I’ve watched the rise of product engineering up close, and it’s reshaping how we build software. The old model of rigid handoffs and separate functions is giving way to small, empowered product teams where engineers own the customer problem end to end. That shift isn’t just cultural—it’s a performance advantage that compounds with every release.
I often summarize it this way: “Product engineers are taking over. They ship code, talk to users, and own outcomes—no handoff required. Here’s what the role is, and why it matters now.”
When I say “product engineer,” I’m describing a builder who goes beyond writing code. I expect them to partner in product trios with product management and design, participate in continuous discovery, and make decisions grounded in product strategy and real customer insight. They don’t toss features over a wall; they own the problem, the solution, and the measurable outcome.
Why now? Modern delivery practices like CI/CD and feature flags compress feedback loops, while behavioral analytics and session replay make customer friction visible in real time. As expectations rise for quick iterations and clear value, teams that reduce handoffs and align around outcomes outperform on DORA metrics such as deployment frequency and lead time for changes.
Day to day, a strong product engineer blends discovery and delivery. They join customer interviews, review support tickets, analyze usage patterns, and run A/B testing to validate hypotheses. Then they ship code in small, safe increments, instrument telemetry, and watch adoption and retention signals to confirm they’re moving the numbers that matter.
Team shape matters. I favor compact, cross-functional squads anchored by product trios, each with explicit outcomes vs output OKRs. Product engineers often operate like forward deployed engineers, partnering with customer success and solutions engineering to learn at the edge of real-world usage. This proximity to customers turns ambiguity into insight—and insight into product leverage.
Accountability is concrete. We track DORA metrics for delivery health and pair them with product outcomes such as activation, time-to-value, and Net Recurring Revenue (NRR) drivers. The combination keeps us honest about both how fast we move and whether what we ship truly works for customers.
The hiring profile is distinct. I look for engineers who are curious about the “why,” comfortable with trade-offs, and energized by customer conversations. They can navigate architectural complexity, but they also translate user feedback into crisp product bets. Many grow into natural facilitators of discovery rituals and developer evangelism across the organization.
If you’re getting started, pilot a single squad. Establish clear outcomes vs output OKRs, invest in CI/CD and feature flags, and commit to continuous discovery with weekly customer interviews. Give the team ownership of a KPI tied to product strategy, and measure progress with DORA metrics plus usage and retention signals. The early wins—fewer handoffs, faster learning, tighter feedback loops—build momentum quickly.
In short, product engineers thrive where accountability, autonomy, and user empathy meet. They reduce wasteful coordination, shorten the path from insight to impact, and ensure we ship code that customers actually adopt. That’s why this role is reshaping how software gets built—and why the teams that embrace it will set the pace for everyone else.
Old-school, in-person selling is having a renaissance in the AI era, and I’ve seen why up close. From leading product and go-to-market teams through hypergrowth, I keep returning to one lesson: enterprise buyers still reward the teams who show up, orchestrate change management, and own outcomes end-to-end. The tech has changed; the human dynamics haven’t.
Has the sales playbook changed in the AI era? The tools are faster and the surface area is bigger, but the core motion remains the same: “showing up” beats letting the marketplace decide. That’s why in-person enterprise rollouts still beat product-led motions, especially when the stakes include security, governance, and cross-functional adoption. You win by reducing organizational risk, not by assuming free trials will do the heavy lifting.
Great enterprise sellers collapse silos. They sell to engineers and executives in one motion, pairing deeply technical validation with crisp business narratives. In my org, that means every high-velocity pilot has a dual thread: hands-on, eval-driven proof for the builders and a value architecture for the budget owners. When those motions run in parallel, time-to-value plummets and procurement friction fades.
Selling to AI-native buyers who grew up on ChatGPT changes tempo, not fundamentals. The same seller, different tempo: 8 weeks vs. 8 business days. These buyers evaluate fast, expect clear ROI, and push for automation-first workflows. How AI-native buyers handle build vs. buy decisions comes down to build for differentiation and buy for acceleration. If you make procurement feel like product—frictionless, instrumented, and transparent—you’ll meet their bar.
Process matters, but humanity wins. Building a robust sales process that still leaves room for unscripted moments is where trust is formed. I’ll never forget the story of the rep who taught a champion’s son guitar over Zoom—an unscripted moment that cemented a partnership. The lesson: raise the floor without capping the ceiling. Equip every rep with repeatable plays, then celebrate the creative instincts that make champions out of customers.
In early GTM, why the three highest-leverage early sales hires aren’t sellers at all resonates with my experience. I prioritize a solutions engineer who can de-risk integration, a forward-deployed operator who can run the first rollout like a product manager, and a customer success lead who designs adoption paths from day zero. Together, they compress the value journey from proof to production.
Compensation design shapes your talent market. The case for outsized commission accelerators for star sellers — and the kind of person they attract is real: magnets for competitors who close complex, multi-threaded deals and thrive with ownership. But beware: why too much process narrows the kind of seller you attract. Over-script it and you filter out the very people who can navigate ambiguity with customers.
