I’ve watched the rise of product engineering up close, and it’s reshaping how we build software. The old model of rigid handoffs and separate functions is giving way to small, empowered product teams where engineers own the customer problem end to end. That shift isn’t just cultural—it’s a performance advantage that compounds with every release.
I often summarize it this way: “Product engineers are taking over. They ship code, talk to users, and own outcomes—no handoff required. Here’s what the role is, and why it matters now.”
When I say “product engineer,” I’m describing a builder who goes beyond writing code. I expect them to partner in product trios with product management and design, participate in continuous discovery, and make decisions grounded in product strategy and real customer insight. They don’t toss features over a wall; they own the problem, the solution, and the measurable outcome.
Why now? Modern delivery practices like CI/CD and feature flags compress feedback loops, while behavioral analytics and session replay make customer friction visible in real time. As expectations rise for quick iterations and clear value, teams that reduce handoffs and align around outcomes outperform on DORA metrics such as deployment frequency and lead time for changes.
Day to day, a strong product engineer blends discovery and delivery. They join customer interviews, review support tickets, analyze usage patterns, and run A/B testing to validate hypotheses. Then they ship code in small, safe increments, instrument telemetry, and watch adoption and retention signals to confirm they’re moving the numbers that matter.
Team shape matters. I favor compact, cross-functional squads anchored by product trios, each with explicit outcomes vs output OKRs. Product engineers often operate like forward deployed engineers, partnering with customer success and solutions engineering to learn at the edge of real-world usage. This proximity to customers turns ambiguity into insight—and insight into product leverage.
Accountability is concrete. We track DORA metrics for delivery health and pair them with product outcomes such as activation, time-to-value, and Net Recurring Revenue (NRR) drivers. The combination keeps us honest about both how fast we move and whether what we ship truly works for customers.
The hiring profile is distinct. I look for engineers who are curious about the “why,” comfortable with trade-offs, and energized by customer conversations. They can navigate architectural complexity, but they also translate user feedback into crisp product bets. Many grow into natural facilitators of discovery rituals and developer evangelism across the organization.
If you’re getting started, pilot a single squad. Establish clear outcomes vs output OKRs, invest in CI/CD and feature flags, and commit to continuous discovery with weekly customer interviews. Give the team ownership of a KPI tied to product strategy, and measure progress with DORA metrics plus usage and retention signals. The early wins—fewer handoffs, faster learning, tighter feedback loops—build momentum quickly.
In short, product engineers thrive where accountability, autonomy, and user empathy meet. They reduce wasteful coordination, shorten the path from insight to impact, and ensure we ship code that customers actually adopt. That’s why this role is reshaping how software gets built—and why the teams that embrace it will set the pace for everyone else.
Old-school, in-person selling is having a renaissance in the AI era, and I’ve seen why up close. From leading product and go-to-market teams through hypergrowth, I keep returning to one lesson: enterprise buyers still reward the teams who show up, orchestrate change management, and own outcomes end-to-end. The tech has changed; the human dynamics haven’t.
Has the sales playbook changed in the AI era? The tools are faster and the surface area is bigger, but the core motion remains the same: “showing up” beats letting the marketplace decide. That’s why in-person enterprise rollouts still beat product-led motions, especially when the stakes include security, governance, and cross-functional adoption. You win by reducing organizational risk, not by assuming free trials will do the heavy lifting.
Great enterprise sellers collapse silos. They sell to engineers and executives in one motion, pairing deeply technical validation with crisp business narratives. In my org, that means every high-velocity pilot has a dual thread: hands-on, eval-driven proof for the builders and a value architecture for the budget owners. When those motions run in parallel, time-to-value plummets and procurement friction fades.
Selling to AI-native buyers who grew up on ChatGPT changes tempo, not fundamentals. The same seller, different tempo: 8 weeks vs. 8 business days. These buyers evaluate fast, expect clear ROI, and push for automation-first workflows. How AI-native buyers handle build vs. buy decisions comes down to build for differentiation and buy for acceleration. If you make procurement feel like product—frictionless, instrumented, and transparent—you’ll meet their bar.
Process matters, but humanity wins. Building a robust sales process that still leaves room for unscripted moments is where trust is formed. I’ll never forget the story of the rep who taught a champion’s son guitar over Zoom—an unscripted moment that cemented a partnership. The lesson: raise the floor without capping the ceiling. Equip every rep with repeatable plays, then celebrate the creative instincts that make champions out of customers.
In early GTM, why the three highest-leverage early sales hires aren’t sellers at all resonates with my experience. I prioritize a solutions engineer who can de-risk integration, a forward-deployed operator who can run the first rollout like a product manager, and a customer success lead who designs adoption paths from day zero. Together, they compress the value journey from proof to production.
Compensation design shapes your talent market. The case for outsized commission accelerators for star sellers — and the kind of person they attract is real: magnets for competitors who close complex, multi-threaded deals and thrive with ownership. But beware: why too much process narrows the kind of seller you attract. Over-script it and you filter out the very people who can navigate ambiguity with customers.
Under the hood, instrumenting the funnel from stage zero to close keeps the system honest. I track intent signals before pipeline, conversion by persona and use case, proof milestones, and time-to-value in production. The three pillars of GTM excellence for me are repeatable discovery, referenceable outcomes, and relentless enablement. And inside the leadership team, building peers who are 80% aligned, not 100% preserves healthy tension while keeping execution fast.
AI is expanding the definition of enablement—whether AI is changing what good enablement looks like isn’t a theoretical question anymore. I see world-class teams arming reps with retrieval-first knowledge bases, sandbox environments, and objection libraries that evolve weekly. Meanwhile, selling against direct and implied competitors at once is the norm: your battlecard must cover “do nothing,” internal tools, adjacent categories, and new AI entrants—while you still remember why in-person enterprise rollouts still beat product-led motions for durable adoption.
Planning horizons tighten in AI markets. How far out should a GTM leader be planning? I work a dual cadence: a rolling 6-week operating plan that’s ruthlessly tactical and a 2–3 quarter roadmap for coverage, enablement, and category storytelling. What a normal week looks like in hypergrowth blends customer time, pipeline triage, onboarding and enablement, deal engineering, and process tuning—always with one or two high-conviction bets that could bend the curve.
If you’re scaling an AI product today, pair a disciplined sales-led growth engine with the best of product-led growth: fast paths to proof, hands-on validation for builders, executive-level value mapping, and human moments that turn customers into advocates. That’s how you compress an eight-week cycle into five business days—and keep the expansion flywheel spinning.
Your cloud-cost agent can identify the line item that moved and still fail to change a single decision. The gap appears after the diagnosis: the recommendation arrives without the product, pricing, ownership, and risk context needed to act.
If you are taking an internal FinOps capability into the customer experience, design for a closed decision loop. The goal is not autonomous cost cutting. It is a governed system that connects spend to customer value, recommends the next move, and proves whether the move worked.
Design a decision loop, not another cost dashboard
Start by naming the decision your product will improve. A broad promise such as optimize cloud spend gives the agent no useful boundary. A better contract is: detect a material change in workload cost, identify the most plausible driver, propose one permitted response, route it to the right owner, and verify the effect.
Agentic does not mean unrestricted. It means the agent can select the next permitted step based on context. Deterministic services should still perform calculations, enforce policies, check permissions, and execute infrastructure changes. Use the model where interpretation is valuable: reconciling signals, building a driver narrative, identifying missing context, explaining tradeoffs, and routing a decision.
That distinction matters in FinOps. A model should not improvise a billing calculation, invent a price, or bypass a commitment policy. If a calculation has one correct result, compute it in code and give the result to the agent as evidence.
Learning layer: Post-action telemetry, realized outcomes, agent evaluations, customer feedback, and recurring patterns that belong in the product roadmap.
A retrieval-first pipeline that combines billing, usage, observability, product, and go-to-market context is more useful than a large prompt containing a monthly cost export. Retrieve the records needed for the current decision and preserve their lineage. Every recommendation should reveal which records were used, when they were updated, which pricing assumptions applied, and what the agent could not retrieve.
Customer-facing retrieval adds another non-negotiable boundary: tenant isolation must be enforced before context reaches the model. Do not rely on a prompt to prevent cross-customer disclosure. Access control belongs in the retrieval and service layers, with the resulting access decision recorded in the audit trail.
