Model Context Protocol adoption becomes consequential when an agent can retrieve organizational knowledge, select tools, and change a system of record. At that point, the engineering challenge is no longer simply connecting a model to an API. It is operating a product platform whose context, permissions, decisions, and side effects must remain dependable.
The source article’s experience with workflows spanning Miro, Jira, and Confluence points to a coherent platform model: retrieval determines what the agent knows, tool contracts constrain what it can do, evaluation tests its behavior, and observability makes failures diagnosable. Product strategy and interaction design then determine whether that machinery improves work users already perform.
Key takeaways
- Treat retrieval, tool schemas, prompts, policies, and telemetry as platform components with explicit owners and versioning.
- Prove one frequent, measurable workflow before expanding the agent’s tool and use-case surface.
- Combine least-privilege access with visible tool rationale, consent controls, audit records, and safe recovery paths.
- Evaluate the complete chain from retrieved context to downstream action, not just the quality of generated text.
- Govern the tool catalog and delivery pipeline continuously so that extensibility does not become uncontrolled operational risk.
The platform boundary extends beyond the MCP connection
MCP provides a practical interface through which models can reach data, tools, and actions, according to the source article. The protocol connection is therefore an enabling layer, not the whole agent platform. A production workflow also depends on source authority, identity and permission checks, context selection, tool arbitration, execution controls, user-facing recovery states, and evidence that the result was useful.
This broader boundary changes how teams should decompose the system. Retrieval is a managed context service rather than an incidental prompt-building step. Tools are governed capabilities rather than a loose collection of endpoints. Prompts and policies are deployable artifacts rather than text copied into application code. Traces and evaluations are part of the control plane because they reveal whether the other layers continue to work together.
The source recommends starting with authoritative content, normalizing it with docs-as-code discipline, attaching metadata that supports permission-aware filtering, and selecting the smallest high-signal context needed for a task. The engineering implication is important: access control must shape retrieval before information reaches the model. Filtering only when an action is attempted would leave the reasoning process exposed to context the user or agent may not be entitled to use.
Context quality also affects more than answer accuracy. The source links focused retrieval to lower hallucination risk, more accurate tool calls, and lower cost. That makes retrieval performance a shared dependency for safety, reliability, latency, and economics. It deserves its own contracts, tests, freshness expectations, and failure modes.
A golden path turns architecture into an operating contract
The source describes an initial workflow that summarized a Miro board into action items and wrote them to Jira. It reports that variants involving Confluence summaries, epic splitting, and backlog grooming followed only after the original path reached its reliability targets. This is less a recommendation for those particular products than a useful sequencing principle for agent platform engineering.
A narrowly defined workflow exposes the entire contract between context and consequence. The team must decide which content is authoritative, what the model may infer, which tool is appropriate, what inputs the tool accepts, what the user should review, how a partial failure is handled, and how success is measured. A broad assistant can conceal these questions behind plausible conversation; a golden path forces explicit answers.