Under the hood, instrumenting the funnel from stage zero to close keeps the system honest. I track intent signals before pipeline, conversion by persona and use case, proof milestones, and time-to-value in production. The three pillars of GTM excellence for me are repeatable discovery, referenceable outcomes, and relentless enablement. And inside the leadership team, building peers who are 80% aligned, not 100% preserves healthy tension while keeping execution fast.
AI is expanding the definition of enablement—whether AI is changing what good enablement looks like isn’t a theoretical question anymore. I see world-class teams arming reps with retrieval-first knowledge bases, sandbox environments, and objection libraries that evolve weekly. Meanwhile, selling against direct and implied competitors at once is the norm: your battlecard must cover “do nothing,” internal tools, adjacent categories, and new AI entrants—while you still remember why in-person enterprise rollouts still beat product-led motions for durable adoption.
Planning horizons tighten in AI markets. How far out should a GTM leader be planning? I work a dual cadence: a rolling 6-week operating plan that’s ruthlessly tactical and a 2–3 quarter roadmap for coverage, enablement, and category storytelling. What a normal week looks like in hypergrowth blends customer time, pipeline triage, onboarding and enablement, deal engineering, and process tuning—always with one or two high-conviction bets that could bend the curve.
If you’re scaling an AI product today, pair a disciplined sales-led growth engine with the best of product-led growth: fast paths to proof, hands-on validation for builders, executive-level value mapping, and human moments that turn customers into advocates. That’s how you compress an eight-week cycle into five business days—and keep the expansion flywheel spinning.
I’ve learned that customers don’t just buy features—they buy the way we discover, decide, build, ship, and support. In other words, the operating model is the product. That realization has shaped how my team and I at HighLevel translate product strategy into tangible, repeatable outcomes that show up in quality, reliability, onboarding, and consultative support every single day.
We created Product Partners to codify that operating model and scale it with discipline. It’s a blueprint and operating rhythm that unifies product strategy with go-to-market strategy, customer success, and solutions engineering—so empowered product teams can move faster without sacrificing clarity, governance, or customer trust.
First, we anchored on continuous discovery. Product trios work shoulder-to-shoulder with customer-facing teams to run customer interviews, journey mapping, and A/B testing, then validate insights with session replay and behavioral analytics. We use driver trees and opportunity solution trees to connect problems to outcomes, ensuring prioritization is evidence-based and aligned to product-market fit—not just output.
Second, we elevated delivery excellence. Our practices emphasize CI/CD, feature flags, observability, SRE-informed incident management, and DORA metrics to shorten feedback loops while raising the bar on stability. Privacy-by-design, data governance, and regulatory compliance are built into our workflows, and we make deliberate build vs buy decisions to protect platform scalability and long-term velocity.
Third, we integrated go-to-market alignment from day one. Solutions engineering and customer success shape requirements early, so launches include in-app guides, product tours, onboarding paths, and consultative support that accelerate user activation. We tie outcomes vs output OKRs to stakeholder management rituals, ensuring sales-led and product-led growth motions reinforce each other instead of competing for focus.
Finally, we closed the loop with a unified analytics platform. Activation, retention analysis, and Net Recurring Revenue (NRR) sit alongside qualitative signals from customer interviews and support. This single source of truth helps us refine product positioning, sharpen value propositions, and improve roadmapping and sprint planning with clear, testable hypotheses.
What does this mean for our partners and customers? Faster time-to-value, fewer handoffs, clearer expectations, and a shared lens on the metrics that matter. Product Partners isn’t a side program; it’s how we operationalize trust—through transparency, consistent rituals, and a bias toward learning that compounds.
If this resonates, you’ll feel it in how we discover, build, and support together. I’ll continue to share our playbooks—covering continuous discovery, onboarding, and outcome-based planning—so we can keep raising the standard for product management leadership and product-led growth, one operating rhythm at a time.