Start with one anomaly and one reversible response
Your first release does not need to optimize every cloud service. A practical thin slice is anomaly detection plus one high-leverage remediation path. For example, the agent might detect a change in non-production workload cost, connect it to a schedule change, prepare a schedule correction, request approval from the workload owner, and monitor the next usage window.
Choose a first action that is bounded and reversible. A scheduling correction is easier to inspect and undo than a long-term financial commitment or a production capacity change. The purpose of the thin slice is to prove the whole operating loop, not merely the anomaly model.
Make every recommendation safe enough to act on
A recommendation without an execution envelope is an opinion. It may be correct, but the recipient still has to reconstruct the evidence, find the owner, assess the downside, and decide how to validate it. That is where apparently intelligent systems create more work than they remove.
Use a recommendation contract
Treat every agent recommendation as a structured product object. At minimum, require these fields:
Decision: The exact choice the recipient is being asked to make.
Scope: The account, workload, service, environment, and time window affected.
Owner: The person or role accountable for the workload and the person authorized to approve the action.
Evidence: Links to the billing, usage, observability, deployment, and product records that support the diagnosis, including their freshness.
Driver path: The causal chain the agent believes explains the change, plus material alternative explanations it considered.
Proposed action: The change, its expected mechanism, and any assumptions behind an estimated effect. If the effect cannot be estimated reliably, say that it is unknown.
Confidence and unknowns: Evaluation-backed confidence evidence, missing context, and conditions that would invalidate the recommendation.
Verification plan: The telemetry, observation window, success condition, and stop condition used after the action.
The expiration field is easy to overlook. Cloud state changes quickly enough that an old recommendation can remain plausible after its evidence has gone stale. Expire the recommendation when its pricing, topology, deployment, or usage assumptions are no longer current. Force a fresh retrieval before execution.
Grant autonomy by action class
Do not give an agent one global autonomy setting. Earn autonomy independently for each action class:
Observe: Detect and organize a possible anomaly.
Explain: Build a driver tree and expose supporting evidence without proposing a change.
Recommend: Propose an action while a human retains approval and execution.
Prepare: Generate a change plan or dry run, but require an authorized owner to apply it.
Execute within policy: Apply a reversible, bounded action only when the policy engine, permissions, evidence freshness, and rollback checks all pass.
Purchasing a cloud commitment or altering production resources can create real financial or availability exposure. Keep finance and service owners in the approval path until confidence evidence and post-action telemetry demonstrate reliable performance for that specific intervention. Good results on anomaly explanations do not establish that the same agent is safe to execute infrastructure changes.
Governance should be visible in the product, not left in a policy document. Show the approver which data was accessed, which rules passed, who changed the recommendation, what action ran, and what happened afterward. Privacy-by-design, data controls, and transparent decision logs are part of the user experience when the system influences money and production infrastructure.
Evaluate the decision loop, not the prose
A polished explanation is not evidence of a useful agent. Build evaluations around the failure modes that can block or distort a decision:
Did the recommendation use the correct customer, workload, environment, price, and time window?
Can each material claim be traced to an underlying record?
Does the driver path match known cases, including cases with several plausible causes?
Does the agent abstain when ownership, telemetry, or pricing context is missing?
Did approval routing and policy enforcement behave correctly?
Can the recipient perform the proposed action without reconstructing missing steps?
Did post-action telemetry confirm the expected direction of change without creating an unacceptable operational tradeoff?
Put retrieval changes, prompts, policies, and tools through the same delivery discipline as application code. Eval-driven development, CI/CD, and a weekly shipping cadence make regressions visible before a persuasive but poorly grounded recommendation reaches an operator or customer.
Embed the capability with customers before scaling it
The first customer version should not be a general-purpose cost chatbot. It should be a narrow, product-assisted engineering motion in which a Forward Deployed Engineer, or FDE, helps the customer connect product usage, cloud architecture, and cost-to-value.
Choose a small pod and customers that can teach you
A sensible starting shape is one FDE pod focused on two or three high-potential customers. High potential should not mean merely the largest cloud bill. Select customers where the team can access the necessary evidence, an accountable sponsor can authorize changes, the problem is likely to recur, and the customer agrees to clear data and governance boundaries.
Evidence readiness: Billing, metering, observability, pricing, and deployment context can be joined without weeks of manual reconciliation.
Decision access: An engineering, product, or finance owner can approve an intervention and explain the operational constraints.
Learning value: The problem represents a pattern that may apply beyond one account.
Measurability: The customer and FDE can agree on a cost-to-value measure before making a change.
Governance fit: Data access, retention, tenant isolation, approvals, and audit expectations are explicit.
If any of these conditions is absent, the engagement may still be commercially important, but it is a weak environment for deciding whether the agentic product works. Separate account urgency from product-learning quality.
Run a customer optimization loop that produces reusable knowledge
Define the value unit. Agree on what an active workload or valuable unit of product usage means. Total spend alone cannot distinguish efficient growth from contraction.
Establish the baseline. Record current cost per active workload, time-to-first-value, relevant deployment behavior, and the constraints the customer will not trade away.
Build the driver tree. Connect the spend change to services, environments, releases, product behavior, and customer usage. Surface gaps instead of filling them with assumptions.
Select one intervention. Prefer the smallest action that can test the diagnosis. Document the expected mechanism, approver, risk, and rollback before execution.
Verify the outcome. Compare post-action telemetry with the agreed baseline. Record savings, unit-economics movement, performance effects, adoption effects, and unintended consequences separately.
Codify the pattern. Capture the inputs, decision rule, action, exceptions, safeguards, and evidence required to repeat the intervention.
Send a weekly learning packet to product. Include successful patterns, failed diagnoses, missing platform capabilities, customer language, and recommendations that still depend on FDE judgment.
Customer-embedded optimization creates an obvious trust question for a consumption business: does the vendor want the customer to spend less or consume more? The clean answer is to optimize cost-to-value rather than either number in isolation.
A customer’s total cloud cost can rise while cost per active workload improves because valuable usage is growing. Total cost can also fall because the customer is using less of the product, which is not an optimization success. Label the outcome precisely: lower total spend, lower unit cost, avoided waste, shifted commitment, higher useful consumption, or reduced operational risk. Do not collapse these different effects into a generic savings claim.
The FDE is also a trust boundary. The role should explain the recommendation, expose assumptions, and represent the customer’s constraints. It should not become a human interface for repetitive exports and one-off queries that the platform ought to handle.
Turn field work into a roadmap, not permanent custom service
A strong FDE can make a weak product look successful by solving every gap manually. That is useful for an individual customer and dangerous for product strategy. You need an explicit test for moving work from the field into an agent workflow or native platform capability.
Apply a productization test to every recurring intervention
Can the same signal be retrieved reliably across the intended customer segment?
Can the decision logic be expressed without undocumented customer-specific knowledge?
Can the action be bounded by a stable policy, approval path, and rollback procedure?
Can the outcome be measured with telemetry that exists before and after the change?
Do the likely exceptions fit a review workflow, or do they fundamentally change the decision?
If the signal, decision, action, and measurement are repeatable, make the pattern a native feature or automated playbook. If the evidence is repeatable but judgment varies, keep an agentic workflow with human review. If the action carries high financial or availability risk, keep the FDE and accountable owner in the loop. If the pattern is a one-off, document it but resist turning it into product scope.
Use a scorecard that reveals where the loop is breaking
Dimension
Measure
Decision it informs
Insight speed
Time-to-insight from a material spend change
Is the system finding the issue early enough to change an engineering decision?
Action quality
Recommendations with evidence, an owner, a permitted action, and a verification plan
Is the agent producing executable decisions or polished commentary?
Economics
Realized savings per recommendation and cost per active workload
Did the intervention improve spend or unit economics for the intended value unit?
Reliability
Post-action effects, abstentions, rollbacks, and policy failures by action class
Which interventions have earned more autonomy, and which need tighter controls?
Customer outcome
Time-to-first-value and NRR movement on FDE-supported accounts
Is the motion improving adoption and durable account value? NRR is directional evidence, not proof of causation.
Product leverage
Recurring field patterns converted into features, guardrails, or in-product guidance
Is customer work compounding into a scalable product?
