metric and minimum detectable effect
- The offline quality measures and live outcome measures
- The safety, privacy, latency, reliability, and cost guardrails
- The current evidence, unresolved uncertainty, and confidence level
- The next test, accountable owner, review point, and kill-or-scale rule
This creates a common language for product, engineering, design, go-to-market, risk, and executive stakeholders. The conversation becomes: What did the bet need to prove? What evidence changed? Which uncertainty remains? What decision follows? It no longer depends on who presents the most persuasive demonstration.
The scorecard also protects speed. Teams with explicit boundaries can make routine prompt, retrieval, routing, and interface improvements without reopening the entire strategy. Leadership attention can stay on exceptions, material regressions, capital allocation, and bets whose evidence no longer supports the original thesis.
Key takeaways for your next AI portfolio review
- Require a decision contract before an AI idea receives roadmap momentum: user, outcome, hypothesis, evidence, guardrails, and kill-or-scale rule.
- Classify each bet as core, adjacent, or transformational, but set evaluation rigor according to the consequence of failure.
- Build a versioned golden dataset from anonymized real inputs, important edge cases, long-tail situations, and adversarial prompts.
- Layer deterministic checks, grounded tests, calibrated model judging, human review, preference testing, and red teaming.
- Evaluate agent actions and task completion, not only the fluency of the final response.
- Run relevant regressions whenever prompts, models, retrieval, knowledge, tools, or workflows change.
- Use offline evaluation to control release risk and live experimentation to validate customer and business impact.
- Fund, refine, pause, or kill bets based on evidence maturity rather than demo quality or sunk effort.
At your next roadmap review, pick one upcoming AI bet and pause the implementation discussion until its decision contract is complete. Then run the current workflow through a representative evaluation set before changing it. That baseline gives every later improvement something honest to beat.
When each investment has a visible path from user problem to evaluation to decision, AI innovation stops being a contest between plausible demos. It becomes a repeatable way to allocate attention, manage risk, and scale the capabilities that produce durable value.