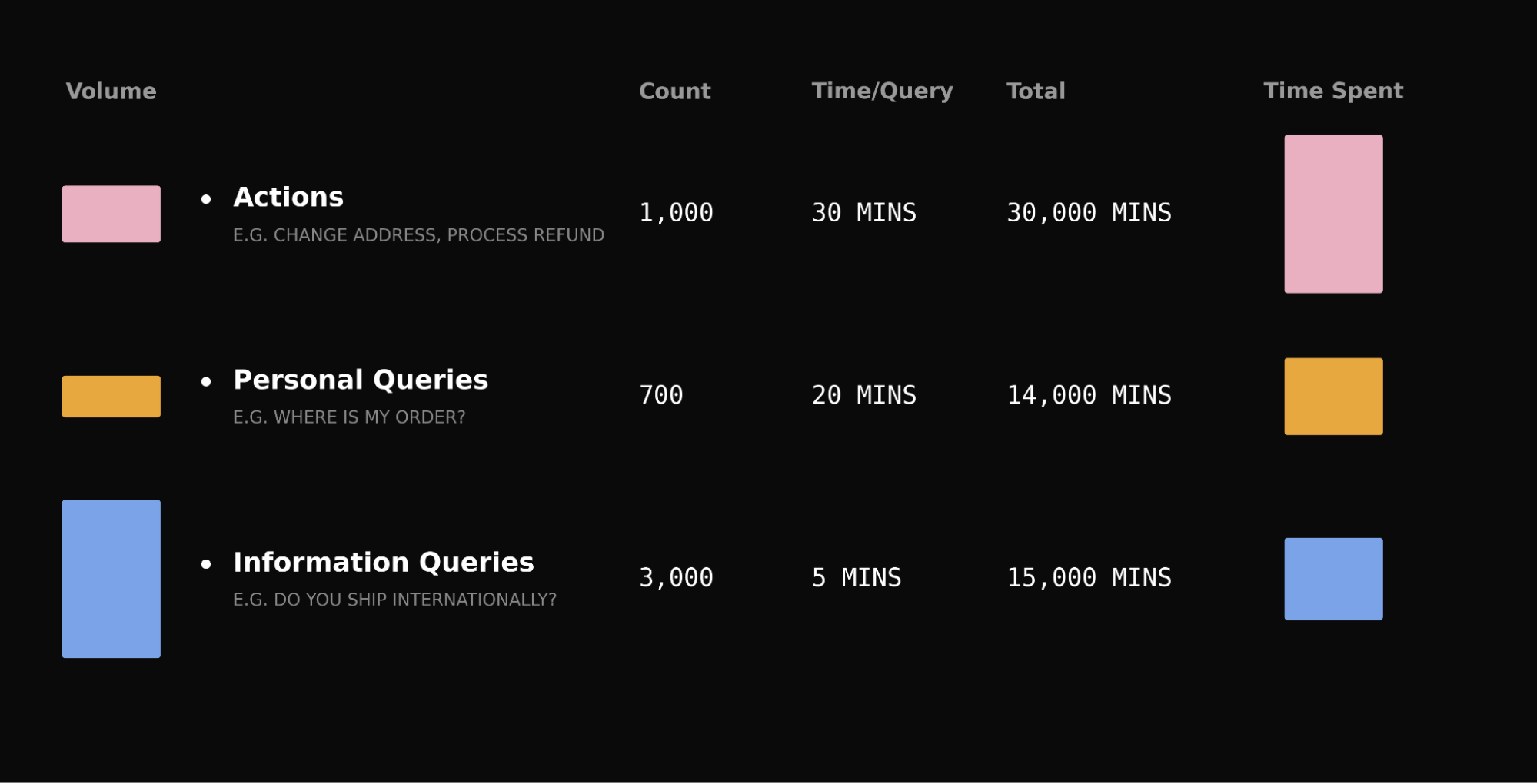
I’ve learned that the smallest slice of your support queue often dictates the majority of your operating cost, customer memory, and automation ceiling. In product reviews and CX ops deep-dives, I see the same pattern: the “easy” tickets pad your resolution counts, but the complex, multi-step queries quietly own your handle time and your brand trust. If you care about compounding impact, your customer support AI strategy has to target that hardest percentage first.
Complex queries are a small percentage of your queue, but they consume a disproportionate share of your team’s time.
Take a typical queue: password resets outnumber refund disputes ten to one, but a reset takes five minutes and a dispute takes thirty. The “rare” query accounts for over a third of total handling time. The same pattern holds for account investigations, subscription changes, and billing disputes.
How you handle complex queries is also what customers actually remember about their support experience. When someone is dealing with a damaged order or a billing dispute, the stakes are higher, and a fast, good resolution is what separates a forgettable interaction from one that builds lasting trust.
Most AI Agents automate the easy, informational queries well. The question for your automation rate is whether they can handle the hard ones. That’s where agentic AI and robust AI workflows make or break your outcomes.
We’ve gotten really good at informational queries – the hard part is what comes next. I’ve seen teams invest deeply here, and for good reason: it lifts containment quickly and cheaply. But to break through the plateau, you have to execute actions across systems, not just answer with text.
We’ve invested deeply in informational Q&A. We built Apex, a specialized customer service model trained on billions of support interactions, as Fin’s core answering engine. Beneath that sits a custom retrieval model, a purpose-built reranker, and a unified RAG pipeline, all trained specifically for customer service. Fin resolves issues at a higher rate than general-purpose frontier models, with fewer hallucinations and at lower cost.
But informational Q&A only covers queries where text is the answer. Most Agents can handle that. Far fewer let you configure complex, multi-step actions without a forward-deployed engineer setting it up for you, which creates a gap.
Every query your team handles falls into one of three categories:
Informational: “Can you ship transatlantic by priority next day?” Answered with text from your knowledge base.
Personalized: “Where is my order?” Requires data unique to that user.
Action-led: “My order arrived damaged, I need a refund.” Requires doing something: checking a return window, cross-referencing transaction data, making a judgment call – reading from multiple systems and acting across them.