Recommendation volume, prompt length, and agent activity are operating diagnostics, not business outcomes. A quiet system that changes a few high-value decisions can be more useful than an active system that produces hundreds of unactioned findings.
Make build versus buy a component decision
Do not treat the choice as one monolithic platform decision. Separate commodity capabilities from the context and workflow that create differentiation. Evaluate billing ingestion, normalization, anomaly detection, the context model, pricing logic, recommendation policy, approval routing, execution, and agent analytics independently.
Does the capability require knowledge of your architecture, pricing model, feature flags, customer usage, or deployment behavior?
Can an external component preserve evidence lineage, tenant isolation, and decision logs at the level your customers require?
Is the capability a generic input to the product, or is it where your product makes a differentiated decision?
Can your team evaluate and operate the component continuously, including regressions after model, prompt, policy, or data changes?
Will the component reduce time-to-value without trapping critical customer and pricing context in an opaque workflow?
Give the core product to a product trio spanning product management, engineering, and FinOps. Bring FDE, customer success, SRE, finance, and security into discovery and evaluation where their decisions are affected. Field requests should enter the roadmap with evidence of recurrence, strategic importance, or platform leverage rather than becoming an informal side door to custom development.
Key takeaways
Define the product as observe, explain, propose, authorize, execute, and verify. Diagnosis alone is not an agentic outcome.
Retrieve billing, usage, observability, pricing, product, and ownership context for each decision, with lineage and tenant boundaries enforced outside the prompt.
Represent every recommendation as a governed contract containing evidence, owner, action, risk, approval, rollback, expiration, and verification.
Grant autonomy by action class. Keep humans in the loop for commitments and production changes until that intervention has reliable post-action evidence.
Start customer delivery with one FDE pod and two or three customers that offer evidence access, decision access, measurable value, and reusable learning.
Measure time-to-insight, realized outcomes, unit economics, reliability, customer value, and productized patterns instead of counting recommendations.
This week, choose one recurring cost anomaly and map the complete path from underlying records to a verified action. Name the owner, approval rule, rollback, and success telemetry before improving the prompt. Do not add a second workflow until the first can explain what changed, why the action was allowed, and whether it improved customer cost-to-value.
Your startup can produce impressive demos every week and still learn slowly. If model behavior, customer evidence, and deployment feedback move through separate queues, faster shipping only creates more uncertainty.
If you are deciding how to run an AI-native startup, use one standard: how quickly can your team turn a real customer artifact into an evaluated product change and a measurable customer outcome? That standard should shape your wedge, ideal customer profile, team design, sales motion, and operating cadence.
Build the smallest closed learning loop
An AI-enabled company can add a model to an existing product process. An AI-native company has to organize the process around intelligence itself: the data entering the system, the judgment the model makes, the action produced, the evaluation of that action, and the feedback that improves the next decision.
That makes a long AI feature list the wrong starting point. Begin with the smallest end-to-end loop that proves the product’s central claim. In a security product, for example, the loop might start with suspicious activity, produce a risk judgment, stop or downgrade a threat, and capture enough evidence to assess whether the intervention was correct. A polished dashboard without that closed loop is packaging, not proof.
Use three gates before committing to a wedge:
The customer can quantify the problem. Ask for frequency, severity, operational burden, or another observable consequence in the customer’s own workflow. General concern about AI is not enough.
The wedge can create value within one buying cycle. If proving value requires a broad platform rollout, several integrations, and organizational change across multiple functions, you have probably selected a destination rather than an entry point.
Product use improves your data advantage. Determine what feedback the product will capture, whether you can legitimately use it, how quickly it arrives, and which evaluation or model decision it improves. Data volume alone does not create an advantage.
Failing any one of these gates weakens the loop. Urgent pain without accessible data leaves the model blind. Useful data without a near-term outcome produces an experiment that customers may admire but will not adopt. A fast result that teaches you nothing can become a services engagement disguised as software.
Your first version should feel narrower and less polished than the roadmap in your head. It may require manual review, a rough operator interface, or close founder involvement. That is acceptable when the roughness is visible and recoverable. It is not permission to hide model failure, skip evaluations, or make consequential actions impossible to inspect. Cut breadth before you cut control.
Define completion around the loop rather than the interface. You are done with the first proof when a target customer can supply the relevant input, receive the intended outcome, show whether it helped, and feed the result back into a repeatable evaluation. Everything else competes with learning speed.
Choose an ICP that maximizes learning density
The largest market is rarely the most useful starting market. Your early ideal customer profile should concentrate urgency, usable data, workflow access, and a reachable decision maker. Those conditions allow one customer interaction to improve both the product and the go-to-market motion.
Create a one-page ICP card with four evidence fields:
Urgency: What is happening now that makes the buyer act rather than merely agree that the problem matters?
Data pathway: Which alerts, cases, decisions, errors, or other operational artifacts can enter the product and its evaluation process?
Workflow position: Where will your output appear, who will act on it, and what existing step must change?
Success signal: What observable customer outcome would justify adoption, renewal, or expansion?
Rate each field as high, medium, or low, but require an evidence note beside the rating. A founder’s conviction is not evidence. A buyer who can describe the cost of the problem, provide representative artifacts, identify the operator who owns the workflow, and agree on a success signal gives you something testable.
Keep adjacent customer segments out of the first learning loop when they require different data, integrations, evaluation criteria, or buying logic. A larger pipeline can make progress look healthier while mixing incompatible requirements into the roadmap. The practical test is simple: if two prospects would judge the same model behavior by different definitions of success, they should not share an early product plan merely because they could buy from the same company.
Founder-market fit helps here, but it is a compression mechanism rather than proof of product-market fit. Deep domain experience can sharpen the problem statement, reduce translation with buyers, and establish credibility. It cannot substitute for evidence that customers will change a workflow around the product.
Founder-led sales should therefore operate as a structured discovery system. For every lost or stalled opportunity, record the exact objection, the stage at which it appeared, the evidence offered by the buyer, and the suspected root cause. Do not turn each objection into a feature request. Cluster the objections, identify the two most common root causes, and turn those into experiments within a sprint.
Look beyond compliments when judging early product-market fit. Stronger signals appear when customers escalate a problem to your team, volunteer data that can improve the system, or invite you into the workflow where decisions are made. None is conclusive alone, but each requires the customer to spend trust, attention, or organizational effort. That makes them more informative than enthusiasm during a demo.
Organize the team around evaluation and deployment
A conventional feature organization separates product definition, engineering delivery, model work, implementation, and customer support. That creates handoffs precisely where an AI-native startup needs rapid feedback. Organize durable units around a customer outcome, with the people who can inspect data, change the system, deploy it, and evaluate the result.
The exact titles can vary, but the unit needs four capabilities:
Product judgment: Choose the scenario, define the customer outcome, and decide which uncertainty deserves the next experiment.
Model and data judgment: Design evaluations, diagnose failure patterns, and understand whether a change improves one scenario while damaging another.
Product engineering: Turn model behavior into a reliable workflow with usable interfaces, permissions, integrations, and operational controls.
Frontline deployment: Work safely in live customer environments, resolve implementation friction, and return generalizable learning to the product.
Forward deployed engineers and solutions engineers are especially valuable when the product has to enter complicated workflows. They can shorten the distance between a live failure and a product decision. They can also become an unofficial custom-development queue. Prevent that by attaching three fields to every customer-specific change: the broader pattern it tests, the product owner responsible for reviewing the result, and the condition under which the work will be standardized, stopped, or kept outside the core product.
AI fluency should also change your hiring process. Model vocabulary on a resume tells you little about how someone will reason under uncertainty. Give candidates a work sample built around a realistic failure: model performance changes across scenarios, the data distribution is moving, and customer trust is at risk.
Ask the candidate to define the evaluation, explain the consequences of false positives and false negatives, diagnose a precision-recall tradeoff, and translate the technical result into a product decision. The strongest response will not jump straight to a model change. It will clarify the scenario, inspect the evidence, identify what the current evaluation misses, and explain the tradeoff in terms an operator or buyer can use.