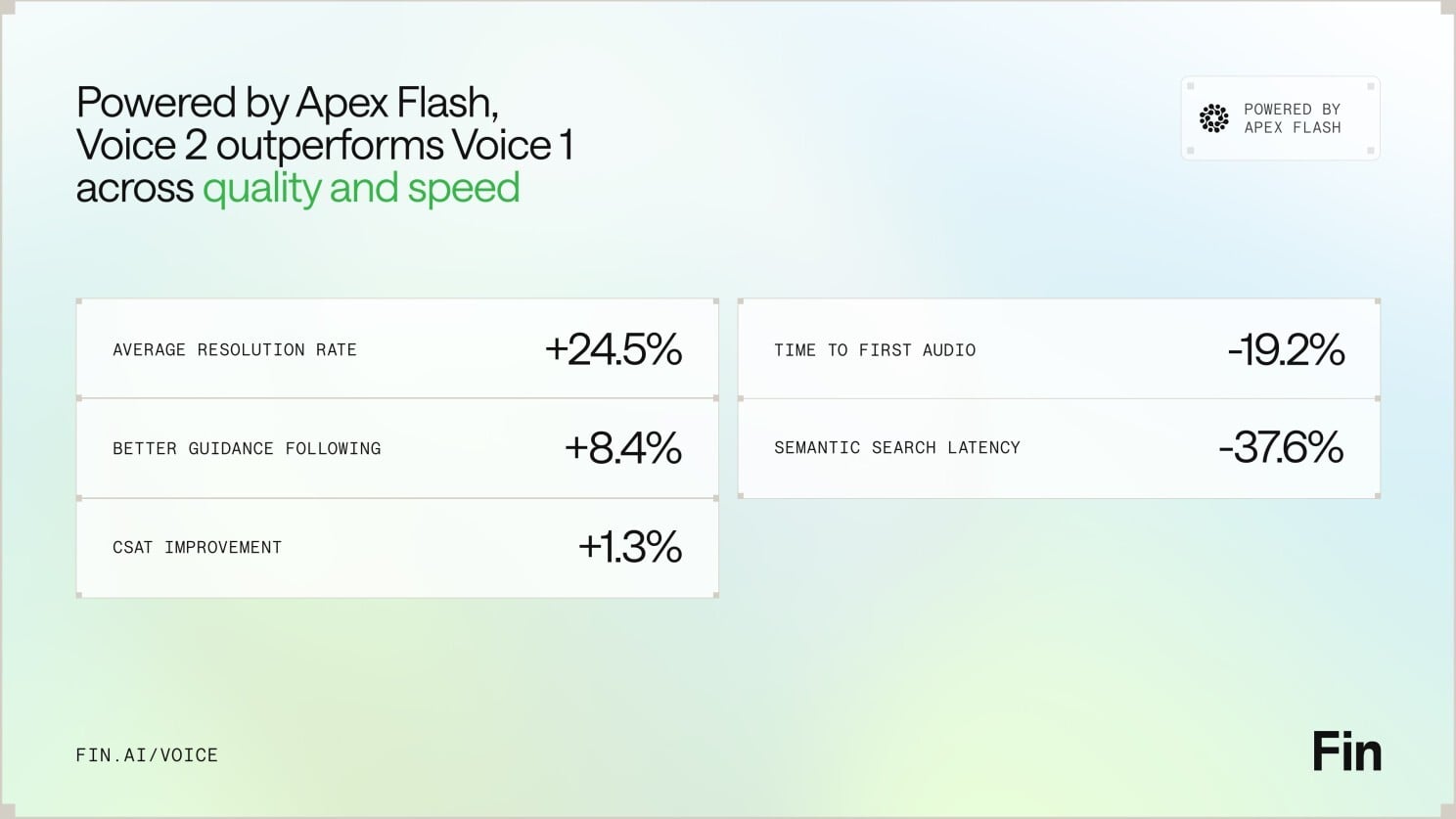
The right first workflow is therefore not merely technically convenient. It should be frequent enough to matter, have an observable completion state, and carry side effects that can be bounded. The source frames outcomes such as time saved during backlog grooming, better meeting notes in Confluence, and fewer context switches across Miro boards as more useful roadmap anchors than novel model capabilities. It also recommends comparing task success, completion time, user edits, detected defects, and downstream business effects rather than relying on engagement alone.
Those measures form a practical evidence chain. Evaluation results show whether the system behaves as designed; workflow measures show whether users can complete the task; business measures show whether the completed task creates value. Keeping the levels distinct prevents a technically impressive agent from being mistaken for a successful product.