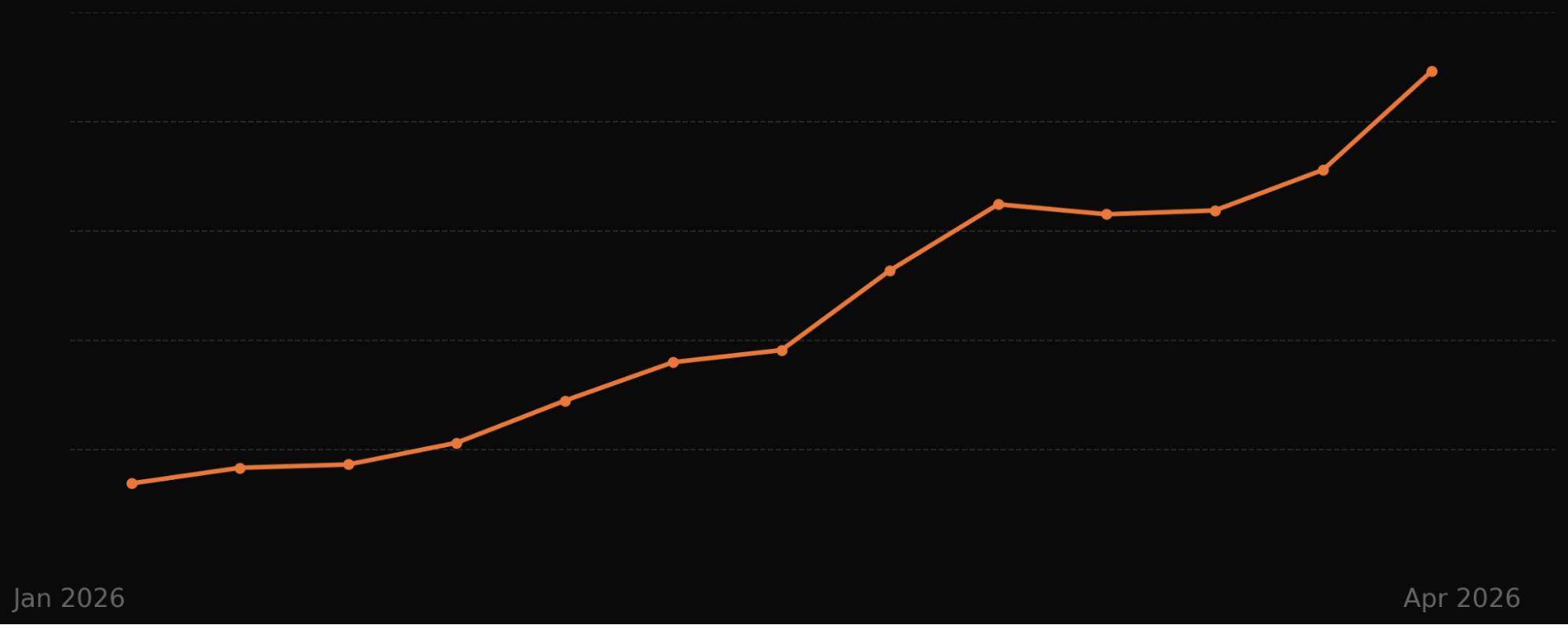
From Jan to Apr 2026, the trend moves steadily upward, pausing briefly before a sharp late surge. A clear snapshot of momentum for customer service KPIs, finance results, and the impact of new procedures.
These complex queries, the ones that require multi-step processes across systems, aren’t edge cases; they’re the reason your support team exists. This is the gap Fin Procedures was built to close.
It works in practice, and the trajectory matters for product strategy and ops planning.
Procedures is live, it’s scaling, and the results are clear. Since launching in managed availability, Procedures has handled over 1.5 million conversations, and volume is doubling month over month across hundreds of apps in fintech, e-commerce, gaming, healthcare, and SaaS.
When customers hit complex, multi-step queries, the experience is dramatically better when Fin can do the work end-to-end. We tested this with a randomized 5% holdout – conversations where Procedures would normally run, but didn’t. CSAT was 28.93% higher when Procedures ran, a statistically significant result.
A product, not a services engagement. I’ve sat through too many “automation” projects that were really solutions engineering gigs: workshops, custom scripts, then a queue of change requests when policies shift. It’s fragile and slow.
The B2B AI industry has a consultingware problem. It’s not databases being forked anymore, it’s prompts. The economics of maintaining bespoke setups per customer don’t work. Either the application falls behind new models, or the vendor changes the model and quality degrades invisibly.
In my view, an agentic AI platform should be a product your team owns end to end: a natural language editor – literally paste your existing SOPs – branching logic, data connectors, and AI-powered simulations for testing. Your CX ops team configures this, iterates on it, owns it. If you need help, a forward-deployed team can assist, but they’re optional, not a dependency. You always have control.
And because it’s a unified product, improvement compounds. When the vendor optimizes a prompt, every customer’s Procedures get better. When they upgrade the model, they can A/B test across the entire customer base and know it’s better before rolling out. You can’t do that when every customer has a bespoke prompt. The consulting model isn’t just expensive, it’s structurally unable to compound.