Use the same discipline for founder and leadership disagreement. Write down the principle in dispute, the evidence each side is using, the decision owner, the time box, and the condition that will trigger a review. Debate the principle rather than multiplying competing implementation plans. Once the decision is made, commit until the agreed review point. This preserves speed without pretending that an uncertain decision has become permanently correct.
Run model and business evidence on the same cadence
An AI-native startup needs two connected scoreboards. One shows whether the system is becoming more reliable. The other shows whether customers are receiving enough value to adopt, retain, and expand. Reviewing them separately makes it easy to celebrate a model improvement that does not change customer behavior, or a short-term commercial win built on fragile product performance.
Evidence layer
Question
Measures to inspect
Decision it should inform
Scenario quality
Does the system make the right judgment in each important situation?
Precision and recall by scenario; recurring misclassification patterns
Evaluation coverage, data work, model changes, and acceptable operating thresholds
Change detection
Does the system recognize when its environment is moving?
Drift, data freshness, and time to first signal for an emerging pattern
Refresh cadence, investigation priority, and new evaluation cases
Operational experience
Can the customer use the output without creating a new burden?
Alert-fatigue reduction and latency under load
Workflow design, prioritization, and deployment constraints
Business value
Is reliable behavior turning into durable adoption?
Activation, expansion, and Net Recurring Revenue
ICP focus, onboarding, positioning, and roadmap investment
Do not collapse these measures into one composite score. Aggregation hides the failure mode you need to fix. A model can improve overall precision while degrading a high-consequence scenario. Activation can remain flat even when evaluation results improve because the output arrives too late, lacks an escalation path, or does not fit the operator’s workflow. The broken link between the two scoreboards is often the most valuable finding in the review.
Make the weekly customer debrief evidence-based. Bring actual alerts, misclassifications, escalations, and deployment failures rather than a verbal account of how the customer feels. For each material artifact, record the hypothesis it challenges, the evaluation that can reproduce it, the next bet, and the owner. That written log becomes organizational memory when priorities change quickly.
Use an evaluation gate for every consequential release:
Run the relevant scenario-level evaluations, not only an aggregate benchmark.
Inspect newly introduced failure modes as well as improvements to the target case.
Check latency and operational behavior under the conditions the customer will actually use.
Name the owner of monitoring, escalation, and rollback before deployment.
This is not process for its own sake. In an AI product, observability is the control center for trust. It tells your team whether the model still deserves the authority the workflow gives it. Demo speed cannot compensate for an inability to see, explain, and correct failure in production.
Key takeaways for your next operating cycle
Define the product as a closed loop from customer signal to verified outcome, not as a list of AI capabilities.
Commit to a wedge only when the problem is quantified, value can appear within one buying cycle, and legitimate product use improves the data advantage.
Select the first ICP for urgency, data access, workflow access, and a clear success signal. Keep adjacent segments separate when they require different definitions of success.
Turn founder-led sales into a discovery system by logging every rejection, clustering root causes, and testing the two most common causes within a sprint.
Build durable customer-facing units that combine product, model, engineering, and deployment judgment.
Review scenario-level model evidence and business outcomes together, then investigate the link whenever one improves without the other.
For your next planning cycle, choose one ICP, one end-to-end loop, one scenario-based evaluation set, and one customer outcome. Give a single owner responsibility for showing the connection between them. If the team cannot trace that chain with production evidence, the roadmap is still too broad. Narrow it before adding another feature, segment, or model.
References
Shivam.Consulting Blog – Inside Artemis’ AI vs AI Security War: Hiring at Speed, PMF Signals, and Founder-Led Sales
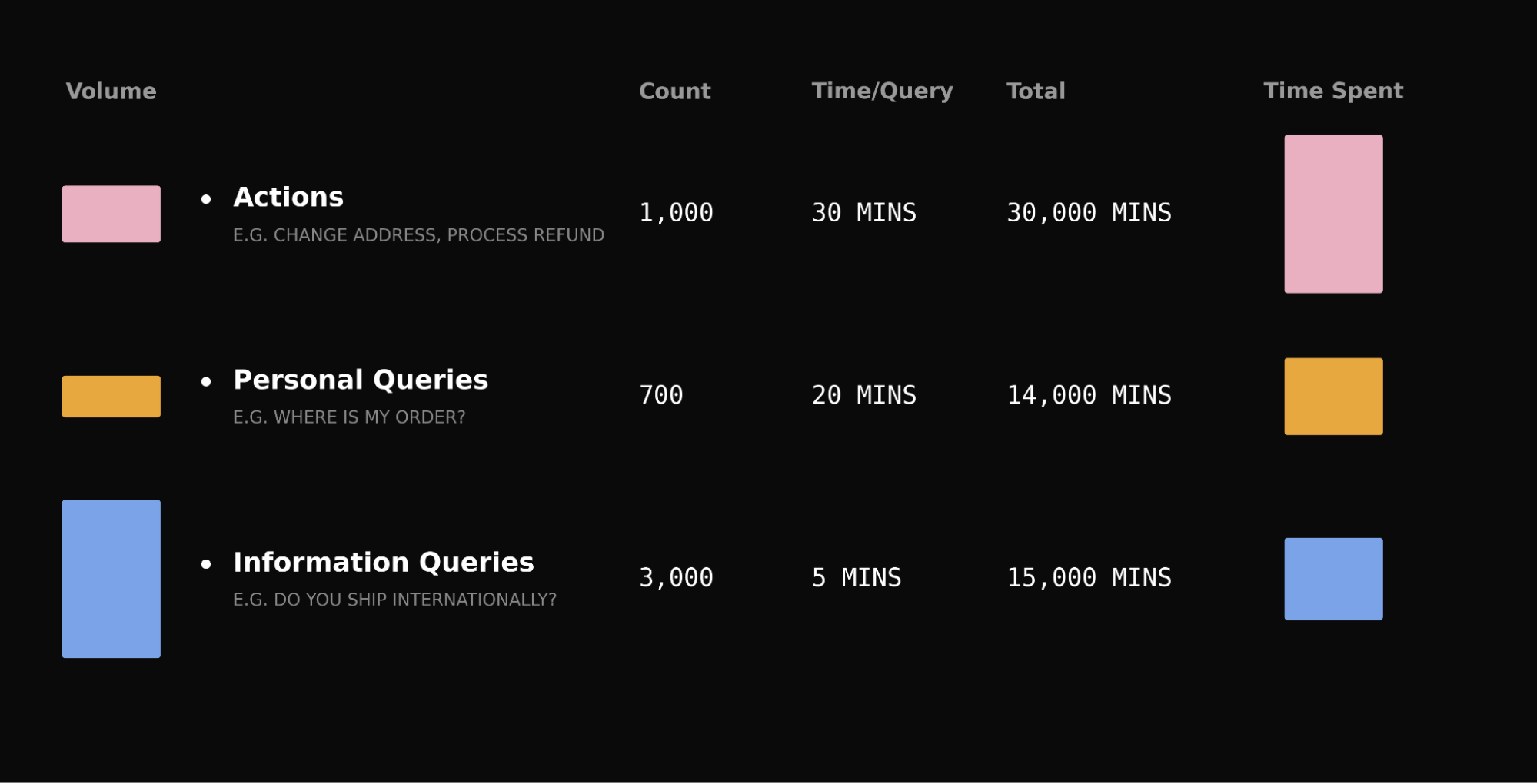
I’ve learned that the smallest slice of your support queue often dictates the majority of your operating cost, customer memory, and automation ceiling. In product reviews and CX ops deep-dives, I see the same pattern: the “easy” tickets pad your resolution counts, but the complex, multi-step queries quietly own your handle time and your brand trust. If you care about compounding impact, your customer support AI strategy has to target that hardest percentage first.
Complex queries are a small percentage of your queue, but they consume a disproportionate share of your team’s time.
Take a typical queue: password resets outnumber refund disputes ten to one, but a reset takes five minutes and a dispute takes thirty. The “rare” query accounts for over a third of total handling time. The same pattern holds for account investigations, subscription changes, and billing disputes.
How you handle complex queries is also what customers actually remember about their support experience. When someone is dealing with a damaged order or a billing dispute, the stakes are higher, and a fast, good resolution is what separates a forgettable interaction from one that builds lasting trust.
Most AI Agents automate the easy, informational queries well. The question for your automation rate is whether they can handle the hard ones. That’s where agentic AI and robust AI workflows make or break your outcomes.