Safety depends on controlling actions and explaining them
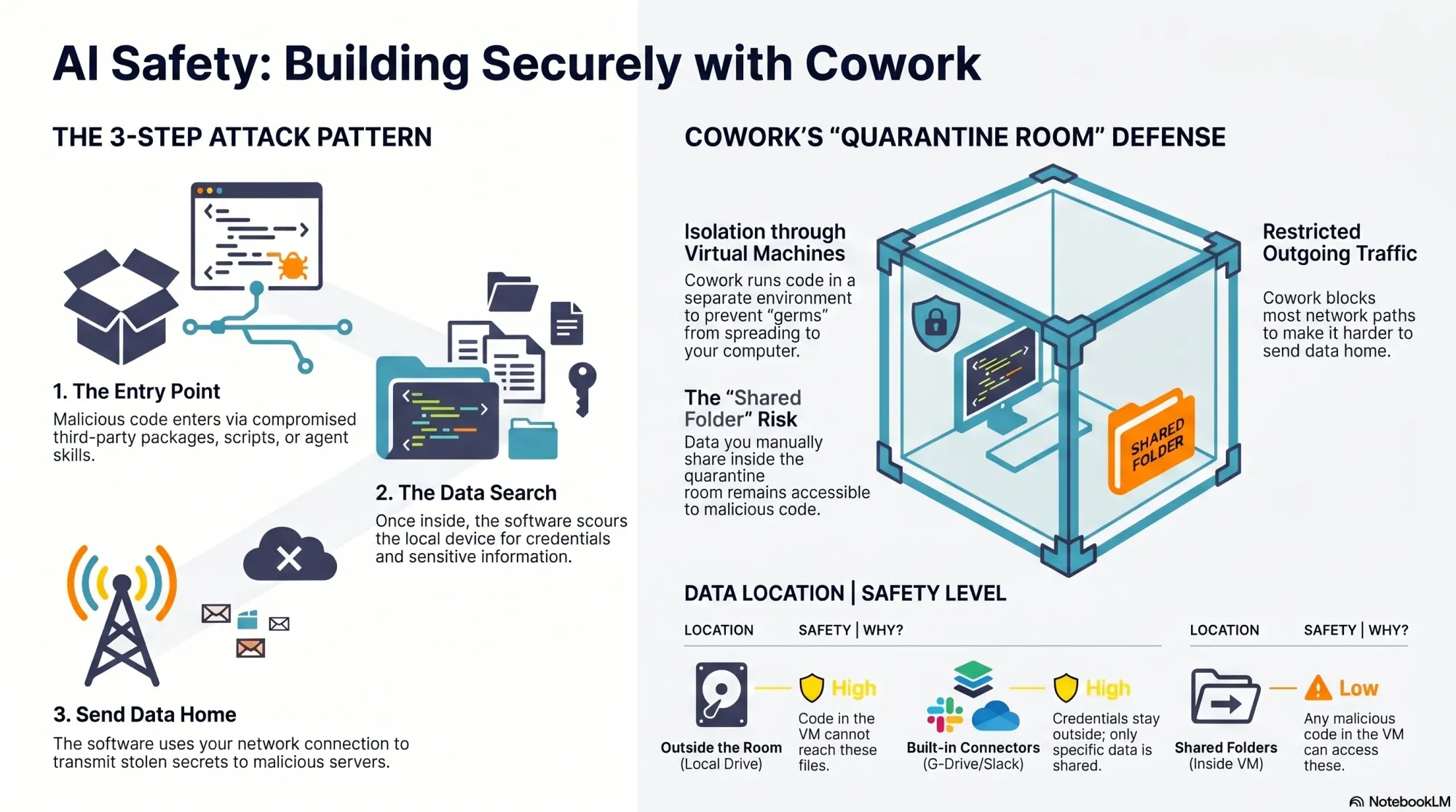
Tool access creates a sharper risk boundary than text generation because an incorrect decision can alter a ticket, document, or other shared record. The source’s proposed response combines least-privilege scopes, a human-readable rationale for each call, and an audit trail. It also calls for proposed inputs and expected side effects to be visible when the agent is about to use a tool.
These controls address different failure classes. Narrow scopes limit the maximum effect of a bad decision. Input previews help users catch incorrect parameters before execution. Rationale makes the selection inspectable. Audit records support diagnosis and accountability afterward. None substitutes for the others, and a confirmation dialog alone does not make an overprivileged tool safe.