Today, Fin Procedures is available to every Intercom customer – no waitlist or managed rollout, ready for all 8,000+ customers.
We’re iterating fast based on real customer feedback. Here’s what’s landed since the last major update, and why it matters for reliability and governance:
AI-powered Procedure review: Flags broken logic, missing references, and unreachable conditions before you deploy.
Kick off your journey with the #1 Agent—an AI partner designed to turn resolutions into real outcomes. Tap “Start a free trial” to explore faster, smarter customer service and see how Fin delivers value from day one.
Procedure failure reporting: A new reporting dimension that lets you drill into conversations where Procedures failed, so you can diagnose and fix.
Version history with rollback: Track every change, compare versions, roll back if needed.
Data connector health monitoring: See at a glance if your integrations are healthy, degraded, or failing.
Optional data connector parameters: Fin only asks customers for information when it’s actually needed, instead of prompting for every field.
Email Simulation support: Test how your Procedures behave across chat and email before going live.
Agent in the Loop (Beta) unlocks the next tranche of automation. Even with Procedures, two things hold teams back from automating their most complex queries: missing integrations and policies that require a human sign-off on sensitive decisions.
“Agent in the Loop” is built for both. Need Fin to check your internal admin tools but haven’t built a data connector yet? Put a human checkpoint at that step. Fin handles the conversation, gathers context, and pauses, surfacing a structured summary for a human agent to verify or act, then resumes. You get automation on the 80% that doesn’t need the integration.
For compliance – identity verification, high-value refunds – Fin does the legwork, a human makes the final call and then hands it back to Fin. This works natively in the Intercom Inbox and via Slack. Some competitors don’t have an inbox-native variant at all, meaning humans need to leave their primary workspace to review AI actions.
Procedures are also built to let you collaborate with all your teammates – both human agents and AI Agents. Fin can work with them directly inside a Procedure, using APIs and webhooks to loop in another teammate mid-flow, hand off context, and pick back up once they’re done.
Making it easier, faster. Procedures is already self-serve, but the next step is making Procedure creation, testing, and maintenance significantly more streamlined and easy to do, with less manual editing and more AI-assisted building and debugging. There’s a lot coming in this space over the next few months – and it aligns perfectly with a retrieval-first pipeline and stronger governance at scale.
The hardest percentages matter the most. The biggest unlock for your automation rate won’t be answering more FAQs, it will be handling the complex, multi-step queries that consume your team’s time and define what customers remember about their experience with you.
That means working with an Agent that goes beyond answering questions and executes processes. A product your team owns and configures, not a service you buy and hope gets maintained. And a platform where every improvement compounds across every customer. That’s Procedures. Available now, for everyone.
I’ve led product organizations through multiple growth chapters, and the pattern is always the same: the tighter the alignment between product, sales, and marketing, the faster you scale. Reflecting on the journey of Chris Degnan — the first sales hire at Snowflake who spent 11 years helping scale the company from zero to $3.5 billion in revenue as its CRO while partnering with four different CEOs — I’m struck by how consistently the fundamentals win. The playbook isn’t mysterious; it’s disciplined execution, ruthless clarity, and a go-to-market strategy that matures with each revenue stage.
At $10M ARR, the CRO role is hands-on and founder-adjacent. You’re close to the product, running point on key deals, pressure-testing messaging, and building credibility with early customers. By $1B+, the job is organization design: segmentation, international expansion, forecast accuracy, enablement, recruiting, and cross-functional orchestration. The shift is from deal quarterback to system architect — standing up repeatable, auditable processes that produce reliable outcomes across regions, segments, and industries.
Sales leaders who can’t sell the product themselves don’t last. Whether you sit in product management leadership or run the field, you need to master discovery, speak the customer’s language, and translate use cases into value. That also means getting fluent in solutions engineering — understanding integrations, data paths, security, and the operational realities buyers live with. I’ve found this hands-on competence to be the fastest way to earn trust internally and externally, and to keep product strategy grounded in market truth.
The MEDDIC methodology is the foundation for every durable sales org — and, frankly, a founder’s best insurance policy. MEDDIC forces alignment on qualification criteria, from Metrics to Economic Buyer to Decision Process and Identifying Pain. When product and sales both operate to this standard, roadmap bets improve, marketing targets sharpen, and win rates climb. It’s not paperwork; it’s pattern recognition at scale.
High-output CROs obsess over the right numbers. Pipeline coverage by segment and stage; conversion rates through each gate; sales cycle length by use case; average selling price and discount discipline; consumption predictability when you have consumption SaaS pricing; and post-sale expansion velocity. The art is deciding which two or three metrics are the organization’s true north at a given stage — then designing enablement, compensation, and operating cadence around them.
On operating cadence, the week in the life at scale is predictable for a reason. Forecast reviews that surface risk early. Deal reviews that coach to MEDDIC depth, not activity theater. Enablement blocks to uplevel managers and ICs. Recruiting time — always. Customer roadshows to refine value proposition and product positioning. And standing meetings with product, marketing, and finance to keep the GTM motion, roadmap, and unit economics in sync.