We’ve gotten really good at informational queries – the hard part is what comes next. I’ve seen teams invest deeply here, and for good reason: it lifts containment quickly and cheaply. But to break through the plateau, you have to execute actions across systems, not just answer with text.
We’ve invested deeply in informational Q&A. We built Apex, a specialized customer service model trained on billions of support interactions, as Fin’s core answering engine. Beneath that sits a custom retrieval model, a purpose-built reranker, and a unified RAG pipeline, all trained specifically for customer service. Fin resolves issues at a higher rate than general-purpose frontier models, with fewer hallucinations and at lower cost.
But informational Q&A only covers queries where text is the answer. Most Agents can handle that. Far fewer let you configure complex, multi-step actions without a forward-deployed engineer setting it up for you, which creates a gap.
Every query your team handles falls into one of three categories:
Informational: “Can you ship transatlantic by priority next day?” Answered with text from your knowledge base.
Personalized: “Where is my order?” Requires data unique to that user.
Action-led: “My order arrived damaged, I need a refund.” Requires doing something: checking a return window, cross-referencing transaction data, making a judgment call – reading from multiple systems and acting across them.
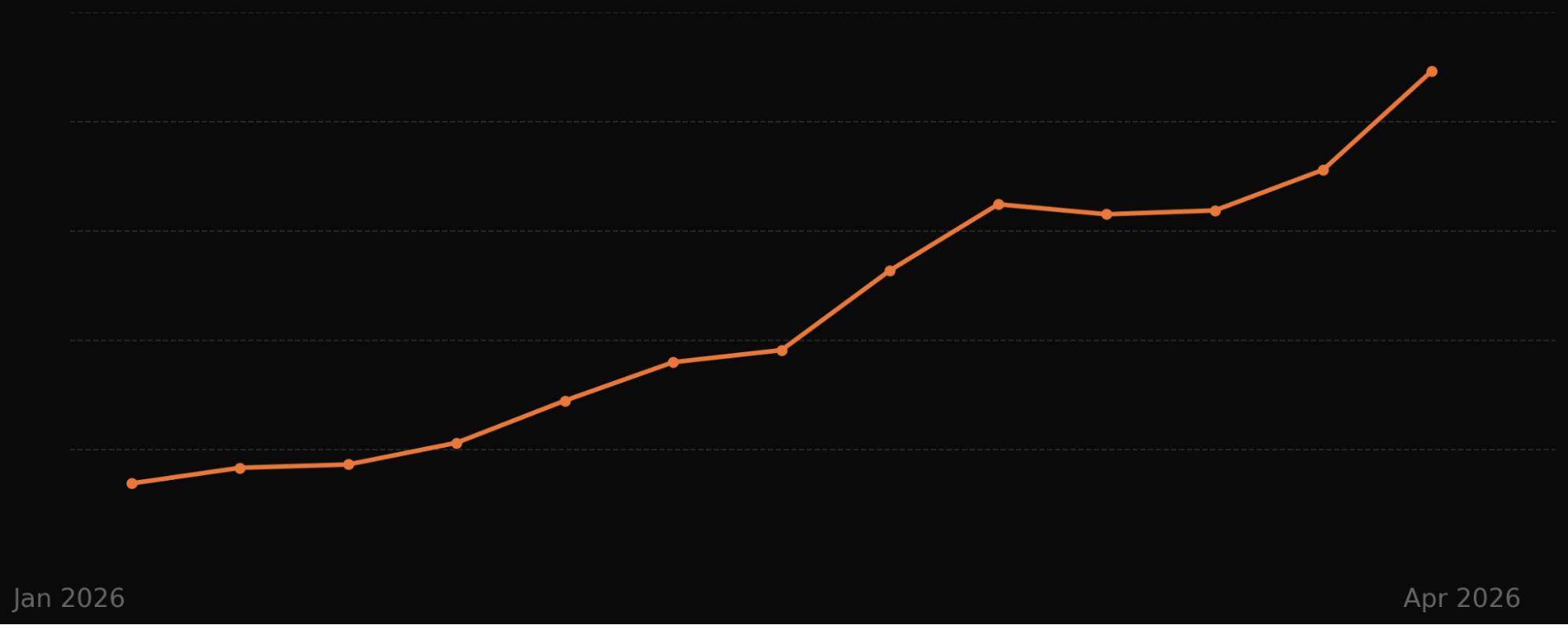
From Jan to Apr 2026, the trend moves steadily upward, pausing briefly before a sharp late surge. A clear snapshot of momentum for customer service KPIs, finance results, and the impact of new procedures.
These complex queries, the ones that require multi-step processes across systems, aren’t edge cases; they’re the reason your support team exists. This is the gap Fin Procedures was built to close.
It works in practice, and the trajectory matters for product strategy and ops planning.
Procedures is live, it’s scaling, and the results are clear. Since launching in managed availability, Procedures has handled over 1.5 million conversations, and volume is doubling month over month across hundreds of apps in fintech, e-commerce, gaming, healthcare, and SaaS.
When customers hit complex, multi-step queries, the experience is dramatically better when Fin can do the work end-to-end. We tested this with a randomized 5% holdout – conversations where Procedures would normally run, but didn’t. CSAT was 28.93% higher when Procedures ran, a statistically significant result.
A product, not a services engagement. I’ve sat through too many “automation” projects that were really solutions engineering gigs: workshops, custom scripts, then a queue of change requests when policies shift. It’s fragile and slow.
The B2B AI industry has a consultingware problem. It’s not databases being forked anymore, it’s prompts. The economics of maintaining bespoke setups per customer don’t work. Either the application falls behind new models, or the vendor changes the model and quality degrades invisibly.
In my view, an agentic AI platform should be a product your team owns end to end: a natural language editor – literally paste your existing SOPs – branching logic, data connectors, and AI-powered simulations for testing. Your CX ops team configures this, iterates on it, owns it. If you need help, a forward-deployed team can assist, but they’re optional, not a dependency. You always have control.
And because it’s a unified product, improvement compounds. When the vendor optimizes a prompt, every customer’s Procedures get better. When they upgrade the model, they can A/B test across the entire customer base and know it’s better before rolling out. You can’t do that when every customer has a bespoke prompt. The consulting model isn’t just expensive, it’s structurally unable to compound.
Today, Fin Procedures is available to every Intercom customer – no waitlist or managed rollout, ready for all 8,000+ customers.
We’re iterating fast based on real customer feedback. Here’s what’s landed since the last major update, and why it matters for reliability and governance:
AI-powered Procedure review: Flags broken logic, missing references, and unreachable conditions before you deploy.
Kick off your journey with the #1 Agent—an AI partner designed to turn resolutions into real outcomes. Tap “Start a free trial” to explore faster, smarter customer service and see how Fin delivers value from day one.
Procedure failure reporting: A new reporting dimension that lets you drill into conversations where Procedures failed, so you can diagnose and fix.
Version history with rollback: Track every change, compare versions, roll back if needed.
Data connector health monitoring: See at a glance if your integrations are healthy, degraded, or failing.
Optional data connector parameters: Fin only asks customers for information when it’s actually needed, instead of prompting for every field.
Email Simulation support: Test how your Procedures behave across chat and email before going live.
Agent in the Loop (Beta) unlocks the next tranche of automation. Even with Procedures, two things hold teams back from automating their most complex queries: missing integrations and policies that require a human sign-off on sensitive decisions.
“Agent in the Loop” is built for both. Need Fin to check your internal admin tools but haven’t built a data connector yet? Put a human checkpoint at that step. Fin handles the conversation, gathers context, and pauses, surfacing a structured summary for a human agent to verify or act, then resumes. You get automation on the 80% that doesn’t need the integration.
For compliance – identity verification, high-value refunds – Fin does the legwork, a human makes the final call and then hands it back to Fin. This works natively in the Intercom Inbox and via Slack. Some competitors don’t have an inbox-native variant at all, meaning humans need to leave their primary workspace to review AI actions.
Procedures are also built to let you collaborate with all your teammates – both human agents and AI Agents. Fin can work with them directly inside a Procedure, using APIs and webhooks to loop in another teammate mid-flow, hand off context, and pick back up once they’re done.