Recovery behavior belongs in the same design. The source recommends retrying suitable failures with backoff, falling back to read-only behavior, or requesting consent or missing context. A robust platform should distinguish failures that are safe to retry from failures that require a different plan. It should also preserve an understandable state when a multi-step workflow completes only partially, so the user knows what changed and what did not.
Transparency need not mean exposing raw internal reasoning. The useful product surface is operational evidence: the sources used, the selected capability, the intended inputs, the expected effect, and the resulting status. The source suggests a reveal panel containing retrieved sources, candidate tools, and confidence signals for power users. More generally, the amount of review should follow the consequence of the action: low-risk retrieval can remain lightweight, while consequential writes warrant clearer inspection and consent.
Evaluation, observability, and delivery form one reliability loop
The source outlines offline tests for intent classification and tool selection, online shadow evaluations for live drift, and regression checks after deployment. It also recommends traces that capture prompts, retrieved chunks, tool inputs, tool outputs, latency, and error codes. Together, these practices connect a visible failure to the component and version that produced it.
Evaluation without observability can show that quality declined without explaining why. Observability without evaluation can produce detailed traces without deciding whether the behavior was acceptable. A mature loop needs both: test cases encode desired behavior, traces expose actual behavior, and production outcomes reveal gaps in the test set.
The delivery process must preserve that connection. The source treats prompts, tool schemas, and guardrails as versioned artifacts deployed behind feature flags, with canary releases, controlled comparisons, and rollback capability. This approach makes a behavioral change attributable. If tool selection deteriorates after a prompt revision or a schema update breaks an integration, operators can identify the change and contain its reach.
Latency should be governed in the same loop because an accurate workflow can still fail as a product experience. The source reports using task-specific latency budgets, caching stable retrieval results, parallelizing safe calls, prefetching likely session context, and providing progress when work exceeds the expected budget. These techniques should remain subordinate to correctness: parallel execution is appropriate only when calls are independent, while caching must respect freshness and permission boundaries.
The source also assigns prompts a user-experience role, combining plain-language intent, domain constraints, and explicit tool contracts while using examples, tooltips, and in-product guidance to help users frame requests. This connects conversation design to reliability. Better instructions can reduce ambiguity before the platform has to resolve it through additional model turns or risky assumptions.
Scale requires governance of tools, teams, and ownership
MCP’s extensibility can turn into tool sprawl if every integration is added without lifecycle management. The source recommends a curated catalog recording each tool’s owner, scope, schema version, and deprecation policy. It also describes schema linting in continuous integration, backward-compatible changes, and quarterly retirement of unused tools. These are conventional platform disciplines applied to an agent’s capability surface.
A catalog is valuable because an agent reasons over descriptions and schemas while operators depend on stable implementation contracts. Poorly differentiated tools can make selection ambiguous; unannounced schema changes can invalidate prompts and evaluations; ownerless tools can remain available after their data or permission assumptions have changed. Governance should therefore assess semantic clarity as well as API validity.
Organizational design matters for the same reason. The source describes an empowered trio consisting of a product manager responsible for outcomes and risk posture, a forward-deployed engineer focused on schemas and scalability, and a designer responsible for conversational flows and recovery states. It also favors weekly evaluation reviews over demonstration-led progress. The underlying principle is shared ownership: platform reliability cannot be delegated entirely to model engineering when the decisive questions span product value, system behavior, permissions, and user comprehension.
The source’s proposed 30-day starter sequence moves from selecting one workflow and defining permissions, measures, and evaluations; through retrieval and a minimal tool set; to an instrumented internal pilot; and finally to hardening and a limited beta. The schedule is reported as a blueprint rather than independent proof of how long every implementation should take. Its more transferable lesson is dependency order: define the outcome and risk boundary before multiplying capabilities.
As agents begin coordinating across products, the durable advantage will come from platforms that preserve this discipline across every new connection. MCP can make capabilities composable, but dependable composition will still depend on controlled context, explicit authority, observable execution, and evidence that the workflow improves real work.
References