Compensation is a force multiplier or a silent saboteur. Keep it simple, consistent, and aligned to the current motion. Early on, weight new logo acquisition and land quality; as you mature, balance new business with expansion, multi-product adoption, and healthy consumption. Guardrails matter — cap over-discounting, reward multi-threading, and avoid plans that create end-of-quarter cliff behavior. The best plans reinforce the behaviors you want your culture to scale.
Technical CEOs often underestimate how much narrative, segmentation, and process discipline great GTM requires. The handoff from founder-led GTM to sales-led growth is where many teams stall. My rule: prove one repeatable motion in one segment before you add complexity. Codify the buyer’s journey, instrument the funnel, and make sure product strategy and enablement move in lockstep.
Culture sets the ceiling. You have to find the fakers, manage-uppers, and passengers quickly — people who look busy but don’t move pipeline, who talk big but avoid accountability, or who ride the momentum of others. The mantra that has saved me endless time: “When there’s doubt, there’s no doubt”. Move fast, but with humanity; be clear on expectations, coach hard, and when it’s not a fit, make the change before the team does it for you.
Feedback is the operating system of a high-performing org. Leaders at every level need to be coachable — on message discipline, on forecast rigor, on how they develop people. I’ve benefited from straight talkers who hold a high bar, and I try to pay that forward. The fastest way to raise organizational IQ is to institutionalize feedback loops across sales, product, and marketing — from post-mortems to win-loss analysis to field-sourced roadmap reviews.
What separates exceptional ICs from the rest? Hunger, intellectual honesty, and a builder’s mindset. They qualify hard, align to customer metrics early, multi-thread to power and value, and partner tightly with solutions engineering. They don’t hide from gaps; they surface them, and they know exactly what they need from product, marketing, and leadership to win.
Executive teams that scale share a few traits: crisp segmentation decisions, single-threaded ownership for outcomes, and healthy conflict that resolves into commitment. Dysfunction, by contrast, looks like metrics roulette, opaque decision-making, and a tolerance for exceptions that become precedent. Make the rules explicit and the exceptions rare.
Leaders like Frank Slootman have popularized intensity, speed, and focus — and there’s real power there when paired with clarity and data. The lesson I carry forward: move fast on people decisions, keep the message simple, and measure what matters. Equally important is knowing where that approach can backfire — when speed outruns learning, or when pressure erodes cross-functional trust. The best operators balance urgency with systems thinking.
Most AI companies will face a go-to-market reckoning. Model quality won’t save a weak motion. The winners will articulate a hard-nosed ROI, solve specific workflow pain, address data governance and security head-on, and show measurable lift — not demo dazzle. In other words, the same fundamentals apply; the stakes and scrutiny are just higher.
If you’re building or rebuilding your revenue engine, start here: define your ideal customer profile and segmentation with ruthless clarity; adopt MEDDIC and teach it across product and sales; align compensation to today’s motion; instrument the funnel and inspect it weekly; and cultivate a culture where feedback is fuel. Do that, and the path from $0 to $3.5B stops feeling like mythology — and starts looking like math.
Your roadmap can be coherent, the launch can go smoothly, and adoption can still stall. The usual gap is not a lack of effort. Product strategy, field discovery, technical validation, and post-launch adoption were treated as separate activities, so each team learned something that the others could not use.
You can close that gap by treating solutions engineering as part of the product learning system. The goal is not to give sales more technical coverage or product managers a larger queue of requests. It is to turn real customer conditions into testable product decisions, then follow those decisions until customers reach and repeat the intended outcome.
Key takeaways
Define adoption as an observable customer behavior before you approve features or plan a launch.
Ask solutions engineers to capture evidence in a consistent format, separating what happened from what the team thinks it means.
Treat demos and proofs of value as experiments with a hypothesis, baseline, value event, and decision rule.
Measure the entire path from promise to repeated value. A login, click, or feature visit is rarely sufficient evidence of adoption.
Route each adoption problem to the right response: positioning, enablement, onboarding, integration, product design, or core capability.
Carry launch learning into roadmap and operating reviews so that adoption changes product decisions instead of becoming a reporting exercise.
Write the adoption contract before debating the roadmap
Product strategy becomes operational only when it specifies whose behavior should change, why that change matters, and what evidence would show that the product created value. Without that translation, teams can agree on a strategic theme while holding incompatible ideas about what success means.
Write an adoption contract for every significant product bet. This is not a legal document or a long requirements package. It is a compact agreement among product, engineering, design, solutions engineering, sales, and customer success about the outcome being pursued.
Target user: Name the persona and operating context. A broad account segment is not enough when different people inside the account perform different jobs.
Starting condition: Describe the workflow, constraint, or workaround that exists before the change. This gives you a baseline against which the new experience can be judged.
Desired outcome: State the progress the customer wants, not the capability you intend to ship.
Value event: Identify the observable behavior showing that the user reached meaningful value. Opening a page may indicate exposure; completing the intended workflow is stronger evidence.