Making it easier, faster. Procedures is already self-serve, but the next step is making Procedure creation, testing, and maintenance significantly more streamlined and easy to do, with less manual editing and more AI-assisted building and debugging. There’s a lot coming in this space over the next few months – and it aligns perfectly with a retrieval-first pipeline and stronger governance at scale.
The hardest percentages matter the most. The biggest unlock for your automation rate won’t be answering more FAQs, it will be handling the complex, multi-step queries that consume your team’s time and define what customers remember about their experience with you.
That means working with an Agent that goes beyond answering questions and executes processes. A product your team owns and configures, not a service you buy and hope gets maintained. And a platform where every improvement compounds across every customer. That’s Procedures. Available now, for everyone.
Every product leader I know wrestles with the same question: how fast is fast enough when it comes to shipping? Over the years, I’ve learned that deployment frequency isn’t just a DevOps vanity metric—it’s a direct lever on customer value, risk, and competitive advantage.
When I talk about deployment frequency, I mean how often a team puts code into production, per service or product, in a given time period. It sits alongside lead time for changes, change failure rate, and mean time to recovery (MTTR) as part of the DORA metrics—together, they tell a coherent story about delivery performance and reliability.
If you’re looking for a compass, here’s how I calibrate expectations. Elite teams deploy on demand—often multiple times per day—because they’ve engineered safety into their CI/CD pipeline and decoupled deploy from release. High-performing teams comfortably ship daily to weekly. Medium performers land in the weekly-to-monthly range. These bands aren’t moral judgments; they’re context-aware guideposts. The goal isn’t to copy someone else’s speed, but to reach the fastest sustainable cadence your business, architecture, and risk profile can support.
So what does “fast enough” look like in practice? It depends on your product’s blast radius, regulatory constraints, and architecture. Microservice-heavy platforms with strong automated testing, feature flags, and progressive delivery generally sustain higher cadences with lower risk. Monoliths and highly coupled systems can still move quickly, but they need disciplined trunk-based development, robust test pyramids, and strong release controls to avoid brittle deployments.
At HighLevel, we’ve moved products from a cautious weekly train to safe daily (and eventually on-demand) deploys without increasing incident volume. The breakthrough wasn’t a single tool—it was a system: smaller batch sizes, automated tests that actually fail when they should, immutable artifacts, canary releases, and feature flags that decouple deployment from exposure. The result was faster learning loops, fewer late surprises, and more predictable delivery.
If you’re not measuring deployment frequency yet, start simple. Instrument your CI/CD pipeline or GitOps tooling to count production deployments by service each day. Normalize for rollbacks and re-deploys to avoid inflating the metric. Visualize by team and product area so you can spot bottlenecks and trend improvements over time. Pair it with change failure rate and MTTR to ensure you’re not trading speed for stability.
Once you’ve got a baseline, focus on the levers that actually move the needle. Reduce batch size by merging smaller, well-scoped changes. Embrace trunk-based development to minimize long-lived branches. Accelerate feedback with fast, reliable unit and integration tests, contract testing for services, and ephemeral environments for preview. Use feature flags to control exposure, and progressive delivery (canary, blue-green) to verify in production safely. Automate change approvals where policy allows, and replace heavyweight gates with observable, auditable pipelines.
Watch out for common anti-patterns. Batching several unrelated features into a single deploy increases risk and slows learning. Heroic “release nights” mask systemic issues. Friday deploy bans are a smell; if you can’t safely deploy on Friday, you can’t safely deploy any day—invest in recovery speed and blast-radius controls instead. And never treat deployment frequency as a target in isolation; it’s only healthy when reliability improves or holds steady.
For strategy alignment, I tie deployment goals to outcomes, not outputs. If your objective is time-to-value or activation improvement, a higher cadence of small, measurable changes aligns perfectly. If your objective is stability for a major seasonal event, slow the cadence temporarily and increase release controls. The point is to let business outcomes set the tempo while engineering creates the conditions for safe speed.
Here’s a pragmatic 30-day plan I’ve used with teams: Week 1, baseline deployment frequency and map your current release process end-to-end. Week 2, choose two services and cut batch size in half while enabling feature flags for new code paths. Week 3, refactor the pipeline for faster test feedback and add canary or blue-green for one critical service. Week 4, publish a dashboard that shows deployment frequency alongside change failure rate and MTTR, and run a retrospective to decide the next bottleneck to remove.
Culturally, celebrate small, frequent, reversible changes. Reward teams for boring deploys, rapid recovery, and high-quality instrumentation. Build psychological safety around rollback and kill switches—confidence breeds cadence.
Track deployment frequency, optimize it, and watch delivery speed turn into a competitive edge. Explore how in this article!
Fast enough isn’t a number you copy; it’s a capability you build. When deployment frequency rises in tandem with reliability, you unlock faster learning, happier customers, and a durable advantage in your market.
Go hard early is more than a mantra—it’s a product strategy. When I study the most durable enterprise companies, I see the same pattern: you win by shipping fast, obsessing over the customer’s day-to-day pains, and delivering consumer-quality experiences to business buyers. That lens is exactly why Serval’s recent momentum caught my attention and why the lessons behind it matter for every product and IT leader building in AI.
Jake is the founder and CEO of Serval, an AI-driven IT automation and service management platform that just raised $47M in Series A funding this week. Before founding Serval, Jake spent over five years at Verkada, where he led multiple products from 0-1 and helped scale the company across hardware and software. His years at Verkada taught him that winning in enterprise means delivering consumer-quality experiences to business buyers — a lesson that shapes how Serval turns complex IT automation into something that feels magical.
From my vantage point, the most counterintuitive lesson here is the power of building “in existing categories.” Rather than inventing a new market, the better move can be to redefine expectations inside a known one—where buyers, budgets, and success criteria already exist. That’s how you compress sales cycles, build trust rapidly, and create a wedge for product-led growth without boiling the ocean.
Another playbook thread I admire: turning “hard mode” into a moat. The teams that lean into gnarly integrations, real workflow depth, and enterprise-grade reliability end up compounding an advantage that’s very hard for fast followers to copy. That mindset shows up in Serval’s platform strategy and, more importantly, in how they translate complex IT work into something that feels intuitive on day one and powerful on day 100.
Customer intimacy sits at the center of that strategy. The customer interview question that unlocked the IT buyer’s hidden pain points is the kind of move I try to operationalize across product trios and forward-deployed teams. When you ask not just, “What do you do?” but, “What do you do when everything breaks?” you surface the real constraints: shadow runbooks, brittle scripts, brittle processes, and the political friction that slows down response times. That’s where durable value—and competitive differentiation—lives.
How Serval’s automation builder uses AI to generate code-based workflows is a particularly smart architectural choice. Code-first doesn’t mean hard-to-use; it means source-controlled, interoperable, and shareable across teams—exactly what IT leaders want when automation moves from side project to system of record. Tie that to agentic orchestration and you get reliable automations with clear observability, safety rails, and the ability to scale without collapsing under edge cases.
I’m also a believer in redefining engineering and PM roles with forward-deployed engineers. When engineers partner directly with customers, discovery accelerates, prioritization sharpens, and product bet quality improves. You avoid ping-ponging requirements through layers, and you raise the hiring bar for true product creators who can think in outcomes, not just output.
Keeping the hiring bar high in an AI-native startup isn’t optional—it’s existential. The best teams screen for candidates who can reason from first principles, ship quickly with taste, and articulate the value proposition in plain language. The ultimate hiring litmus test is whether someone can improve the product on day one by clarifying a user journey, simplifying a workflow, or tightening a metric that actually matters.
There’s also Why there’s a “land grab” moment right now in enterprise AI. Incumbents are strong on breadth but often slow to re-architect for AI-native workflows. New entrants that show up with opinionated defaults, pragmatic security, and crisp buyer narratives can establish points of parity quickly while extending into true points of differentiation. That’s the window to seize—especially when building for mid-market and enterprise.
Here are the core themes I took away and how I translate them into practice across product roadmapping and sprint planning, product discovery, and go-to-market strategy.
Why building “in existing categories” can be more powerful than creating new ones. Use the market’s mental models, measure against known alternatives, and win by delivering a meaningfully better experience—not by forcing buyers to invent new procurement paths.