Repeat condition: Define what sustained use looks like at the natural cadence of the workflow. Daily activity is useful only when the job itself occurs daily.
Decision evidence: Agree on the metric, qualitative evidence, technical constraints, and guardrails that will determine whether to continue, change, or stop the bet.
Suppose a product automates part of an operations workflow. Increase feature adoption is too weak to guide a team. A more useful contract says that the operations manager can complete the target workflow, obtain the intended result, and return to it when the job recurs without relying on the old workaround. The team can now examine setup, permissions, integrations, comprehension, completion, and repetition as separate parts of the same outcome.
This contract also changes roadmap conversations. A feature request no longer competes on enthusiasm alone. You can ask which persona it serves, which blocked outcome it unlocks, what evidence supports the problem, and which customer behavior should change if the solution works. If those questions have no answers, the request needs more discovery before it needs an estimate.
Keep the contract stable enough to align the organization, but do not protect it from evidence. If customers repeatedly pursue a different outcome, struggle with an unanticipated dependency, or assign value to another part of the workflow, revise the contract explicitly. Silent reinterpretation is dangerous because every function can declare success against a different definition.
Turn solutions engineering into a field evidence system
A solutions engineer sees details that rarely survive a conventional feature request: the customer’s existing architecture, the sequence of the workflow, the people involved in approval, the point at which a demonstration loses credibility, and the difference between a stated objection and an actual blocker. That information can improve strategy, but only if the organization captures it in a form that product teams can compare and act on.
Do not send raw call notes into a backlog and call it discovery. Use a consistent field record containing:
The persona, account context, and job being attempted.
The customer’s desired outcome and current way of achieving it.
The specific moment where the current product or proposed solution created friction.
The relevant technical condition, such as an integration, data, permission, security, or scalability constraint.
The evidence observed: customer behavior, workflow review, demonstration response, deployment result, or instrumented product data.
The proposed interpretation and any plausible alternative explanation.
The next question or test that would reduce uncertainty.
Within that record, separate observation, interpretation, and request. They are not interchangeable.
Observation: The administrator could not complete configuration because a required permission was unavailable.
Interpretation: The permission model may not match how this persona operates.
Request: Add a new administrative role.
The observation is evidence. The interpretation is a hypothesis. The request is merely a candidate solution. Keeping them separate prevents the first proposed feature from becoming the definition of the problem.
Product leaders also need to protect this system from deal gravity. A commercially urgent request can be important without representing a widespread product problem. Conversely, a small implementation detail can reveal a structural barrier affecting an entire target persona. Evaluate field evidence with questions that make those differences visible:
Does the problem recur for the same persona, workflow, or environment?
Does it block the value event, or does it affect a peripheral preference?
Is the root cause a missing capability, product usability, configuration, integration, positioning, or customer process?
Does the problem appear in the strategic segment the product is designed to serve?
Can a smaller or reversible test distinguish competing explanations?
What roadmap decision would change if the hypothesis were confirmed?
The last question is a useful filter. If no plausible answer would change a decision, the team may be collecting interesting information rather than decision-grade evidence.
Bring the strongest records into the product trio’s learning cycle. Field evidence can then sharpen roadmaps, sprint planning, positioning, integration decisions, and stakeholder conversations. The solutions engineer contributes technical discovery and customer context. Product management synthesizes patterns and owns tradeoffs. Design examines behavior and workflow. Engineering tests feasibility and exposes architectural consequences. Sales contributes commercial context without converting urgency into automatic priority. Customer success adds evidence about repeated use after the initial deployment.
This arrangement does not require every customer conversation to become a committee meeting. It requires a common evidence format, clear decision ownership, and a route by which meaningful field learning reaches the people making product choices.
Run demos and proofs of value as product experiments
A polished demo can prove that a presenter understands the product. It does not prove that a customer can adopt it. Even a successful technical pilot can produce a false positive if the solutions engineer performed work that the target user cannot repeat, the environment was unusually controlled, or the team never defined what customer value would look like.
Design every proof around a falsifiable outcome hypothesis. A practical structure is:
For [persona] in [context], enabling [change] should produce [observable behavior] because [value mechanism]. The hypothesis is supported if [agreed evidence] meets [predefined decision rule] without violating [guardrail].
The brackets force useful decisions. You have to name the user, the operating condition, the expected behavior, and the reason the behavior represents value. You also have to decide what would count as failure before enthusiasm about the result changes the standard.
Build the proof plan around the following elements:
Baseline: Document how the customer handles the job now, including meaningful friction and dependencies.
Scope: State which workflow, persona, environment, and constraints the proof includes. Anything outside that boundary remains unvalidated.
Value event: Identify the customer action or result that demonstrates progress toward the desired outcome.
Instrumentation: Decide which product events and qualitative observations will show where users advance or stop.
Enablement: Record how much assistance the customer receives. Heavy expert intervention can validate technical feasibility while leaving self-service adoption unproven.
Decision rule: Define what evidence will justify progression, iteration, repositioning, or stopping.
Learning owner: Name the person responsible for translating the result into a product, go-to-market, or adoption decision.