The lessons from Verkada that shaped Serval’s platform strategy. Treat UX polish as a strategic asset, make setup effortless, and let power users go deep without friction. Consumer-grade quality is not a veneer; it’s a trust accelerator in enterprise.
The customer interview question that unlocked the IT buyer’s hidden pain points. Go beyond happy-path discovery. Ask about the 3 a.m. moments, the panic buttons, and the messy handoffs—then design for those first.
How Serval’s automation builder uses AI to generate code-based workflows. Pair AI generation with reviewability, versioning, and safe rollbacks. Make it easy to see, test, and share what the agent is doing under the hood.
Redefining engineering and PM roles with forward-deployed engineers. Collapse feedback loops by putting builders where the problems are. It’s the fastest path to product-market fit lessons and real-world reliability.
Keeping the hiring bar high in an AI-native startup. Look for taste, speed, and ownership. Optimize for people who can both prototype with gen ai and ship production-hardened systems.
Why there’s a “land grab” moment right now in enterprise AI. Move quickly, but anchor on outcomes. Land with a wedge use case, expand with measurable value, and maintain clear points of parity while you deepen differentiation.
If you want to follow or explore the companies and leaders referenced, these links are a useful starting point.
This podcast on all platforms: https://review.firstround.com/podcast
References:
Alex McLeod: https://www.linkedin.com/in/alexmcleodio/
Clay: https://www.clay.com
Cloudflare: https://www.cloudflare.com
Cursor: https://cursor.sh
Filip Kaliszan: https://www.linkedin.com/in/kaliszan/
Hans Robertson: https://www.linkedin.com/in/hansrobertson
Linear: https://linear.app
Okta: https://www.okta.com
Rippling: https://www.rippling.com
Serval: https://www.serval.com/
ServiceNow: https://www.servicenow.com
Verkada: https://www.verkada.com
Workday: https://www.workday.com
Timestamps and topic highlights for easy navigation and deeper study:
(02:25) Lessons from holding different product roles
(07:29) Turning “hard mode” into a moat
(10:49) The early days of Serval
(12:59) Scratching the founder itch
(14:57) Unconventional interview techniques
(17:47) Solving core interview challenges
(21:10) Planning the early product roadmap
(23:03) The surprising power of patience
(26:12) Serval’s impressive technical advantage
(27:35) Disrupting legacy incumbents
(31:13) Building for mid-market and enterprise
(33:35) Serval’s enduring roadmap
(36:08) How to sell to an existing market
(39:16) The evolving role software plays
(43:55) Building for AI that didn’t exist yet
(49:49) Serval’s forward-deployed engineers
(58:31) The hybrid PM-GM
(1:00:27) “You can over-prioritize”
(1:02:48) The unexpected value of panic buttons
(1:04:50) What Serval looks for in new talent
(1:07:01) The ultimate hiring litmus test
(1:13:59) Building out Serval’s go-to-market function
(1:16:31) The evolving IT market in 2025
My bottom line: build where budgets already live, ship with uncompromising UX, embed engineers with customers, and hold the line on talent. Do that, and you won’t just keep up with the enterprise AI “land grab”—you’ll define the standard others have to meet.
I’ve led and observed AI initiatives across fast-moving product organizations, and one pattern is unmistakable: “The AI revolution needs a departmental leader.” When that leader is unclear, pilots stall, risk mounts, and value gets trapped in proof-of-concept purgatory. When it’s clear, AI moves from demos to durable outcomes.
In my experience, IT is uniquely positioned to play that leadership role. IT sits at the nexus of data, identity, security, and infrastructure—exactly where scalable AI capabilities live. IT also has the vantage point to connect use cases across teams, manage risk, and operationalize change without derailing core systems.
Put simply, this is the promise: “Learn the key reasons why IT teams are uniquely positioned to be the strategic leaders of your company’s AI projects.” The reasons are pragmatic—access to systems of record, stewardship of data governance, ownership of integration patterns, and accountability for reliability and compliance—yet the impact is strategic.
Here’s how I frame the operating model. IT provides strategic leadership and platform stewardship; Product owns the outcomes; Engineering delivers services and integrations; Security and Legal codify guardrails; and Finance supports cost modeling. We establish tight collaboration through product trios (Product, Design, Engineering) that plug into an IT-led AI platform, enabling empowered product teams to ship safely and quickly.
Governance turns intent into repeatable action. I use outcomes vs output OKRs to force clarity on value, pair them with lightweight QBR cadences for course correction, and require architecture reviews that cover model/data governance, observability, privacy, and vendor risk. This ensures we can scale gen ai without surprise failures or compliance gaps.
On the delivery side, forward deployed engineers embedded with business units accelerate discovery and reduce translation loss. We leverage gen ai for product prototyping to validate desirability and feasibility early, then harden solutions on our shared AI platform. This keeps experimentation fast while maintaining an enterprise-grade backbone.
Roadmapping balances ambition with throughput. I tie product roadmapping and sprint planning to value streams, not just features, and I make stakeholder management explicit—especially with customer support, finance, and operations—so we design for adoption. For example, a customer support ai strategy isn’t a chatbot alone; it’s an outcome-driven service redesign, with training, playbooks, and measurable deflection and CSAT targets.
Success demands the right metrics. Beyond typical velocity measures, I track time-to-first-value, model quality and drift, cost-to-serve, and risk posture. These roll into OKRs that link frontline improvements (e.g., resolution time) to enterprise outcomes (e.g., gross margin, retention), giving executives confidence and teams a clear definition of done.
If you lead IT, this is your moment to step into strategic ownership and elevate AI from scattered experiments to a coherent platform. If you lead Product, partner with IT to align discovery, outcomes, and guardrails so empowered teams can move fast and responsibly. Together, we can turn AI from a buzzword into a durable advantage.
I’ve been revisiting the hard-won lessons behind durable product companies, and Eric Berg’s journey is a masterclass. Eric Berg is the CEO of Fauna, which is an adaptive operational database platform. In joining Fauna as its CEO in the summer of 2020, he brought a wealth of experience as a product leader. Most recently, he was the Chief Product Officer at Okta, scaling the company from 10 employees and zero customers to its eventual IPO in 2017. He started his career in product at Intel, working under the legendary Andy Grove, as well as a five-year stint as a product leader at Microsoft.
From a product management leadership lens, the earliest chapters at Okta are a blueprint for zero to one B2B marketing and founder-led GTM. I break down his early go-to-market lessons and the keys to honing in on an ICP to get Okta off the ground, highlighting how tight product discovery, crisp problem statements, and ruthless prioritization turn ambiguity into product-market fit.
What stands out is the often-maligned “messy middle” — the stretch when traction exists but entropy expands. Eric’s moves on “moving upmarket” and evolving a “pricing and packaging model” are reminders that, when done well, takes a company to new heights. For SaaS pricing, I lean on value metrics tied to critical jobs-to-be-done, clear guardrails for discounting, and a win–loss feedback loop owned jointly by product and sales.
We then switch gears to team building and company building. The cultural patterns that stick with me: hire “folks up and down the org chart with the right ego to talent ratio” and operationalize a “disagree and commit” value so it’s not just a long-forgotten team motto. Practically, that means defining decision types (one-way vs. two-way doors), naming a DRI and approver for every call, time-boxing debate, and documenting the rationale so execution never stalls.
On execution mechanics, I’ve found that outcomes vs output OKRs paired with QBRs vs OKRs alignment creates a healthy cadence from strategy to delivery. When you layer in forward deployed engineers and structured customer advisory boards, feedback cycles compress without sacrificing focus — a powerful pattern in both product roadmapping and sprint planning.
Finally, the perspective shifts “as he approaches one year of sitting in the CEO seat” underscore the difference between building products and building a business. Capital strategy, talent density, and narrative become first-class product surfaces. As a product creator, I translate this into designing org APIs, setting explicit burn-to-learn budgets, and treating pricing, packaging, and GTM as core parts of the product.
If you’re navigating product-market fit lessons, wrestling with “moving upmarket,” or recalibrating SaaS pricing, this playbook maps the trade-offs from 0 customers through the “messy middle” and beyond. It’s a grounded field guide for product folks and operators who want to scale with clarity, strengthen culture, and accelerate learning without losing the thread.