A compact learning record can follow Insight – Hypothesis – Experiment – Metric. The sequence matters. A customer comment produces an insight, not a roadmap commitment. The insight leads to an explanation that can be tested. The test produces evidence against a metric or decision criterion.
Capture objections with the same discipline. An objection about missing functionality may actually reflect an unclear value proposition, concern about integration effort, lack of trust in the output, or a mismatch between the buyer and the eventual user. Ask what the customer is unable or unwilling to do because of the concern. That question moves the discussion from the requested feature to the blocked behavior.
At the end of a proof, classify what was learned:
Value validated: The target persona reached the intended outcome under representative conditions.
Need validated, capability missing: The problem matters, but the product cannot yet support the required workflow.
Capability works, adoption friction remains: The product can deliver value, but setup, comprehension, trust, or workflow design prevents the user from reaching it reliably.
Technical path blocked: An integration, architecture, data, permission, or operational constraint prevents deployment.
Positioning mismatch: The product can do what was promised, but the outcome is not important enough for the target persona or was framed in the wrong terms.
Evidence inconclusive: The test did not represent the intended user or environment, or the decision criteria were not measurable.
These outcomes lead to different work. A positioning mismatch belongs in messaging and discovery. Adoption friction may require onboarding or product design. A recurring technical blocker may deserve roadmap investment. An inconclusive test deserves a better test, not a success story.
Demos and early deployments become high-signal learning mechanisms when their evidence returns to product strategy instead of ending in the opportunity record. That closed loop is what allows solutions engineering to improve both customer execution and the underlying product.
Measure adoption as a path, then act at the break
Adoption is not a single metric. It is a sequence that begins with a credible promise and ends when the customer repeatedly receives value. Measuring only the end hides the reason users failed. Measuring only clicks overstates progress.
Map the path for the persona named in the adoption contract:
Promise understood: The user or buyer can connect the product to a relevant outcome.
Entry: The intended user begins setup or enters the target workflow.
Readiness: Required data, permissions, integrations, and configuration are in place.
Activation: The user reaches the first meaningful value event.
Repetition: The user returns when the underlying job recurs and reaches value again.
Expansion: Appropriate users, workflows, or capabilities are added because the initial value is credible.
Retention: The product remains part of the operating workflow because it continues to produce the desired outcome.
Instrument enough of this path to locate the break. For each event, retain the eligible persona or account, relevant product context, action attempted, result, and connection to the intended outcome. Always state the denominator. Activation among configured users answers a different question from activation among all purchased accounts.
Use metrics such as time-to-value, daily active usage, and feature adoption only when they match the product’s natural workflow. A monthly administrative task should not be judged by daily activity. A high feature-visit count does not establish value if users repeatedly enter the feature because they are confused. Pair behavioral data with the qualitative context collected during proofs, implementations, and customer conversations.
Observed pattern
Question to investigate
Likely response area
Interest is high, but eligible users do not begin
Is the value proposition relevant and credible to this persona?
Positioning, targeting, or enablement
Users begin, but readiness fails
Which data, permission, configuration, or integration dependency is blocking progress?
Onboarding, implementation, or platform capability
Users complete setup, but do not reach the value event
Does the workflow lead clearly to the promised outcome?
Product design, guidance, or core capability
Users activate, but do not return
Is the job recurring, and was the first outcome valuable enough to change behavior?
Discovery, workflow fit, trust, or value proposition
Adoption differs sharply by persona or context
Was the product designed and positioned for the segment that is actually succeeding?
Segmentation, strategy, or packaging
Usage is high, but retention or customer outcomes remain weak
Is activity measuring value, required effort, or repeated friction?
Metric design, product quality, or outcome alignment
Match the intervention to the break. Use onboarding checklists, empty-state prompts, in-app guides, and product tours when the user needs contextual direction. Do not use a tooltip to conceal a broken permission model, an unreliable integration, or a workflow that does not create enough value. Guidance can reduce comprehension friction; it cannot repair a missing capability.
When you test an intervention, define the intended behavior change and success criterion in advance. Segment the result by the persona and context in the adoption contract. An aggregate improvement can hide a deteriorating experience for the strategic user, while a neutral aggregate can hide a strong response in the segment the product is meant to serve.
The adoption contract and any evidence that challenges it.
Progress through the journey, segmented by the intended persona and context.
The strongest field observations, with interpretations kept separate.
The active hypotheses and experiments.
The product, positioning, enablement, integration, or onboarding decision each experiment may change.
The owner responsible for making that decision and returning the result to the group.
Use operating reviews and QBRs to evaluate outcomes, not to count shipped features or completed guides. Ask which hypothesis was confirmed, which constraint was removed, where customers still stop, and what the organization will do differently. If an experiment has no route to a decision, revise it or stop it.
For your next significant product bet, start before the launch plan. Write the adoption contract, ask a solutions engineer to challenge it with field conditions, and define the evidence that would change your mind. That small discipline gives every later conversation – roadmap, demo, onboarding, analytics, and QBR – the same customer outcome to pursue.