I recently sat down with Rick Song, the co-founder and CEO of Persona, a platform that enables companies to create the ideal identity verification experience for their customers. Before founding Persona in 2018, Rick was an engineer at Square for 5 years, and an early team member at Square Capital. As someone who leads product teams and thinks deeply about product-market fit and go-to-market, I was eager to unpack the 0 to 1 thinking behind Persona’s trajectory.
Rick is at an exciting inflection point in his journey of building from zero to one — just last week, Persona shared that they’ve raised a $50 million Series B round. The company plans to double the team this year to keep up with revenue that’s surged more than 10x and a customer base that’s grown to include big logos like Square, Postmates, and Gusto. For anyone operating in B2B SaaS, that’s the kind of signal you can’t ignore.
In our conversation, one theme stood out: Rick is somewhat obsessed with the idea of pre-mortems, or figuring out why things might not work out. From all the ways a candidate might fail, to why a customer won’t want a product, to how a commonly-used framework might not be a good fit, he brings this mindset to every aspect of running Persona. I share that instinct — when we anchor on “why it won’t work” early, we surface edge cases, stress-test assumptions, and prioritize outcomes over output. It’s a product discovery discipline that keeps teams honest and accelerates product-market fit lessons.
Rick also shared counterintuitive practices that resonated with my own founder-led GTM experiences. His engineers sell and cold-email prospects, and he doesn’t try to convince candidates that Persona is a company that will change the world. That may sound unconventional, but it’s exactly the clarity zero-to-one companies need: tight customer feedback loops, direct exposure to objections, and authentic hiring that screens for fit over hype. In my experience, these choices reduce handoffs, sharpen messaging, and create a culture that learns faster than the market moves.
There’s a broader leadership lesson here for product management: treat pre-mortems as a muscle, not a meeting. I apply this to hiring scorecards, roadmap bets, and go-to-market plays — explicitly listing failure modes, customer objections, and “anti-personas” who won’t buy. When we teach engineers to engage customers directly, we’re effectively building forward deployed engineers who carry context from discovery to delivery to launch, closing the feedback loop and improving zero to one B2B marketing execution.
For founders, engineering leaders, and hiring managers, the takeaways are practical: start with the “won’t,” design for objections, and let builders meet buyers early. Pair this with a clear definition of success metrics and a bias for candid, frequent iteration. The result is a stronger compass for product management leadership and a far more resilient go-to-market motion.
You can follow Rick on Twitter at @rickcsong and learn more about Persona at https://withpersona.com/
Building a highly technical enterprise product is as much about disciplined focus as it is about engineering excellence. When the stakes include mission-critical uptime, data integrity, and scale, the product decisions we make today compound for years. That’s why I’m constantly looking for patterns that help my team make fewer, better choices.
Recently, I sat down with Nate Stewart, CPO of Cockroach Labs, the creator of database product CockroachDB. Our conversation crystallized a number of principles that I’ve seen work in my own practice and that I believe every enterprise product leader should internalize.
First, focus starts with a brutally specific use case. Nate walked through how the Cockroach team narrowed the aperture on where their database would be irreplaceable, not just incrementally better. That clarity anchored the go-forward plan — which meant saying no to a lot of customers who didn’t align with the product roadmap. In my experience, this is the hardest muscle to build. I’ve found it helpful to articulate a one-sentence “non-negotiable” use case, followed by a short list of adjacent use cases we’ll explicitly defer.
Second, treat over-commitment as a structural risk. Nate dives into the tactical ways to avoid taking on too many customer commitments, which he calls tech debt for product teams. I track this debt explicitly: a ledger of promises, effort estimates, and the strategic rationale for each commitment. We cap the total “commitment points” per quarter, require a written business case for any exception, and sunset low-impact promises with transparent communication. This keeps the roadmap credible and prevents well-intentioned deals from silently hijacking strategy.
Design partnerships are the force multiplier in deeply technical categories — especially when working with conservative enterprise clients. Nate outlined different types of design partners and why you should have all of those represented in the early days of your startup. I map partners along two axes: ambition (visionary to conservative) and environment (startup to regulated enterprise). A healthy portfolio includes at least one of each: a visionary who pushes the frontier, a pragmatic mid-market partner who validates repeatability, and a regulated enterprise that stress-tests compliance, security, and operability.
To make design partnerships work, I rely on a simple operating contract: shared problem statement, measurable outcomes, and mutually agreed constraints. We align on exit criteria before we start, time-box pilots, and avoid bespoke code unless it is clearly on the critical path to the broader product-market fit. Executive alignment on both sides and weekly joint reviews keep momentum high and surprise low.
For product leaders stepping into a new role, nothing matters more than building a rock-solid partnership with a CEO as the first head of product. I’ve found three habits indispensable: a shared narrative (why we win), a living strategy doc (how we win), and a predictable cadence (when we decide). I send pre-reads before our 1:1, frame trade-offs in terms of risk and reversibility, and use disagree-and-commit to keep the organization moving. This creates trust, speeds decisions, and shields teams from thrash.
Finally, I’m intentional about how I solicit honest feedback across the executive team. I rotate a “red team” to stress-test critical bets, run brief anonymous pulses after major launches, and host cross-functional postmortems that focus on outcomes vs output. I also schedule regular skip-level interviews to uncover operational friction that might never surface in leadership meetings. These mechanisms create a continuous learning loop without slowing down the business.
In sum, the craft of enterprise product management lives at the intersection of clarity, constraint, and collaboration. Define a use case so sharp it excludes most opportunities. Manage customer promises like a portfolio of risk. Build a diverse, intentional set of design partners. And invest early in executive alignment and feedback channels that scale with your ambitions. That’s how we turn technical excellence into durable enterprise value.
I spend my days building and scaling B2B products, and Retool’s journey to $2M in ARR before launch is a masterclass in focus. It’s also a case study I revisit when coaching teams on developer evangelism and founder-led GTM.
Listening to David Hsu recount the early decisions made the strategy crisp: stay laser‑focused on developers, remove the boilerplate of internal tools, and earn trust with speed.
Retool, a low-code platform for developers building custom internal tools.
Today, Retool is valued at over $3 billion and has some of the biggest companies in the world building apps on its platform.
Early on, plenty of smart folks thought the idea for Retool would fail and that the product’s developer focus would sink the company. I’ve heard variations of this skepticism whenever a team doubles down on a specific persona—especially developers.
What struck me is the clarity around the target customer and the discipline to pursue language-market fit. When you get the words right for developers—their jobs-to-be-done, primitives, and constraints—you lower friction across product discovery, onboarding, and activation.
Equally instructive is how Retool nabbed its earliest customers (which includes Brex, DoorDash and a Fortune 500 BigCo) and the way the team prioritized creating incredibly tight feedback cycles with these early evangelists. That’s founder-led GTM at its best: sit with users, ship fast, instrument everything, and turn customer conversations into a roadmap.
On the surface, Retool’s path to product-market fit seems incredibly smooth. But as David tells it, there were plenty of bumps in the road — and he’s got tons of advice for early-stage founders that are finding their footing. I’ve lived those bumps, too; they’re signals to tighten the loop, not reasons to pivot away from your core user.
My takeaways for product leaders: start with developer empathy, not feature breadth. Use founder bandwidth to run high-frequency user sessions, shadow internal tool builds, and test copy until you hit language-market fit. Treat docs, templates, and examples as part of the product; they often outperform UI tweaks for time-to-value.
Operationally, stand up a lightweight, metrics-driven pipeline that connects discovery to delivery. I like a weekly cadence that pairs qualitative insights with activation, time-to-first-value, and expansion signals—classic product-market fit lessons that prevent local optimizations. When you see pull, lean into developer evangelism and zero to one B2B marketing, not paid acquisition.
If I were replicating this playbook today, I’d deploy a small, forward-deployed team to embed with design partners, capture real workflows, and ship improvements daily. Pair that with clear outcomes vs output OKRs so the team optimizes for customer outcomes, not just shipping velocity. That’s how you earn trust with developers and translate it into durable ARR.
Retool’s story reinforces a principle I teach often: conviction in the right user beats broad appeal every time. Focus wins, feedback compounds, and the market rewards teams that can turn skepticism into traction—especially when the users are developers.